



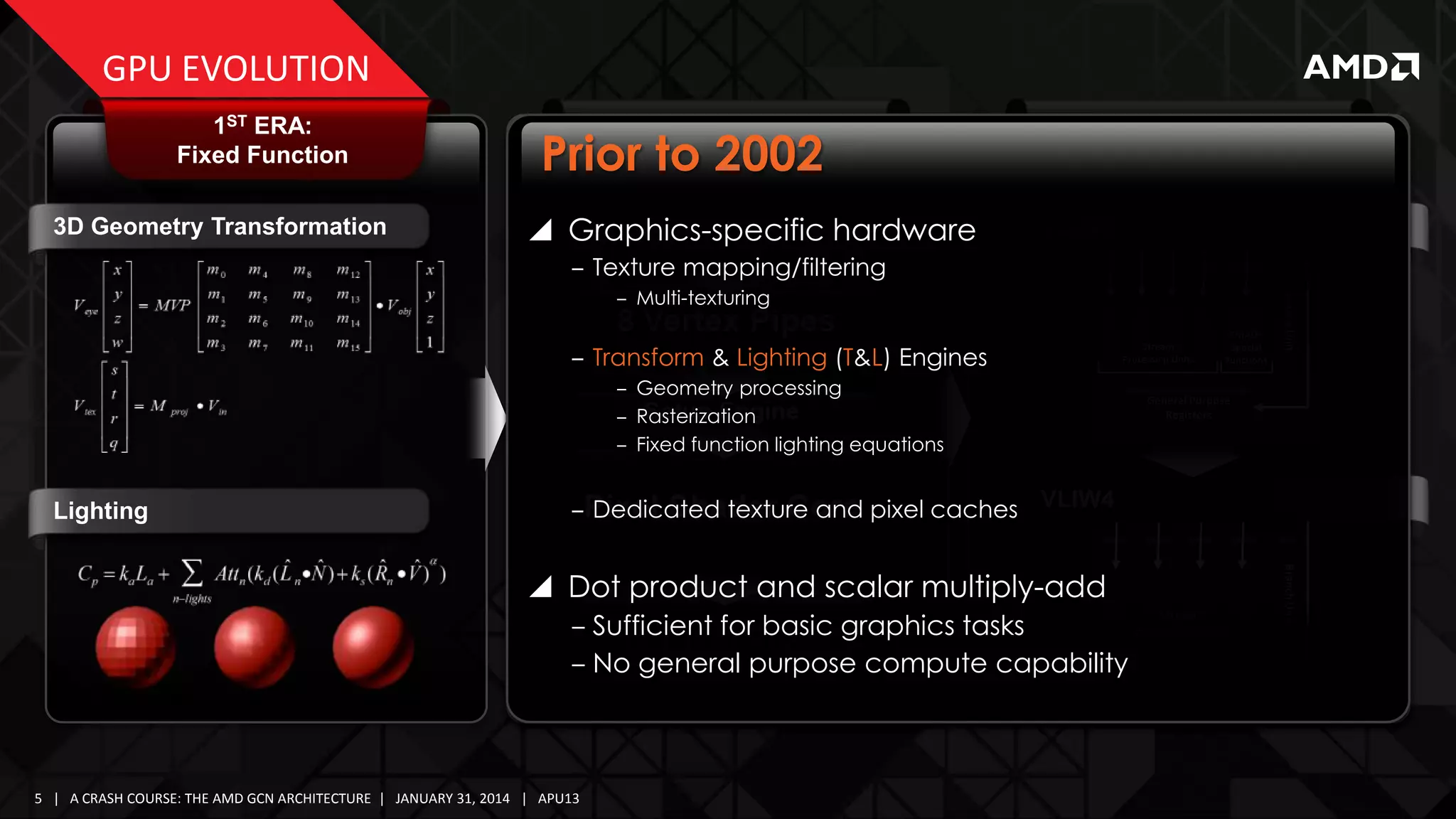

![GPU EVOLUTION
1ST ERA:
Fixed Function
2002-2006
3D Geometry Transformation
Graphics Programmability
– Direct3D 8/9, OpenGL 2.0
IEEE not required
Memory Interface
8 Vertex Pipes
Setup Engine
– NV 16-bit full-speed
–
Lighting NV 32-bit half-speed
Pixel Shader Core
7 | A CRASH COURSE: THE AMD GCN ARCHITECTURE | JANUARY 31, 2014 | APU13
Shader Models 1.0 - 2.0
VLIW5
‒ VS and PS are distinct
‒ Minimal Instruction Sets
‒ Limited Instruction Slots
‒ LimitedGeneral Purpose Lengths
Shader
Registers
‒ No DYNAMIC Flow Control
‒ No Looping Constructs
‒ VLIW4
No Vertex Texture Fetch
‒ No Bitwise Operators
‒ No Native Integer ALU
Stream
Processing Units
‒ […]
FMAD+
Special
Functions
Branch Unit
– Specialized shader units for
vertex & pixel processing
Added dedicated caches
The Rise of Shaders
Stream
Processing Units
Different precision per IHV
– ATI 24-bit full-speed
3RD ERA:
Graphics Parallel Core
Branch Unit
– Floating point processing
2ND ERA:
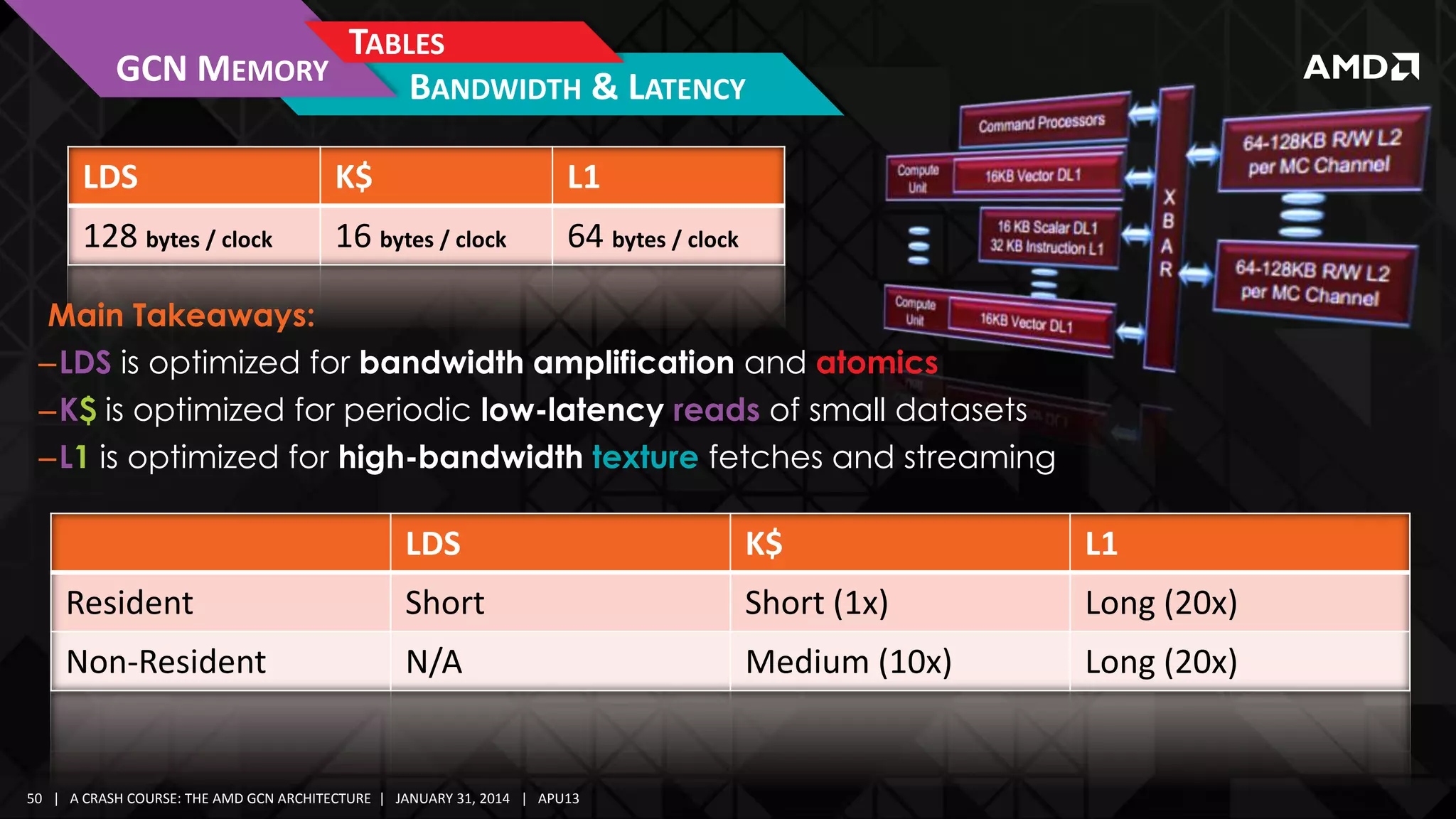
Simple Shaders
16 Pixel Pipes
General Purpose
Registers](https://image.slidesharecdn.com/gs-4106mah-finalfullversion-140131075645-phpapp01/75/GS-4106-The-AMD-GCN-Architecture-A-Crash-Course-by-Layla-Mah-7-2048.jpg)
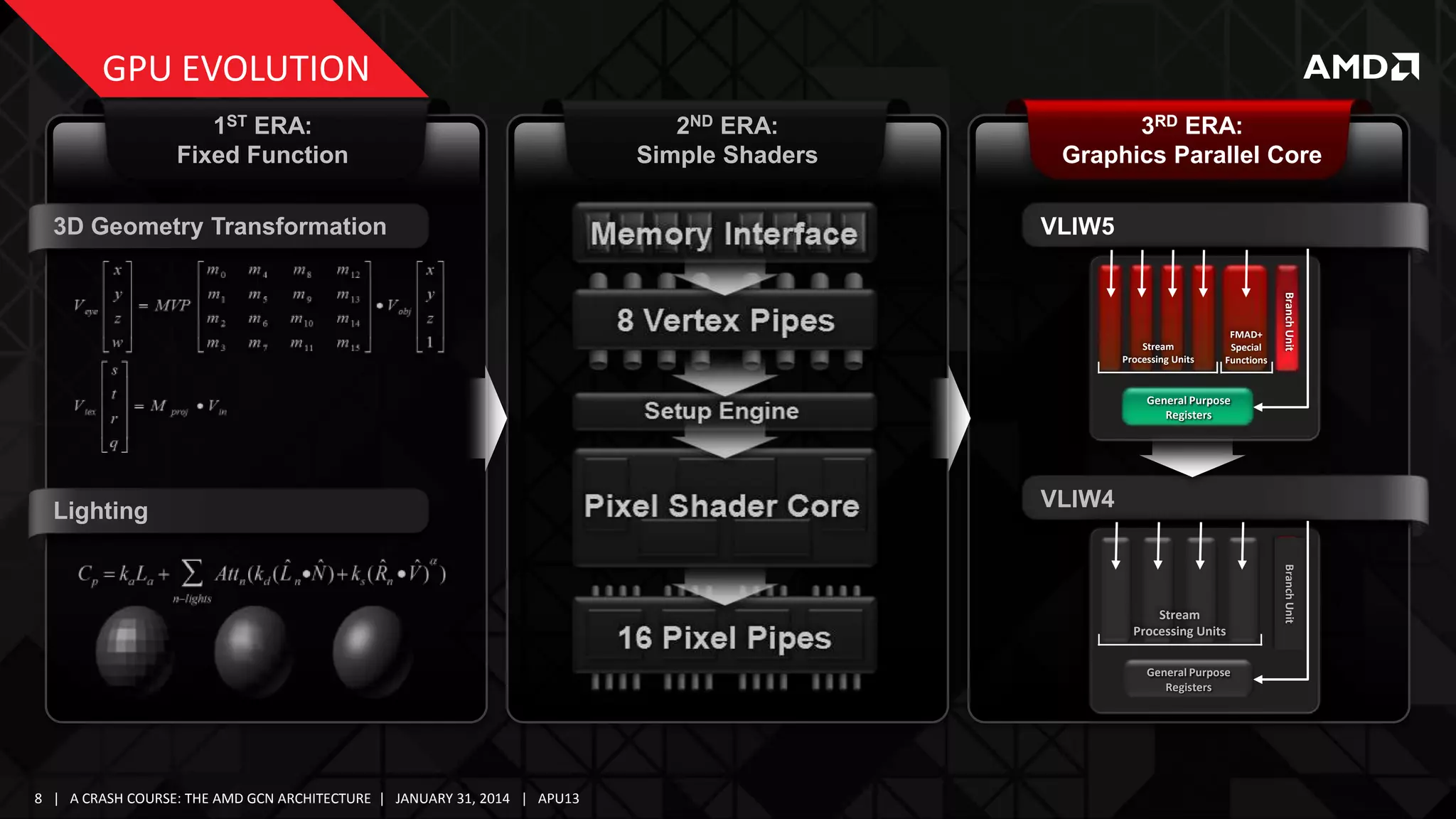










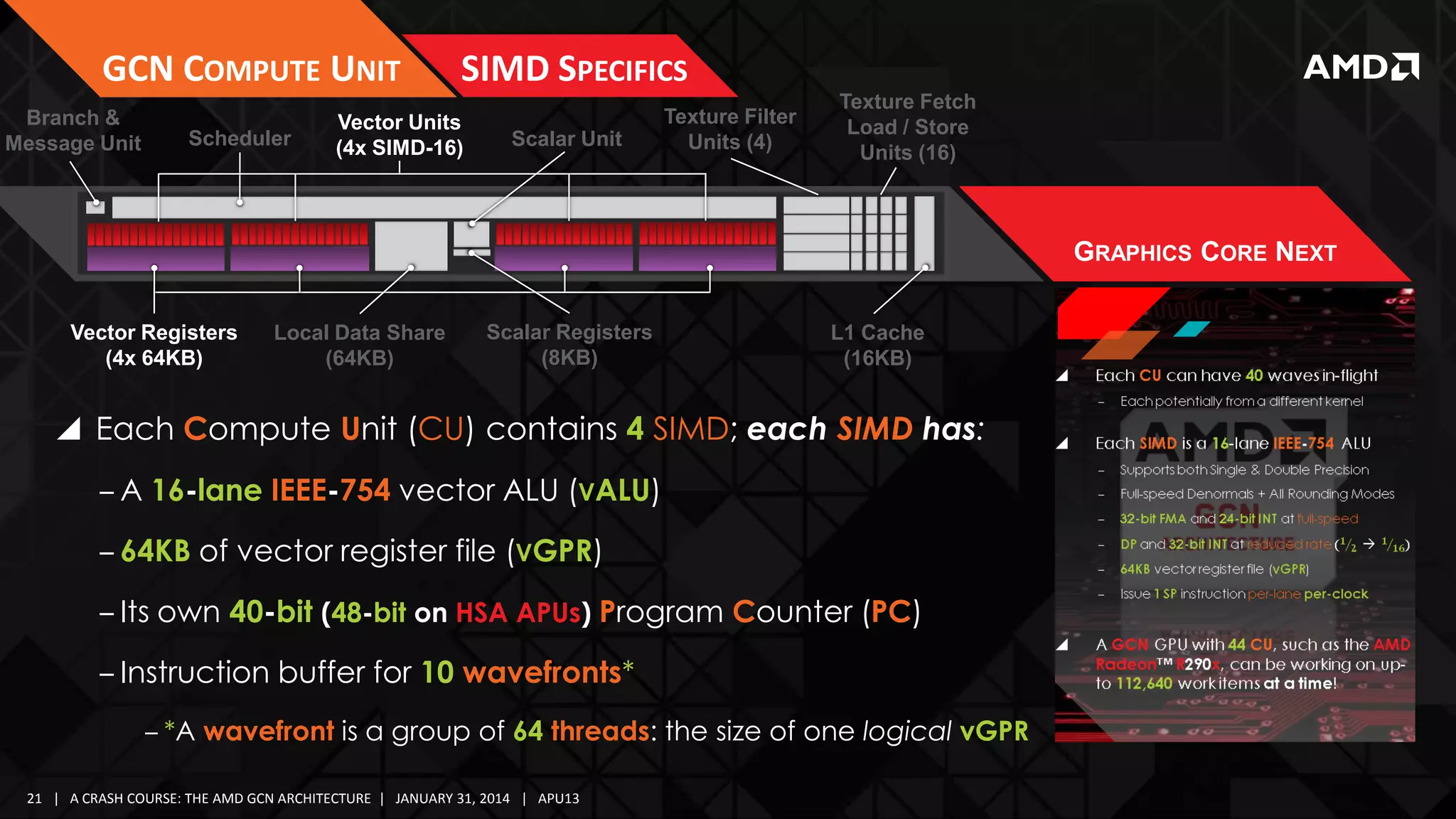
![GCN COMPUTE UNIT
SCALAR UNIT
LANE
0 1 2
SIMD 0
15
LANE
0 1 2
SIMD 1
15
SPECIFICS …
LANE
0 1 2
15
SIMD 2
LANE
0 1 2
15
Scalar Unit
SIMD 3
GCN Scalar Unit
Fully Programmable Scalar Unit replaces FF Branch Logic
Operations such as JMP [GPR] are now supported
Opens the door to e.g. virtual function calls
Has its own GPR pool and can execute normal ALU code
64-bit bitwise ops to mask thread execution
32-bit bitwise and integer arithmetic operations at full-speed
Potential to offload uniform code (Vector ALU Scalar ALU)
A GCN CU can dispatch 1 scalar op/clock
24 | A CRASH COURSE: THE AMD GCN ARCHITECTURE | JANUARY 31, 2014 | APU13](https://image.slidesharecdn.com/gs-4106mah-finalfullversion-140131075645-phpapp01/75/GS-4106-The-AMD-GCN-Architecture-A-Crash-Course-by-Layla-Mah-22-2048.jpg)

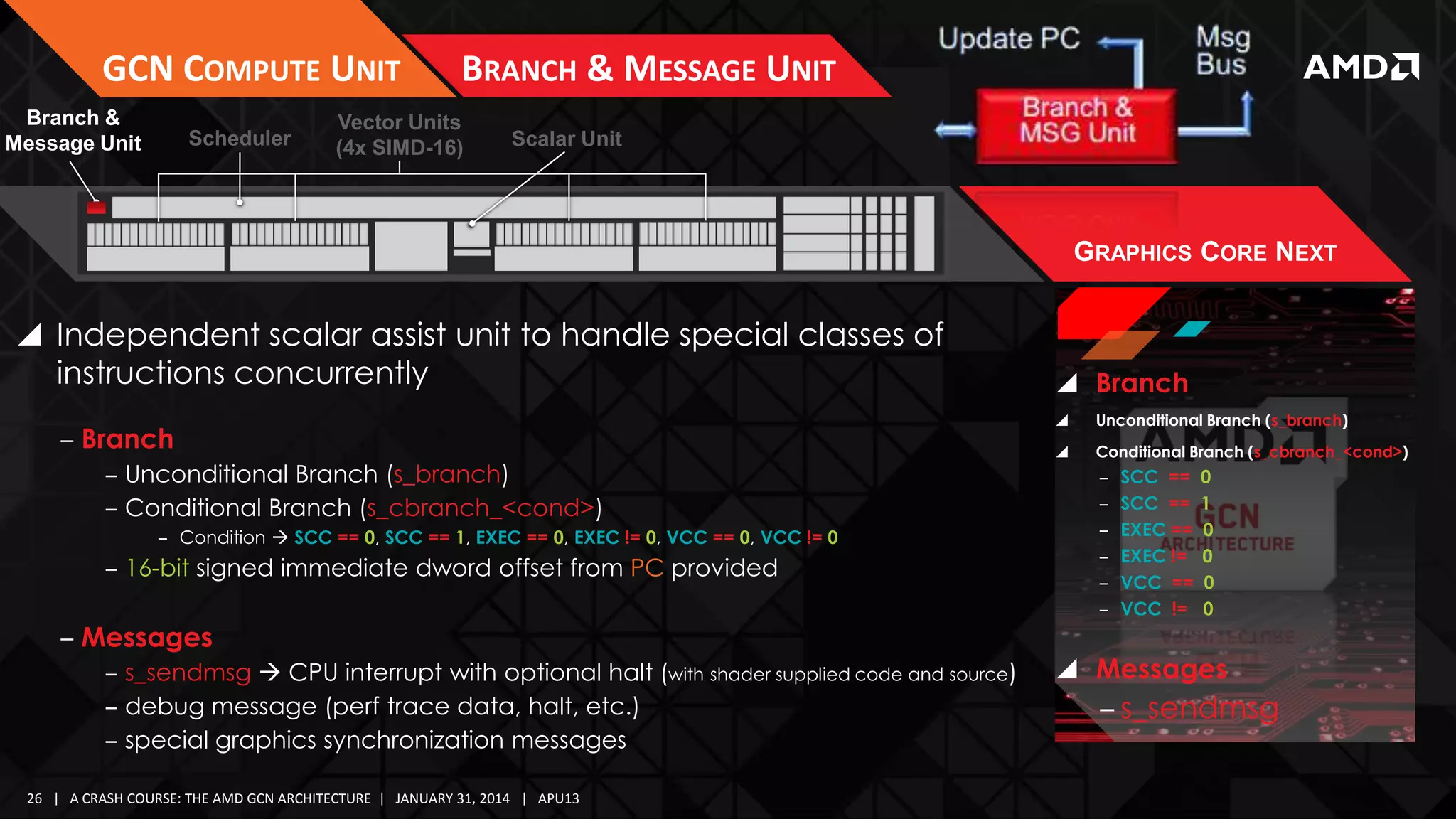

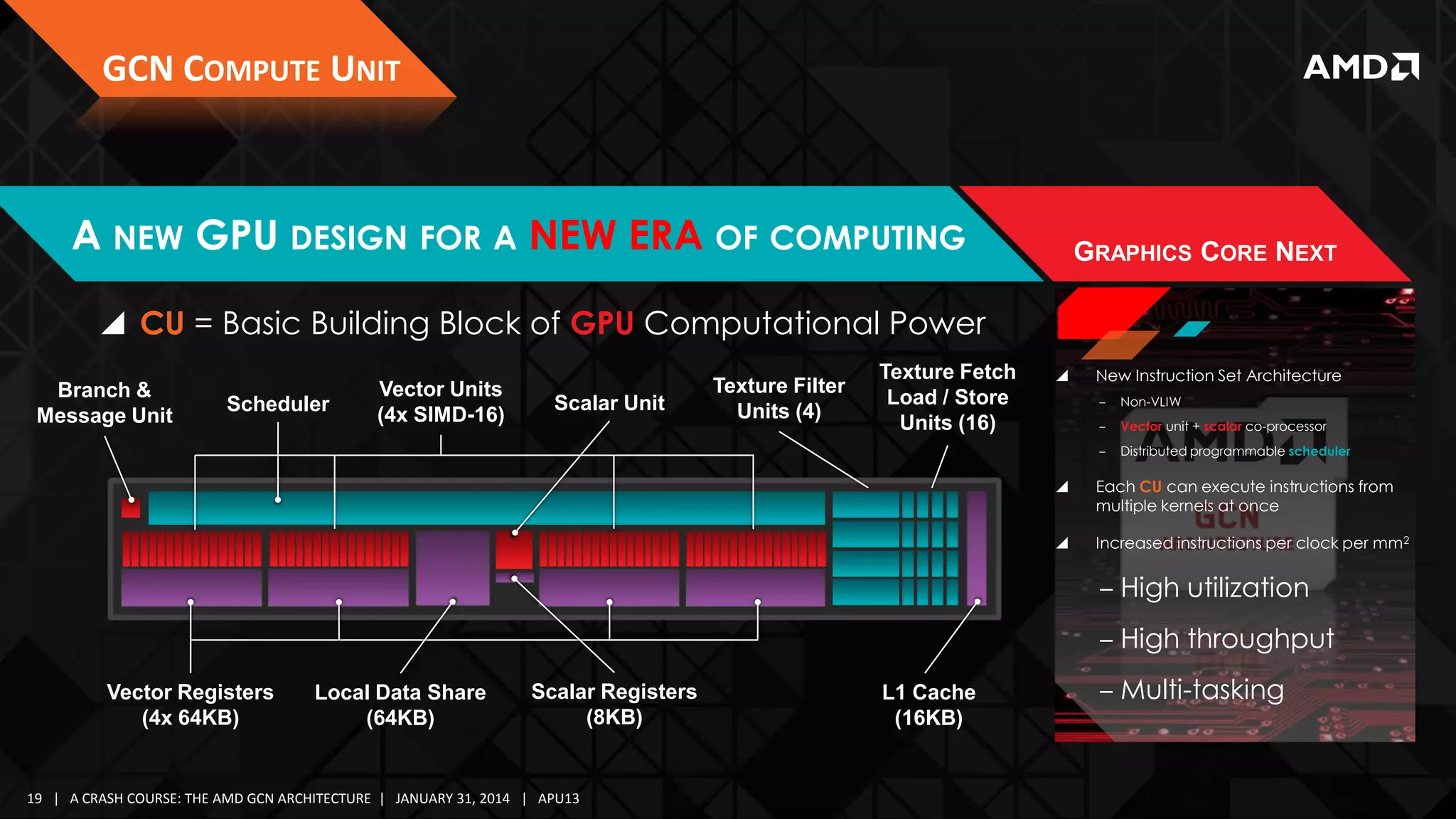
![GCN COMPUTE UNIT
Branch &
Message Unit
Scheduler
SCHEDULER SPECIFICS
Vector Units
(4x SIMD-16)
Scalar Unit
ARBITRATION & DECODE
Local Data Share
(64KB)
L1 Cache
(16KB)
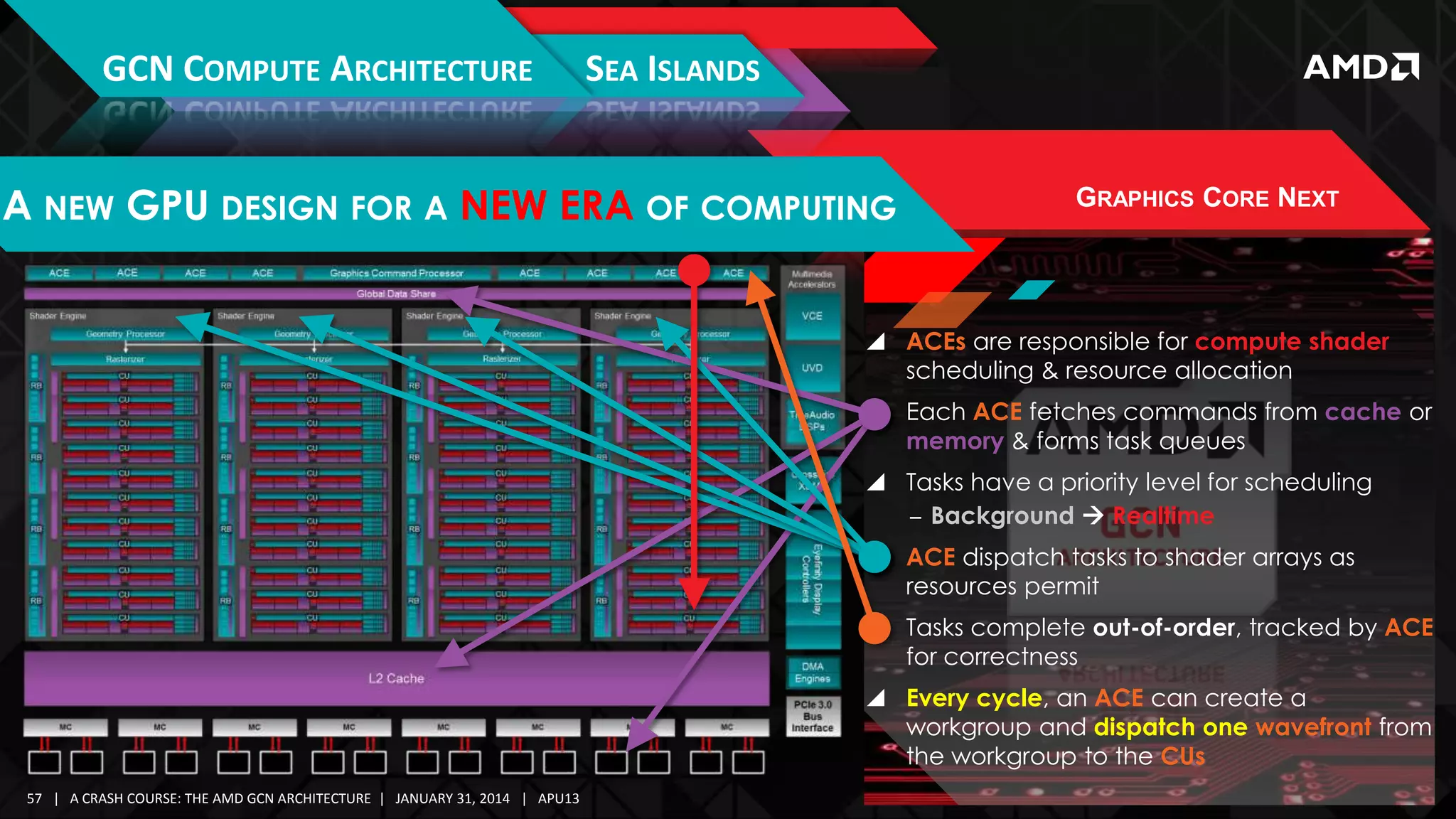
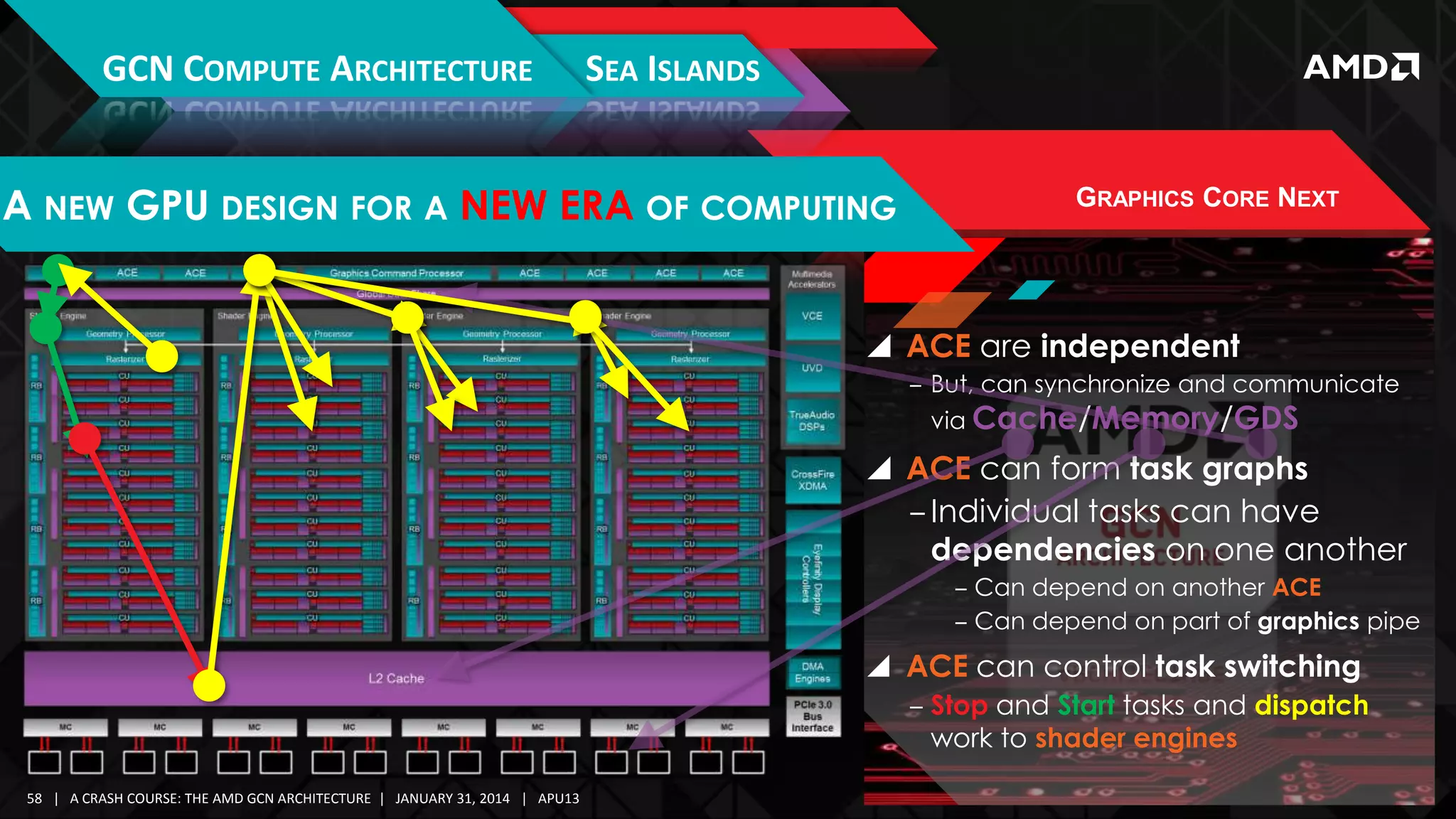
GRAPHICS CORE NEXT
CU is guaranteed to issue instructions for a wave sequentially
‒ Predication & control flow enables any single work-item a
unique execution path
For a CU, every clock, waves on 1 SIMD are considered for issue
‒ Round-Robin scheduling algorithm
Maximum
5 instructions per cycle
‒ Not including “internal” instructions
Instruction Types:
‒ 1 Vector Arithmetic Logic Unit (VALU)
‒ 1 Scalar ALU or Scalar Memory (SALU)|(SMEM)
‒ 1 Vector Memory (Read/Write/Atomic) (VMEM)
‒ 1 Branch/Message (e.g. s_branch, s_cbranch)
‒ 1 Local Data Share (LDS)
At most, 1 instruction from each category may be issued
At most, 1 instruction per wave may be issued
Theoretical maximum of 5 instructions per cycle per CU
29 | A CRASH COURSE: THE AMD GCN ARCHITECTURE | JANUARY 31, 2014 | APU13
‒ 1 Export or Global Data Share (GDS)
‒ 10 Special/Internal
(s_nop, s_sleep, s_waitcnt, s_barrier, s_setprio) –
[no functional unit]](https://image.slidesharecdn.com/gs-4106mah-finalfullversion-140131075645-phpapp01/75/GS-4106-The-AMD-GCN-Architecture-A-Crash-Course-by-Layla-Mah-27-2048.jpg)






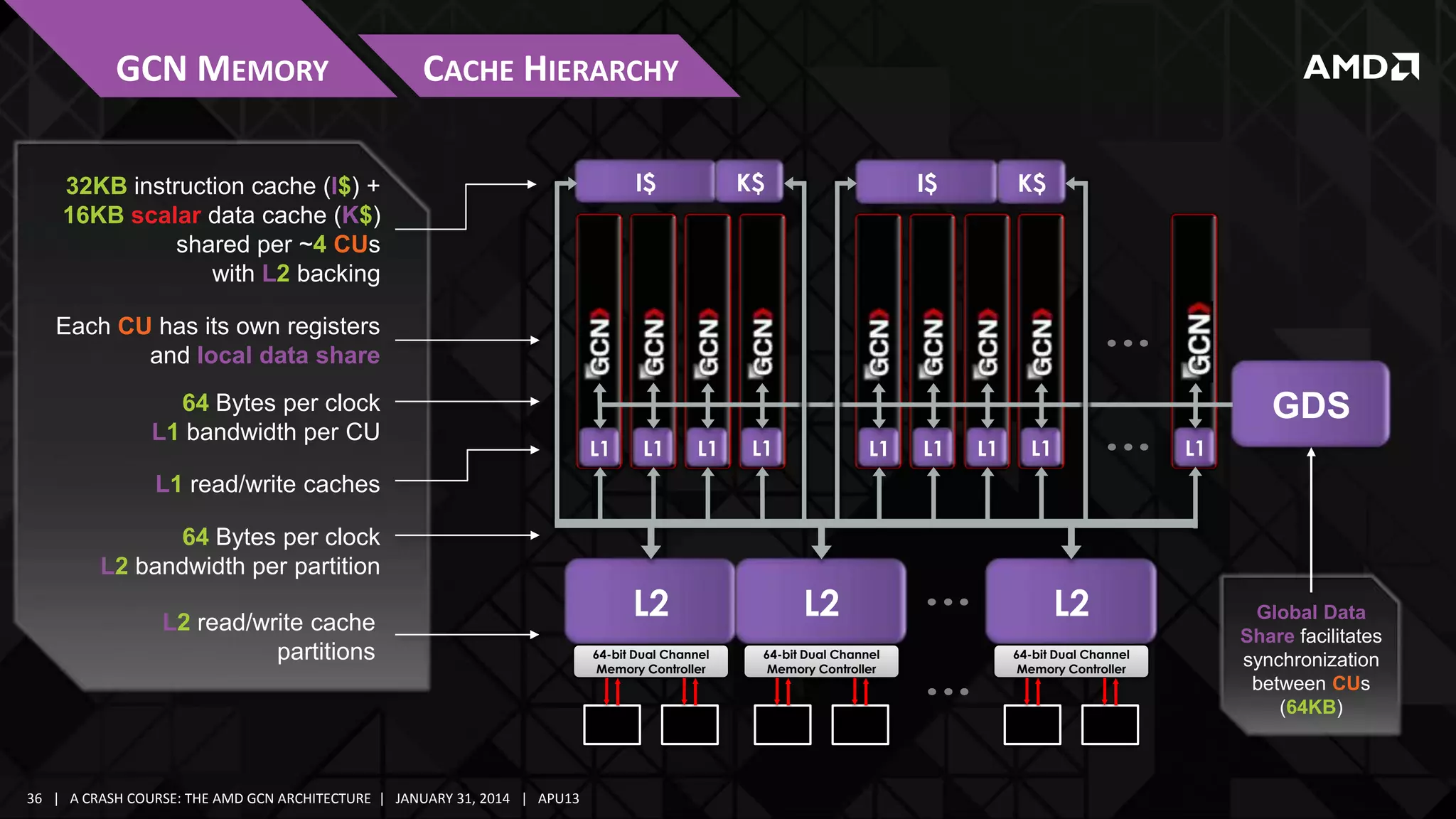



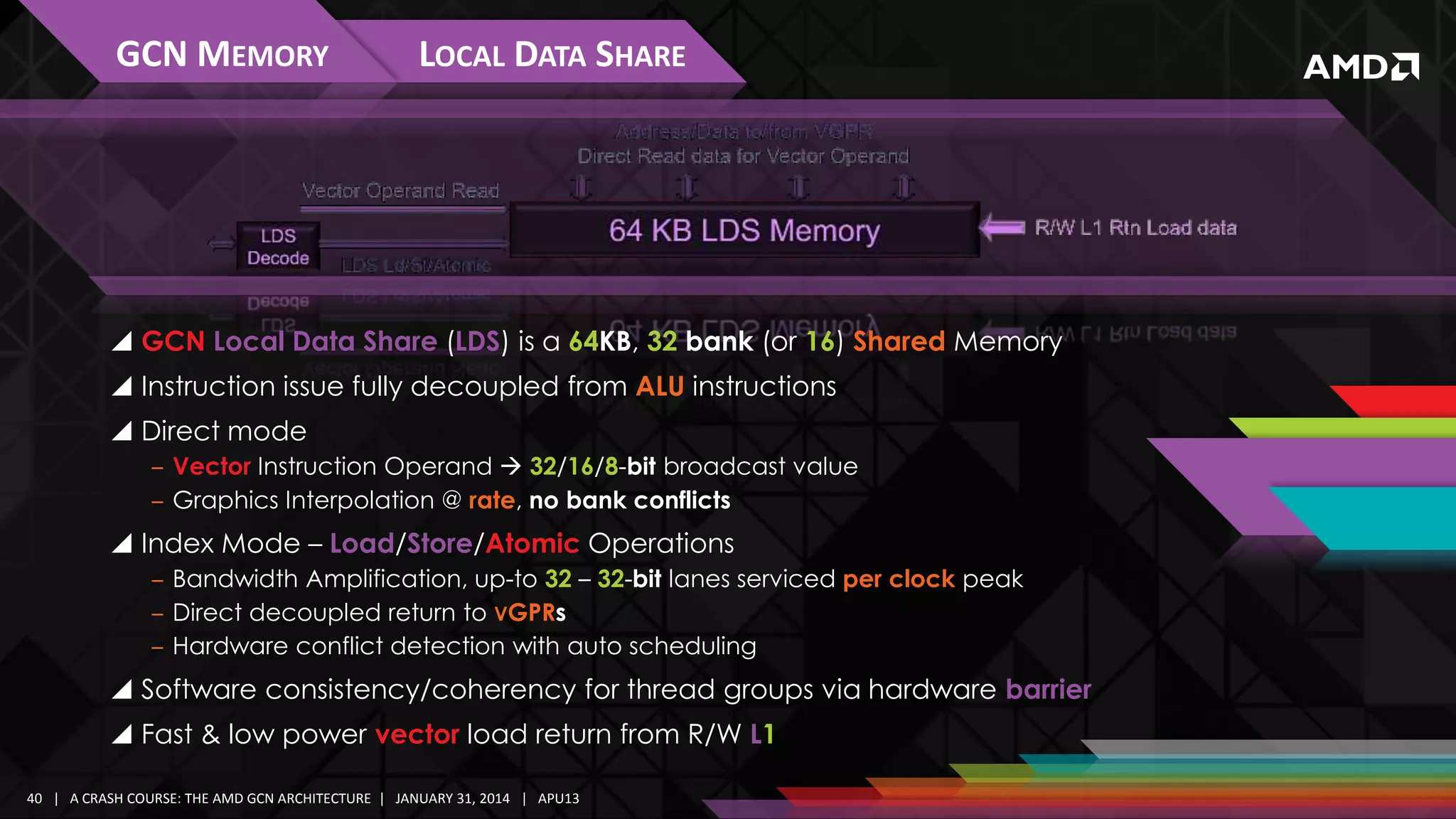

![GCN MEMORY
NEW MEMORY OPERATIONS
LOCAL DATA SHARE
Remote Atomic Ops with Shared Memory Dual-Source Operands
‒LDS[Dst] = LDS[addr0] op LDS[addr1];
‒ Fast remote reduction operations for arithmetic, logical, Min/Max
Read/Write/Conditional Exchange 96b/128b
32-bit FP Min/Max/Compare Swap
43 | A CRASH COURSE: THE AMD GCN ARCHITECTURE | JANUARY 31, 2014 | APU13](https://image.slidesharecdn.com/gs-4106mah-finalfullversion-140131075645-phpapp01/75/GS-4106-The-AMD-GCN-Architecture-A-Crash-Course-by-Layla-Mah-41-2048.jpg)













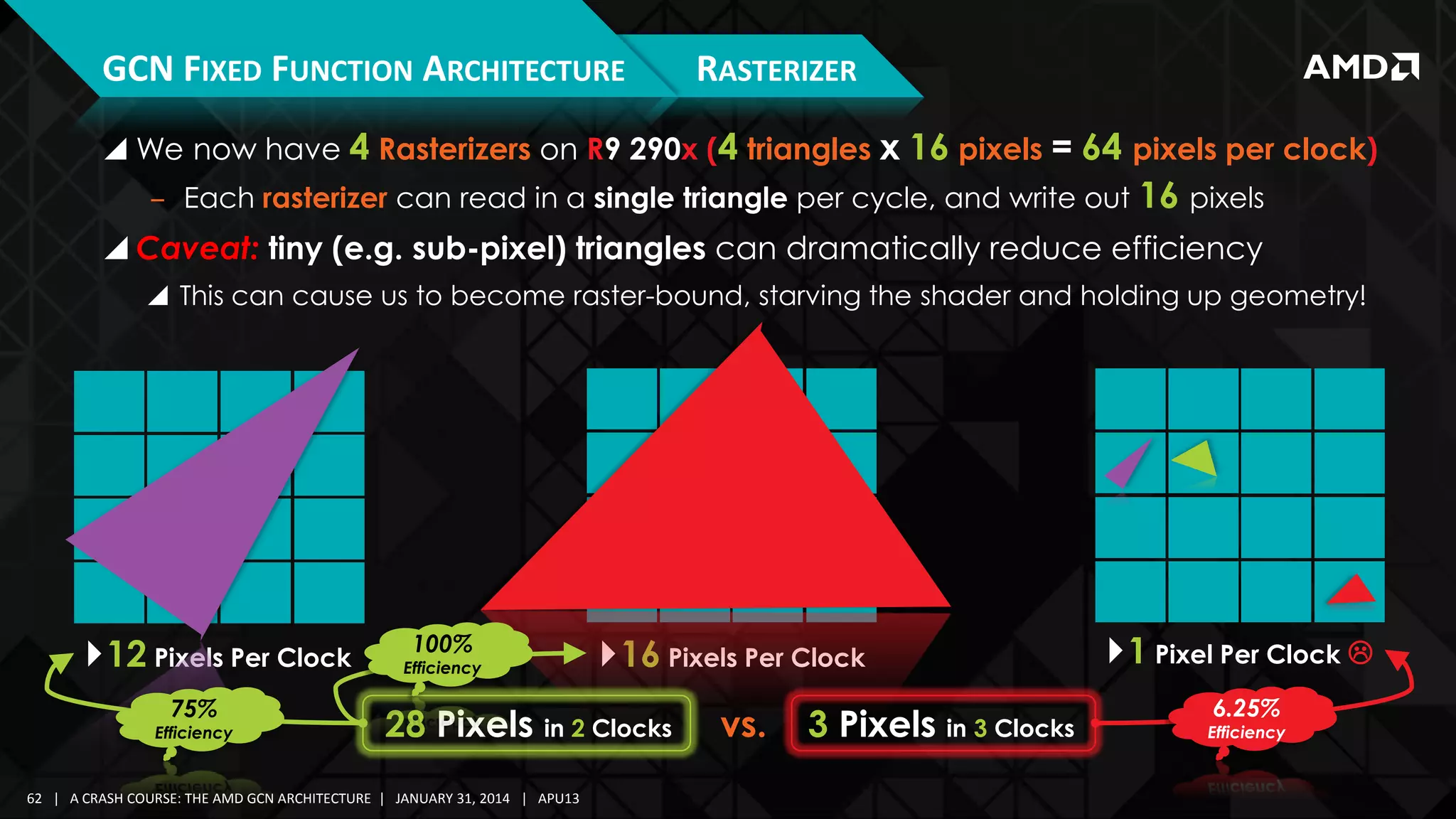

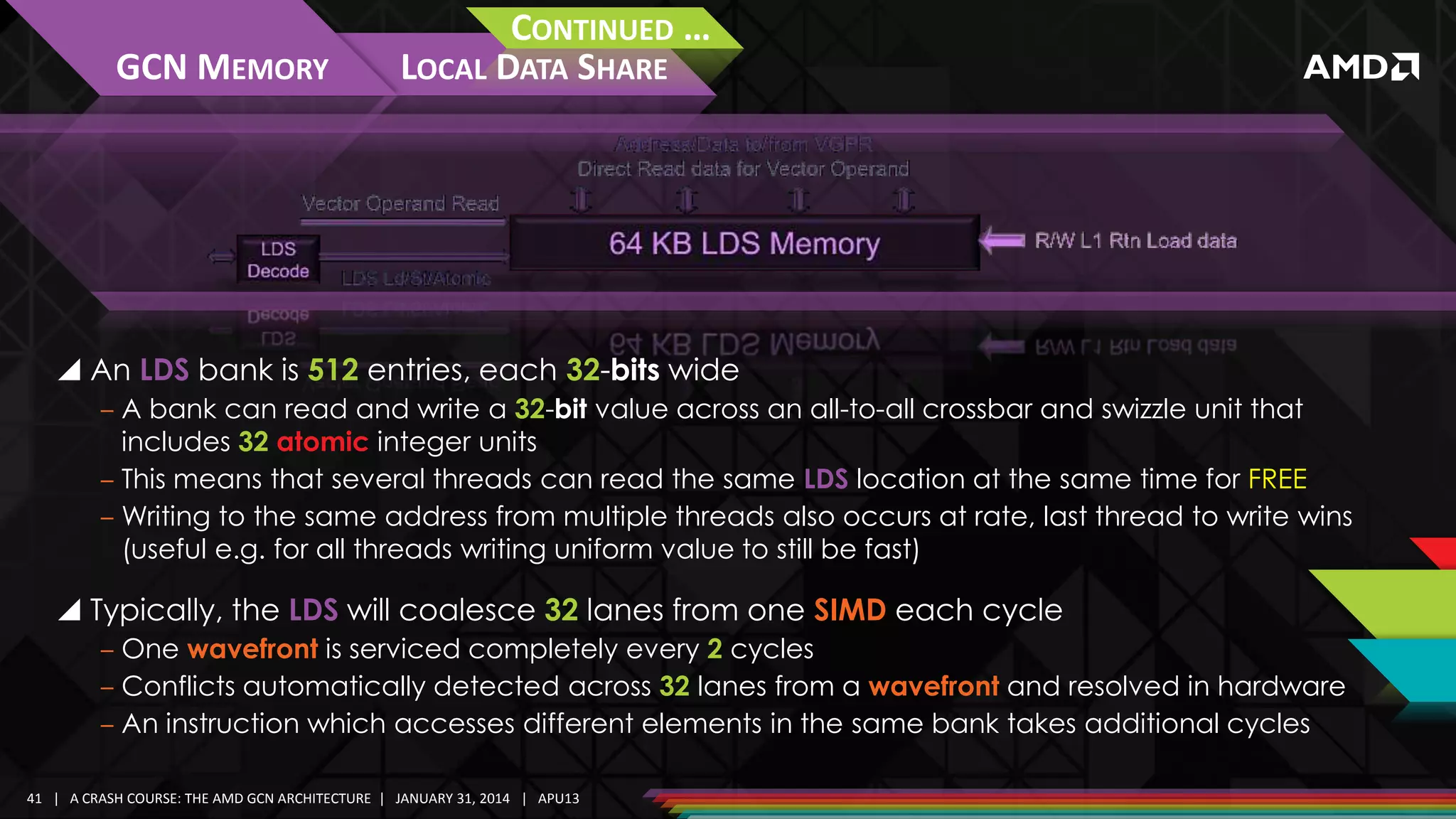
![GCN FIXED FUNCTION ARCHITECTURE
Over-Tessellation
Reduces shader efficiency
HS, DS and VS run many times
for each final image pixel
‒ Yet don’t contribute much
to final image quality
The graphics pipeline is not
designed for this abuse!
TESSELLATION + SHADING EFFICIENCY
Shading Passes Per-Pixel (Overshade)
8
7
6
5
4
3
2
1
Consider Alternatives:
‒ Parallax Occlusion Mapping
‒ […]
Image courtesy: Kayvon Fatahalian
“Evolving the Direct3D Pipeline for Real-time Micropolygon Rendering,”
From ACM SIGGRAPH 2010 course: “Beyond Programmable Shading II”
64 | A CRASH COURSE: THE AMD GCN ARCHITECTURE | JANUARY 31, 2014 | APU13](https://image.slidesharecdn.com/gs-4106mah-finalfullversion-140131075645-phpapp01/75/GS-4106-The-AMD-GCN-Architecture-A-Crash-Course-by-Layla-Mah-62-2048.jpg)
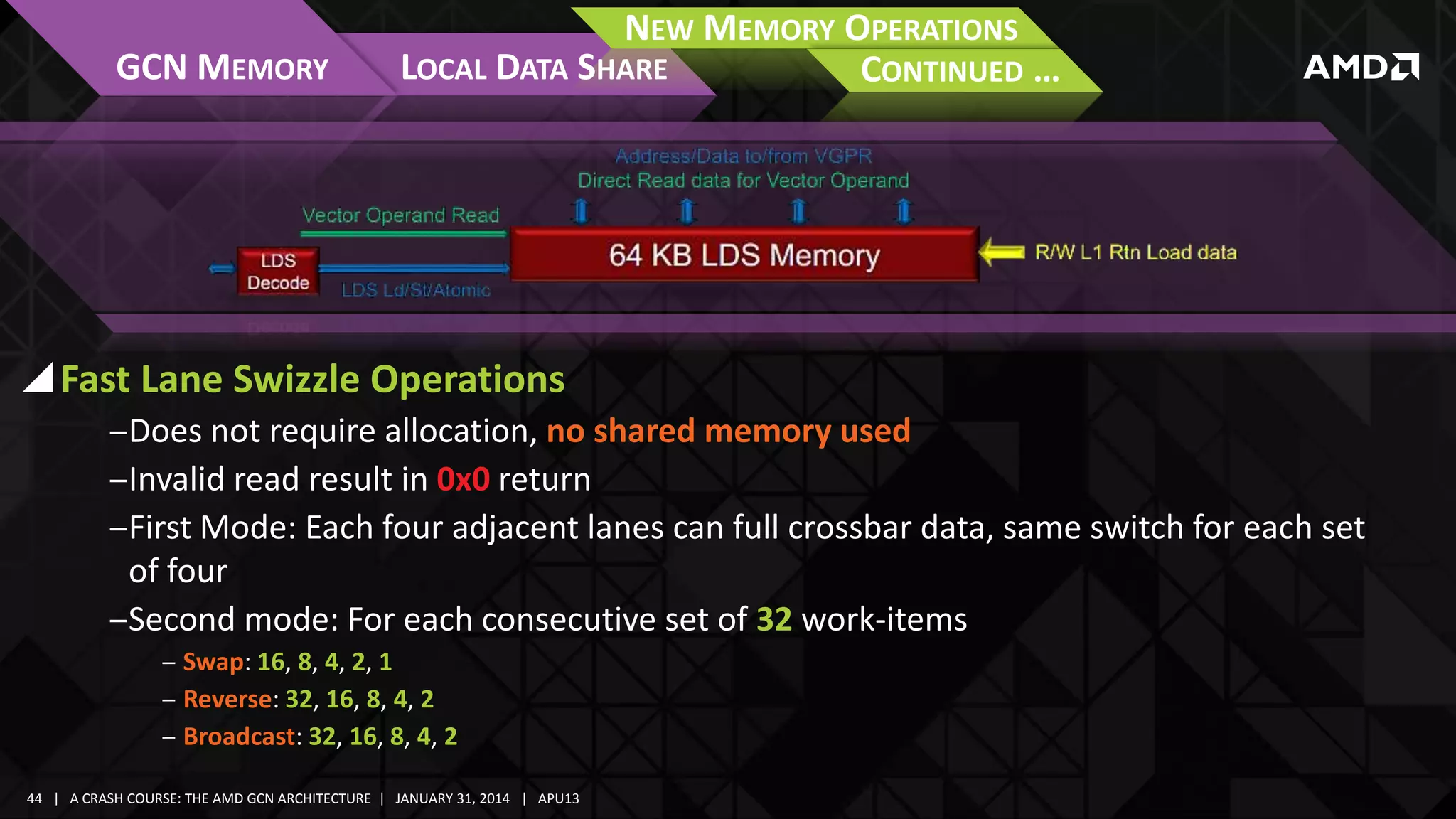
![GCN Tessellation – Best Practices
While performance is much improved, it is still a potential bottleneck!
‒ Produces a great deal of IO traffic, starving other parts of the pipeline
Best performance generlly achieved with tessellation factors less than 15!
Continue to
Optimize:
‒ Pre-triangulate
‒ Distance-adaptive
‒ Screen-space adaptive
‒ Orientation-adaptive
‒ Backface Culling
‒Frustum Culling
‒ […]
65 | A CRASH COURSE: THE AMD GCN ARCHITECTURE | JANUARY 31, 2014 | APU13
Tessellation OFF
ON](https://image.slidesharecdn.com/gs-4106mah-finalfullversion-140131075645-phpapp01/75/GS-4106-The-AMD-GCN-Architecture-A-Crash-Course-by-Layla-Mah-63-2048.jpg)

















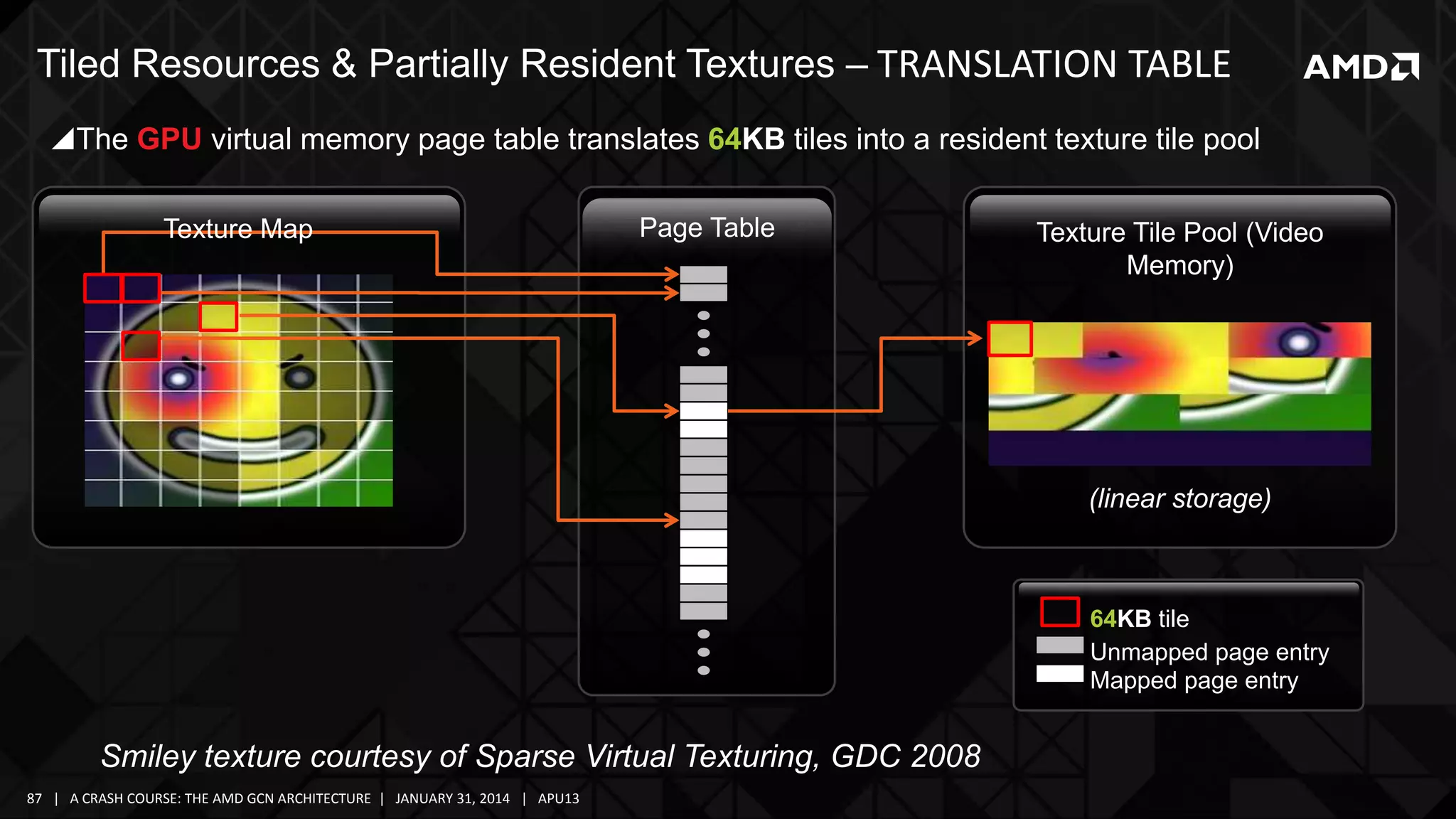
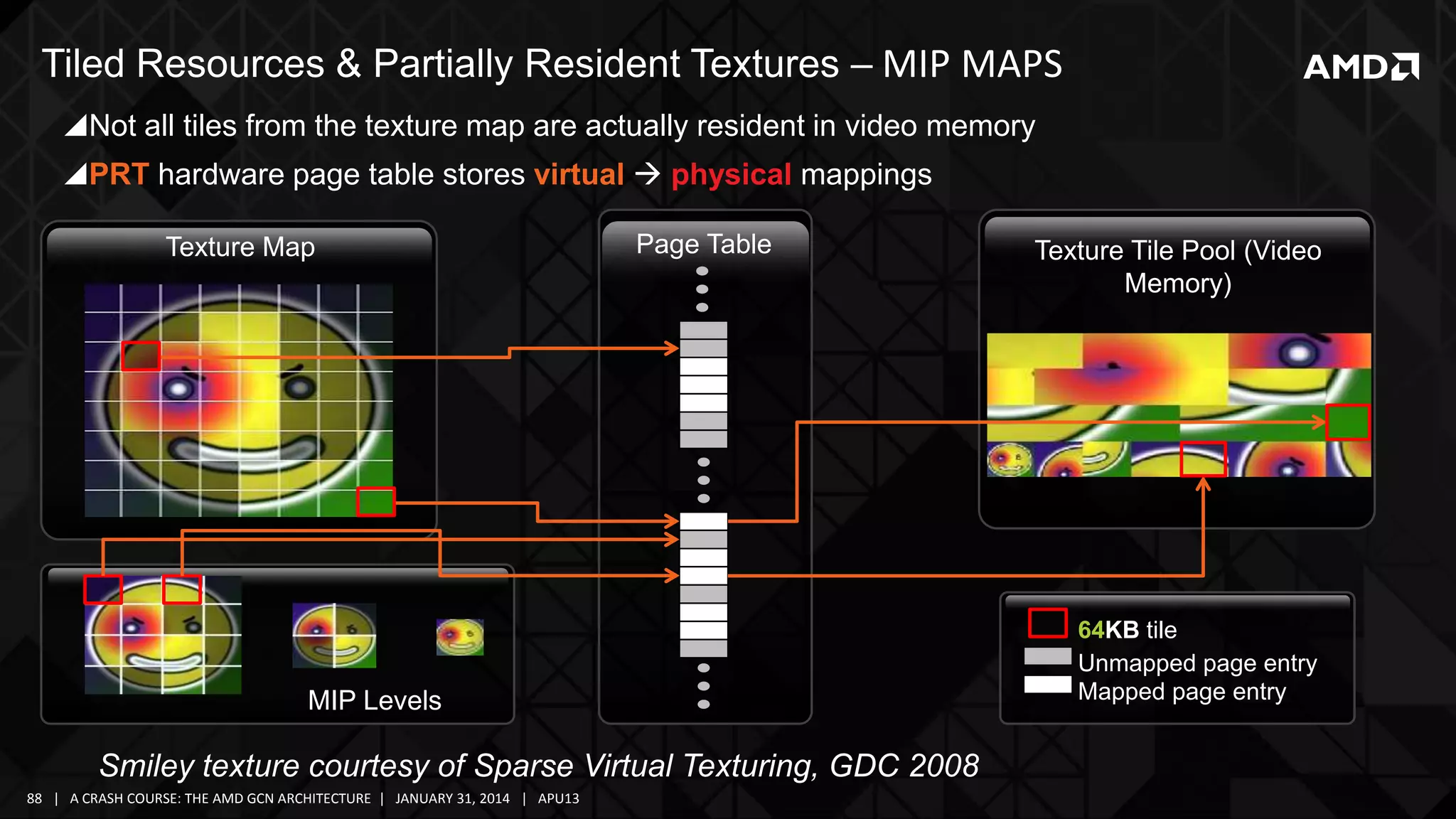





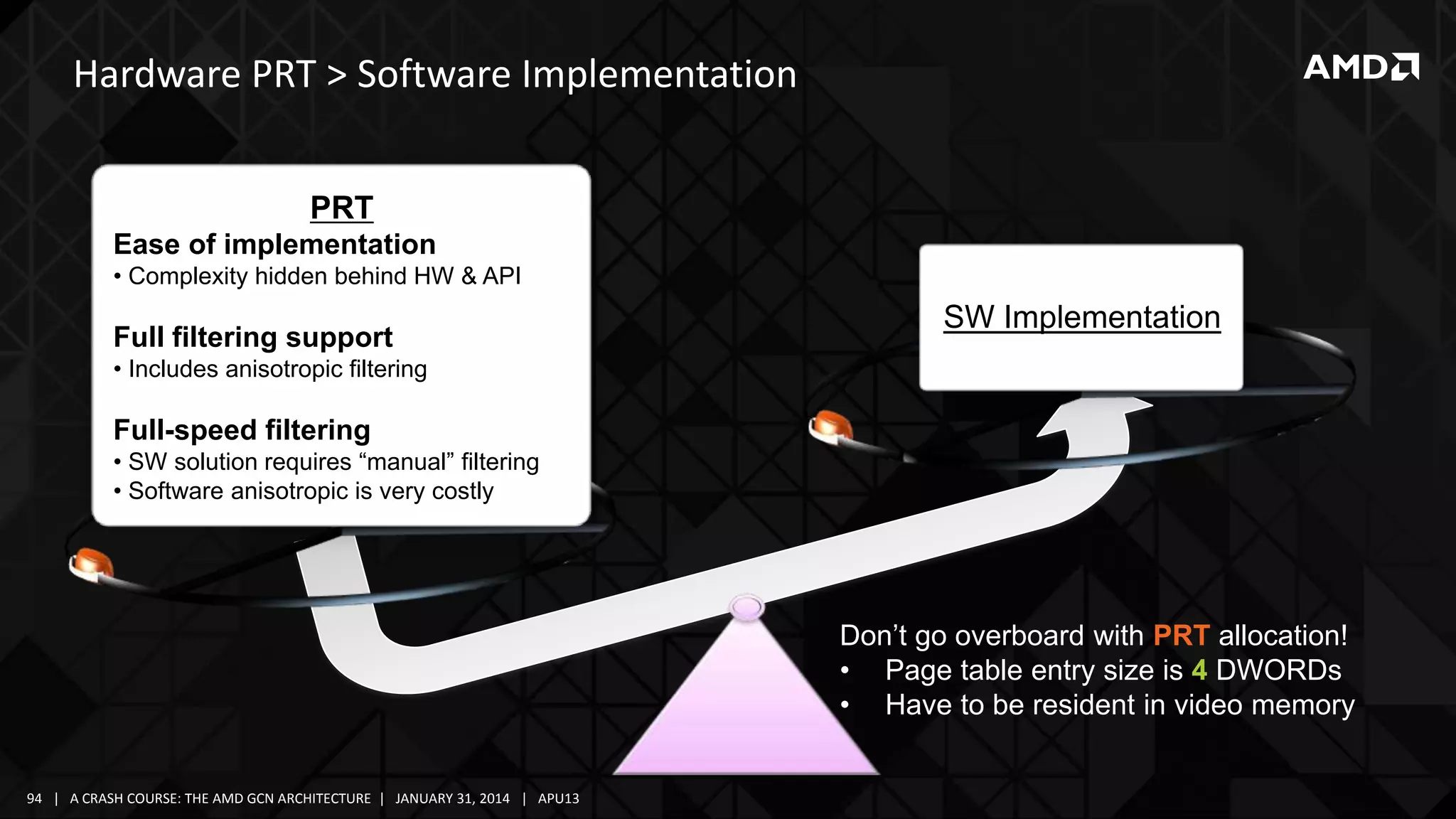


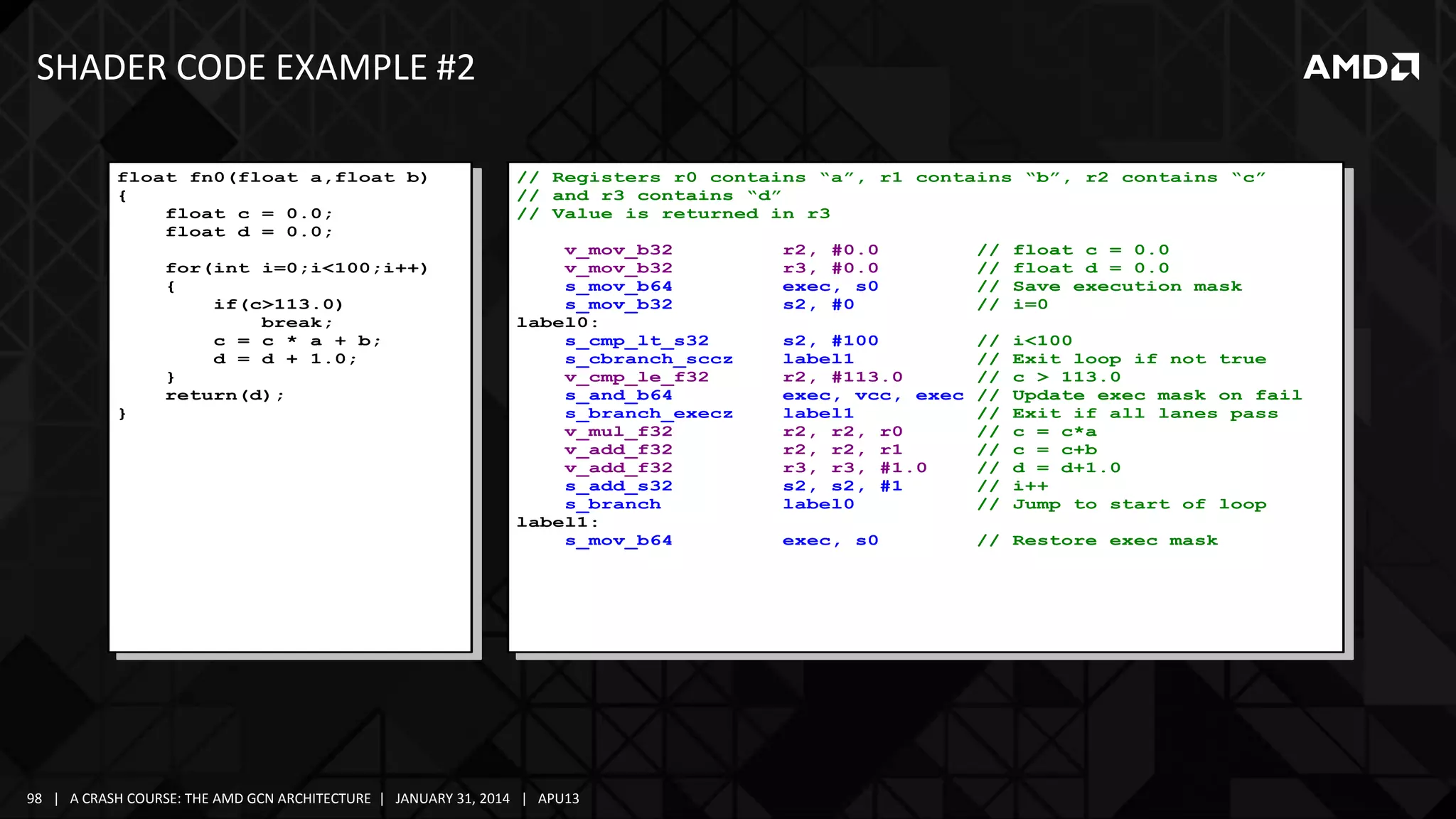


The document provides a detailed overview of AMD's Graphics Core Next (GCN) architecture, highlighting its evolution from earlier GPU designs and its components. It covers various aspects such as the memory hierarchy, compute unit anatomy, shader arbitration, and the overall compute capabilities of the GCN, including its optimized use for both graphics and compute tasks. Additionally, it discusses advancements in performance, efficiency, and the architectural support for modern computing needs.





































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)

















