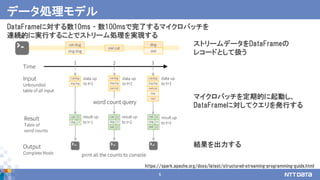
17
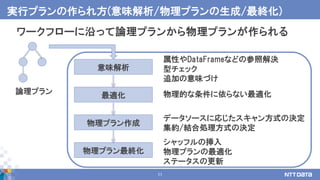
例題: 平均値を求める -部分集約処理 -
20
17
30
A
B
C
area temp
A 20
B 17
C 30
・
・
・
DataFrame
(観測点の気温)
32
31
22
B
B
A
27
15
17
C
A
A
20
17
30
A
B
C
1
1
1
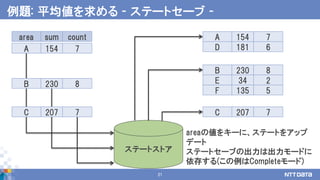
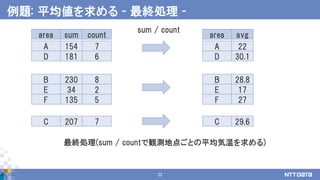
累積気温 観測件数
累積値とレコード数の属性を追加
sumarea count
63
22
B
A
2
1
27
32
C
A
1
2
分
割
し
て
各
タ
ス
ク
に
分
配
タ
ス
ク
ご
と
に
集
約
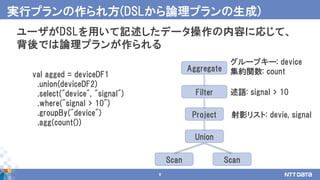
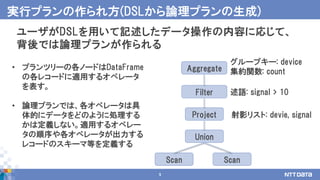
18.
18
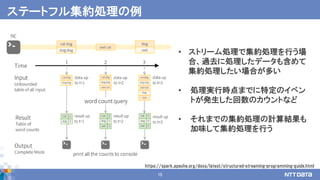
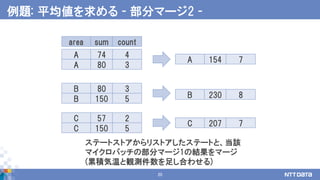
例題: 平均値を求める -部分マージ処理1 -
20
17
30
A
B
C
1
1
1
累積気温 観測件数
sumarea count
63
22
B
A
2
1
27
32
C
A
1
2
20
22
32
A
A
A
1
1
2
17
63
B
B
1
2
30
27
C
C
1
1
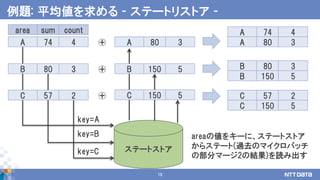
74A 4
80B 3
57C 2
観測点ごとにマージ
(累積気温と観測件数を足し合わせる)
観
測
点
ご
と
に
シ
ャ
ッ
フ
ル



















































![[db tech showcase Tokyo 2016] B31: Spark Summit 2016@SFに参加してきたので最新事例などを紹介しつつデ...](https://cdn.slidesharecdn.com/ss_thumbnails/1oula7aqkczs8b8nxbbw-signature-52b95cf478429666da1eac73ad45213570cae72b7e57434c17b4c128f24099d3-poli-160722095519-thumbnail.jpg?width=640&height=640&fit=bounds)















![[db tech showcase Tokyo 2014] D25: 今を分析する日立の「CEP」、知るなら今でしょ! by 株式会社日立製作所 村上順一](https://cdn.slidesharecdn.com/ss_thumbnails/dbtstokyo2014d25cep-141127185437-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)



















