More Related Content

PPTX

PPTX

PPTX

PPTX

PDF
FluentdやNorikraを使った データ集約基盤への取り組み紹介 
PPTX

PDF

PPTX
Hadoop / Elastic MapReduceつまみ食い What's hot

PPTX
今さら聞けないHadoop セントラルソフト株式会社(20120119) 
ODP

PPTX
Hadoop -ResourceManager HAの仕組み- 
PDF
Amazon Elastic MapReduce@Hadoop Conference Japan 2011 Fall 
PDF
【17-E-3】Hadoop:黄色い象使いへの道 ~「Hadoop徹底入門」より~ 
PDF
PostgreSQL10を導入!大規模データ分析事例からみるDWHとしてのPostgreSQL活用のポイント 
PDF

PDF
Hadoop ecosystem NTTDATA osc15tk 
PDF

PDF
HadoopとRDBMSをシームレスに連携させるSmart SQL Processing (Hadoop Conference Japan 2014) 
PDF

PDF
Hadoop上の多種多様な処理でPigの活きる道 (Hadoop Conferecne Japan 2013 Winter) 
PPTX
ビッグデータ処理データベースの全体像と使い分け
2018年version 
PDF
分散処理基盤ApacheHadoop入門とHadoopエコシステムの最新技術動向(OSC2015 Kansai発表資料) 
PPTX
リクルートテクノロジーズ における EMR の活用とコスト圧縮方法 
PDF
Apache Drill Overview - Tokyo Apache Drill Meetup 2015/09/15 
PDF

PDF

PDF

PDF
MapR 5.2: MapR コンバージド・コミュニティ・エディションを使いこなす Viewers also liked

PDF

PDF

PDF

PDF
0151209 Oracle DDD OracleとHadoop連携の勘所 
PDF
リクルートにおけるVDI導入 ~働き方変革とセキュリティ向上の両立を目指して~ 
PDF
運用で泣かないアーキテクチャで動く原稿作成支援システム ~リクルートにおけるDeepLearning活用事例~ 
PDF

PDF
Embulk, an open-source plugin-based parallel bulk data loader 
PDF

PDF

PDF
スタディサプリを支えるデータ分析基盤 ~設計の勘所と利活用事例~ 
PDF
DataRobot活用状況@リクルートテクノロジーズ 
PDF

PDF

PDF
Similar to ビッグデータ&データマネジメント展

PPT
Hadoop ~Yahoo! JAPANの活用について~ 
PPT

PDF
NTTデータ流 Hadoop活用のすすめ ~インフラ構築・運用の勘所~ 
PDF
リクルートのビッグデータ活用基盤とデータ活用に向けた取組み 
PDF
Osc2012 spring HBase Report 
PDF

PPT
Hadoop~Yahoo! JAPANの活用について~ 
PDF
ビッグデータ革命 クラウドがコモデティ化する「奇跡」 
PPTX

PDF

PDF
![[INSIGHT OUT 2011] b21 ひとつのデータベース技術では生き残れない part2 no sql, hadoop](https://cdn.slidesharecdn.com/ss_thumbnails/insightout2011b21part2nosqlhadoop-111114020909-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[INSIGHT OUT 2011] b21 ひとつのデータベース技術では生き残れない part2 no sql, hadoop 
PPT
Hadoop~Yahoo!Japanの活用について 
PDF

PDF
C14_ひとつのdbでは夢を現実に変えられない!Human Dreams.Make IT Real by 石川太一 
PDF
Hadoop Conference Japan 2011 Fall: マーケティング向け大規模ログ解析事例紹介 
PDF

PDF

PPT

PDF
40分でわかるHadoop徹底入門 (Cloudera World Tokyo 2014 講演資料) More from Recruit Technologies

PDF

PDF
カーセンサーで深層学習を使ってUX改善を行った事例とそこからの学び 
PDF
Rancherを活用した開発事例の紹介 ~Rancherのメリットと辛いところ~ 
PDF

PDF

PDF

PDF
リクルートグループの現場事例から見る AI/ディープラーニング ビジネス活用の勘所 
PDF
Company Recommendation for New Graduates via Implicit Feedback Multiple Matri... 
PDF

PDF

PDF
リクルートにおけるマルチモーダル Deep Learning Web API 開発事例 
PDF

PDF
ユーザーからみたre:Inventのこれまでと今後 
PDF
Struggling with BIGDATA -リクルートおけるデータサイエンス/エンジニアリング- 
PDF
EMRでスポットインスタンスの自動入札ツールを作成する 
PDF

PDF
リクルートにおけるセキュリティ施策方針とCSIRT組織運営のポイント 
PDF

PDF
リクルートテクノロジーズが語る 企業における、「AI/ディープラーニング」活用のリアル 
PDF
「リクルートデータセット」 ~公開までの道のりとこれから~ ビッグデータ&データマネジメント展
- 1.
- 2.
はじめにですが。
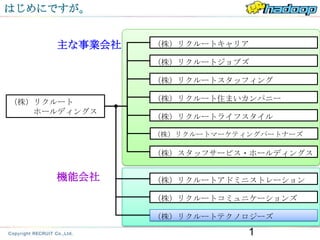
主な事業会社 (株)リクルートキャリア
(株)リクルートジョブズ
(株)リクルートスタッフィング
(株)リクルート (株)リクルート住まいカンパニー
ホールディングス
(株)リクルートライフスタイル
(株)リクルートマーケティングパートナーズ
(株)スタッフサービス・ホールディングス
機能会社 (株)リクルートアドミニストレーション
(株)リクルートコミュニケーションズ
(株)リクルートテクノロジーズ
1
- 3.
- 4.
- 5.
自己紹介
□名前
石川 信行
( ground_beetle)
□出身
福島県 いわき市
大学時代は、害虫制御学および生物統計学専攻
□経歴
・2009年リクルート新卒入社
・営業支援システムのコーダー(java)、DBAとして参加。
・2010年Hadoop推進担当
・現Hadoop案件推進・新用途開発チームリーダー
□ 趣味
・外国産カブト虫飼育
・スキューバダイビング
・海水魚飼育
- 6.
アジェンダ
1
• リクルートについて
2
• ビッグデータへの取り組みの現状
3
• 利活用事例紹介
4
• 課題の克服
5
• まとめ
- 7.
- 8.
ビジネスモデル
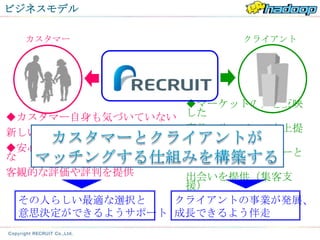
カスタマー クライアント
◆マーケットの声を反映
◆カスタマー自身も気づいていない した
新しい発見や可能性の提示 商品・サービスの向上提
案
◆安心して選択や行動ができるよう ◆未だ見ぬカスタマーと
な の
客観的な評価や評判を提供 出会いを提供(集客支
援)
その人らしい最適な選択と クライアントの事業が発展、
意思決定ができるようサポート 成長できるよう伴走
- 9.
リクルートについて(事業概要)
※サービスの一部です
ライフイベント領域 ライフスタイル領域
旅行
車購入
住宅購入 お稽古 ファッション
転職
出産/育児
結婚 時事 飲食
就職
進学
将来を考えて選択と意思決定 日常の中にある「何を食べよう
をする大きな「イベント」 か」
といった、小さな選択と意思決定
- 10.
リクルートについて(会社概要)
創 業 : 1960年3月31日
資本金 : 30億264万円
売上高 : 3,720億57百万円(2011年4月1日~2012年3月31日)
連結売上高 : 8,066億61百万円(2011年4月1日~2012年3月31日)
従業員数 : 5,974名 (2012年4月1日現在)男性:2619名・女性:3355名
代表者 : 代表取締役社長 峰岸 真澄
- 11.
- 12.
新技術のR&D取り組みステップ
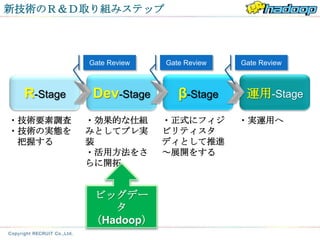
Gate Review Gate Review Gate Review
R-Stage Dev-Stage β-Stage 運用-Stage
・技術要素調査 ・効果的な仕組 ・正式にフィジ ・実運用へ
・技術の実態を みとしてプレ実 ビリティスタ
把握する 装 ディとして推進
・活用方法をさ ~展開をする
らに開拓
ビッグデー
タ
(Hadoop)
- 13.
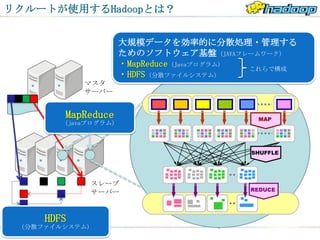
リクルートが使用するHadoopとは?
大規模データを効率的に分散処理・管理する
ためのソフトウェア基盤(JAVAフレームワーク)
・MapReduce(Javaプログラム) これらで構成
・HDFS(分散ファイルシステム)
マスタ
サーバー
MapReduce MAP
(javaプログラム)
SHUFFLE
スレーブ
REDUCE
サーバー
HDFS
(分散ファイルシステム)
- 14.
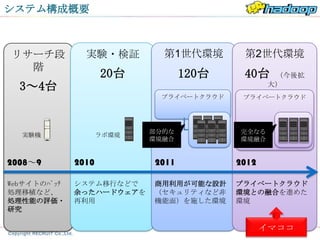
システム構成概要
リサーチ段 実験・検証 第1世代環境 第2世代環境
階
20台 120台 40台 (今後拡
3~4台 大)
プライベートクラウド プライベートクラウド
部分的な 完全なる
実験機 ラボ環境
環境融合 環境融合
2008~9 2010 2011 2012
Webサイトのバッチ システム移行などで 商用利用が可能な設計 プライベートクラウド
処理移植など、 余ったハードウェアを (セキュリティなど非 環境との融合を進めた
処理性能の評価・ 再利用 機能面)を施した環境 環境
研究
イマココ
- 15.
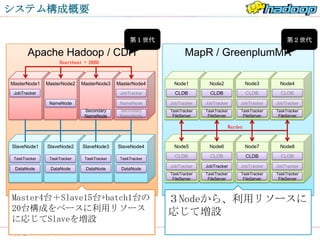
システム構成概要
第1世代 第2世代
Apache Hadoop / CDH MapR / GreenplumMR
Heartbeat + DRBD
MasterNode1 MasterNode2 MasterNode3 MasterNode4 Node1 Node2 Node3 Node4
JobTracker JobTracker CLDB CLDB CLDB CLDB
NameNode NameNode JobTracker JobTracker JobTracker JobTracker
Secondary Secondary TaskTracker TaskTracker TaskTracker TaskTracker
NameNode NameNode FileServer FileServer FileServer FileServer
Warden
SlaveNode1 SlaveNode2 SlaveNode3 SlaveNode4 Node5 Node6 Node7 Node8
TaskTracker TaskTracker TaskTracker TaskTracker
CLDB CLDB CLDB CLDB
JobTracker JobTracker JobTracker JobTracker
DataNode DataNode DataNode DataNode
TaskTracker TaskTracker TaskTracker TaskTracker
FileServer FileServer FileServer FileServer
Master4台+Slave15台+batch1台の 3Nodeから、利用リソースに
20台構成をベースに利用リソース 応じて増設
に応じてSlaveを増設
- 16.
- 17.
- 18.
- 19.
- 20.
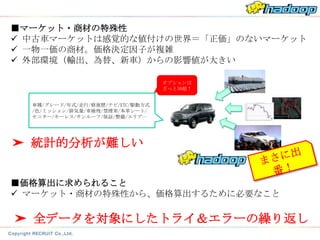
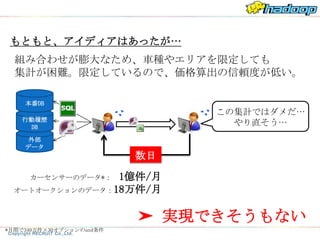
どこにデータ活用がされているのか?
車の価格設定
条件の近いものをまとめ、一律の
保証等を付けて同一品質・同一価格を実現する
これが難しい。なぜか?
どのような項目でまとめれば良いか?
最適な値段はいくらなのか?
- 21.
- 22.
- 23.
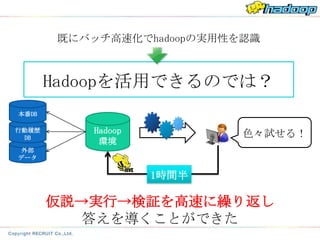
既にバッチ高速化でhadoopの実用性を認識
Hadoopを活用できるのでは?
本番DB
行動履歴 Hadoop 色々試せる!
DB
環境
外部
データ
1時間半
仮説→実行→検証を高速に繰り返し
答えを導くことができた
- 24.
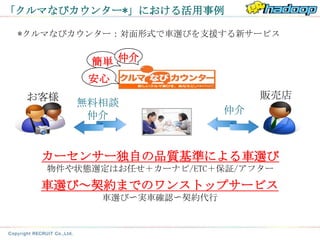
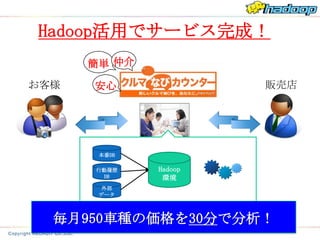
Hadoop活用でサービス完成!
簡単 仲介
お客様 安心 販売店
本番DB
行動履歴 Hadoop
DB 環境
外部
データ
毎月950車種の価格を30分で分析!
- 25.
オープン後の課題に対して追加分析も。
特定の色の車の取引価格が高く仕入れ
が難しい!オプション料金にするかど
うか考えている。
距離や年式などをずらした際の
価格変動をみたい。
GWやお盆が売れゆきは?
去年のシーズナリティを見たい。
どんなに頑張って分析しても必ず課題は出てくる。
問題はこれをいかに迅速に解決できるか。事業担当者が現場で
感じている感覚をデータですばやく証明する。
- 26.
- 27.
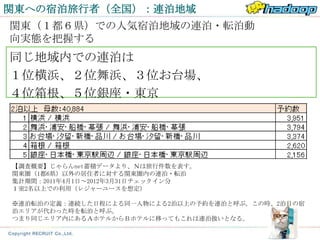
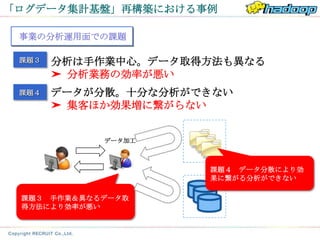
じゃらんnet宿泊実行履歴とは?
• 年間6020万人泊の宿泊予約、宿泊実行
履歴データ
– サービス開始の2000年11月11日から約12年
間の蓄積
– 会員数1032万人(2012年2月末時点)
– 契約宿泊施設数 2万2462軒
– 国内最大級の宿泊予約サイト
これらのデータを使って解析した結果を
地方自治体に向けて公開するセミナーを開催している。
今年はビッグデータ解析関連の講演も行われた。
ムムッ…
- 28.
- 29.
- 30.
- 31.
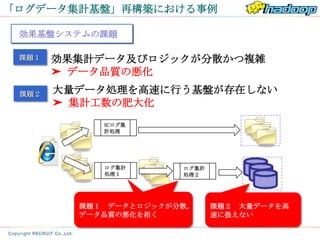
「ログデータ集計基盤」再構築における事例
効果基盤システムの課題
課題1 効果集計データ及びロジックが分散かつ複雑
➤ データ品質の悪化
課題2 大量データ処理を高速に行う基盤が存在しない
➤ 集計工数の肥大化
SCログ集
計処理
ログ集計 ログ集計
処理1 処理2
課題1 データとロジックが分散。 課題2 大量データを高
データ品質の悪化を招く 速に扱えない
- 32.
- 33.
- 34.
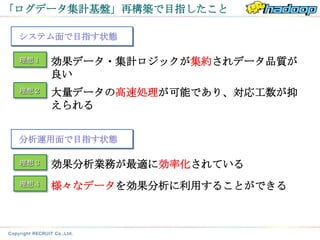
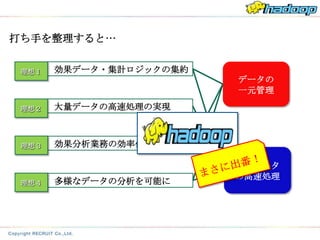
打ち手を整理すると…
理想1 効果データ・集計ロジックの集約
データの
一元管理
理想2 大量データの高速処理の実現
理想3 効果分析業務の効率化
大量データ
の高速処理
理想4 多様なデータの分析を可能に
- 35.
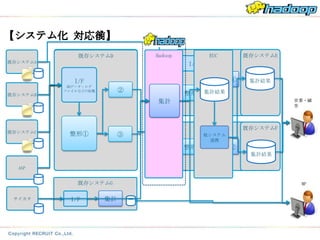
【システム化 対応後】
対応前】
既存システムD Hadoop EUC 既存システムE
既存システムE
既存システムA
I/F
I/F 集計① 集計結果
DBデータ・ログ
②
既存システムB
ファイルなどの収集
整形② 集計結果
集計 営業・顧
客
整形① 既存システムF
既存システムF
既存システムC マスタデータの整形
整形① ③
やアクセスログの整 他システム
形 連携
整形③ 集計②
集計結果
ASP
既存システムG MP
サイカタ I/F 集計
- 36.
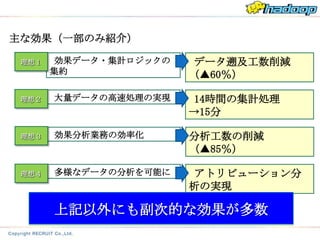
主な効果(一部のみ紹介)
理想1 効果データ・集計ロジックの データ遡及工数削減
集約 (▲60%)
理想2 大量データの高速処理の実現 14時間の集計処理
→15分
理想3 効果分析業務の効率化 分析工数の削減
(▲85%)
理想4 多様なデータの分析を可能に アトリビューション分
析の実現
上記以外にも副次的な効果が多数
- 37.
- 38.
- 39.
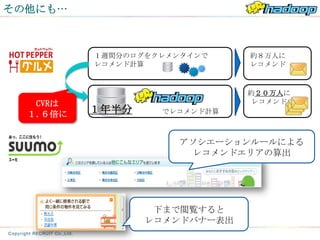
その他にも…
1週間分のログをクレメンタインで 約8万人に
レコメンド計算 レコメンド
約20万人に
CVRは レコメンド
1.6倍に 1年半分 でレコメンド計算
アソシエーションルールによる
レコメンドエリアの算出
下まで閲覧すると
レコメンドバナー表出
- 40.
リスティング分
事業A 施策シェア分析
析
クチコミ分析
サイト横断
事業B サイト間 モニタリング レコメンド KWD×LP分析
13事業に対し、
クロスUU 指標
事業C 調査 予約分析
事業D メルマガ施策 BI
年間100件超
KPIモニタリン
メール通数分析 現行応募相関 ステータス分析
事業E グ
自然語解析 行動ターゲティング LPO
事業F レコメンド ログ分析
事業G
事業H
自然語解析
領域間クロス
UU
の
カスタマープロファイル
メールレコメン
ド
集客モニタリン
グ
商材分析
需要予測
需要予測
クライアントHP分析
クレンジング
レコメンド
カスタマートラッキング
共通バナー
事業I
事業J
グ
価格分析
データ利活用
KPIモニタリン アクション数予
測
レコメンド
効果集計
クラスタリング クチコミ分析
レコメンド
事業K
事業L レコメンド を展開中
効果見立て分析
事業M 39
- 41.
- 42.
- 43.
- 44.
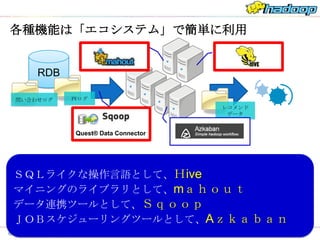
各種機能は「エコシステム」で簡単に利用
RDB
問い合わせログ PVログ
レコメンド
データ
Quest® Data Connector
SQLライクな操作言語として、Hive
マイニングのライブラリとして、mahout
データ連携ツールとして、Sqoop
JOBスケジューリングツールとして、Azkaban
- 45.
①Sqoop の活用
・DBからデータ移行に時間がか
かる。
・工数がかかる。
・HadoopとRDBMSとでデータをやり取りするためのしくみ
・Oracleデータベースへの高速接続を提供する「OraOop」など
・RDBMSを完全に撤廃させることなく、RDBMSと
Hadoopでデータを共有、使い分けを可能にする
・複数のRDBMSによる分析基盤作りにも有効
本番DB
Hadoop
検証環境
ログ
本番データから
外部
Hadoopデータに連
データ
携する
- 46.
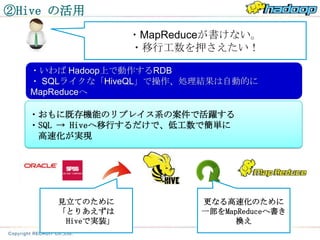
②Hive の活用
・MapReduceが書けない。
・移行工数を押さえたい!
・いわば Hadoop上で動作するRDB
・ SQLライクな「HiveQL」で操作、処理結果は自動的に
MapReduceへ
・おもに既存機能のリプレイス系の案件で活躍する
・SQL → Hiveへ移行するだけで、低工数で簡単に
高速化が実現
見立てのために 更なる高速化のために
「とりあえずは 一部をMapReduceへ書き
Hiveで実装」 換え
- 47.
③mahout の活用
・機械学習のロジックを使いたい。
が、難しくて実装できない。
・データマイニング系ロジックのJavaライブラリ
・「アソシエーション分析」などのアルゴリズムが用意されている
・協調フィルタリングや、アソシエーションルール
に基づくレコメンドなど
・複数の中から最適な条件を選定することが可能
まずは、実際のデータで動かし、試す。これが大事。
行動履歴
データ レコメンド物件の
表示など
- 48.
- 49.
- 50.
- 51.
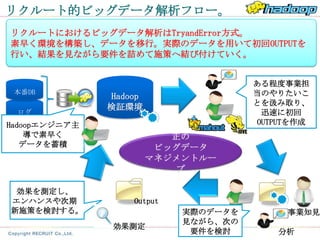
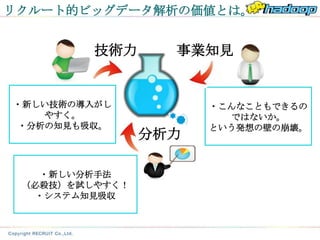
リクルート的ビッグデータ解析の価値とは。
技術力 事業知見
・新しい技術の導入がし ・こんなこともできるの
やすく。 ではないか。
・分析の知見も吸収。 という発想の壁の崩壊。
分析力
・新しい分析手法
(必殺技)を試しやすく!
・システム知見吸収
- 52.
今後の展望
with 自然言語処理
DWH
:Hadoop+Mahout(マイニング)+Lucene(形態素分解)ほか 活用
➤ クチコミ分析、レコメンドメールなどへ応用展開 or
RDB
with リアルタイム分析
:Hbase、S4・STORM(リアルタイム分散処理プラットフォーム)
ほか 活用
➤ リアルタイムレコメンド、フラッシュマーケティングなど
with スマートデバイス
:音声解析(Siri)・位置情報の取り込み、画像データの取り込み ほか
➤ ユーザ属性×GPS(行動履歴)分析による店舗情報プッシュなど