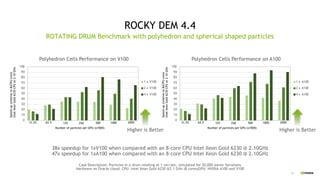
The document discusses NVIDIA data center GPUs such as the A100, A30, A40, and A10 and their performance capabilities. It provides examples of GPU accelerated application performance showing simulations in Simulia CST Studio, Altair CFD, and Rocky DEM achieving excellent speedups on GPUs. It also discusses Paraview visualization being accelerated with NVIDIA OptiX ray tracing, further sped up using RT cores. Looking ahead, the document outlines NVIDIA Grace CPUs which are designed to improve memory bandwidth between CPUs and GPUs for giant AI and HPC models.



























![[DL輪読会]Semi-supervised Knowledge Transfer for Deep Learning from Private Trai...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks20170414iwasawa-170414083300-thumbnail.jpg?width=640&height=640&fit=bounds)
































































