2012年12月10日 NTTデータ オープンソースDAY 2012 講演資料 『ストリームデータ分散処理基盤 Storm』 NTTデータ 基盤システム事業本部 OSSプロフェッショナルサービス 岩崎 正剛 http://oss.nttdata.co.jp/hadoop/






























![50Copyright © 2013 NTT DATA Corporation
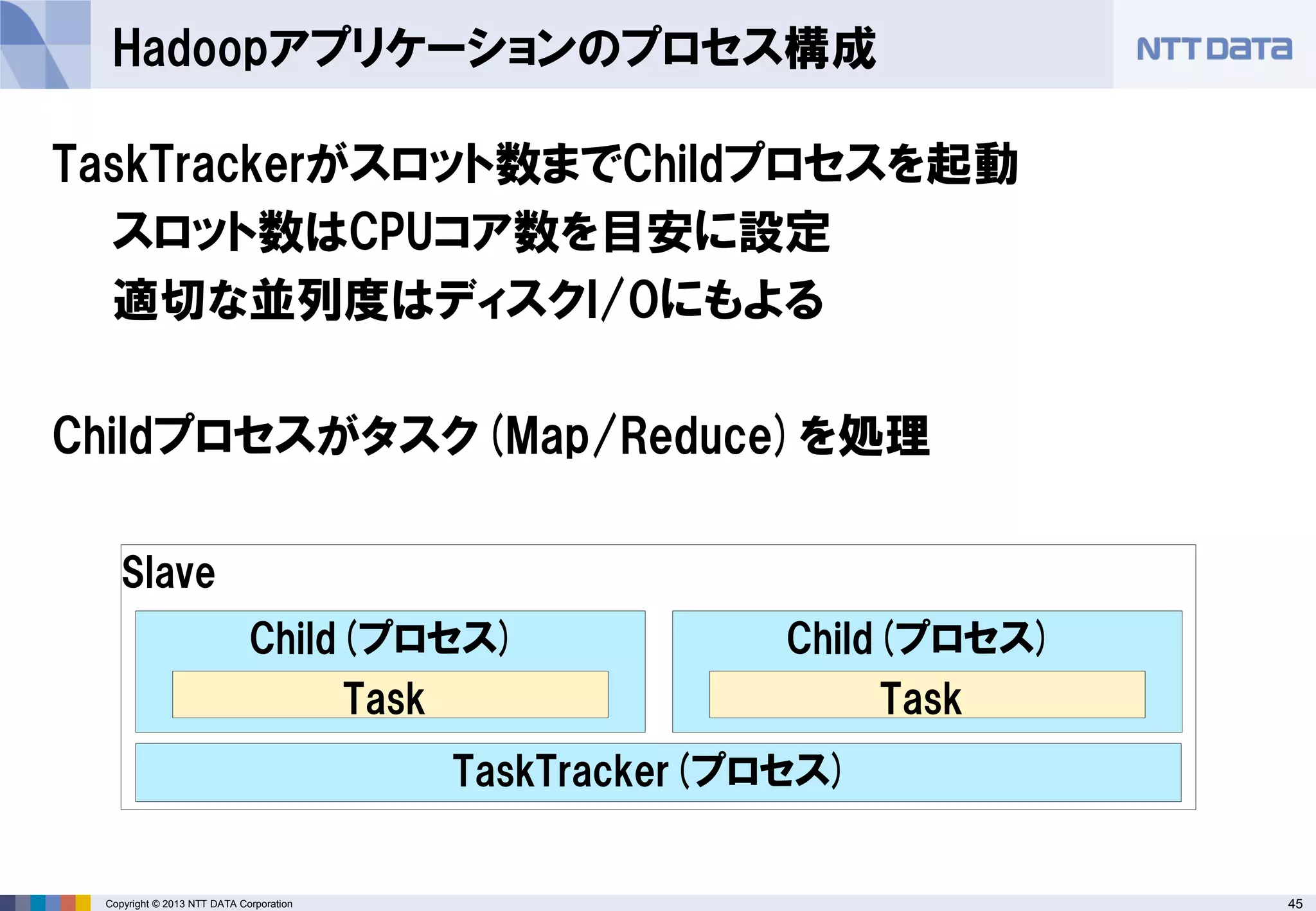
Javaで記述したHadoopアプリケーション
Mapperの定義
Job job = new Job(new Configuration(), "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
job.submit();
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
Jobの定義と起動](https://image.slidesharecdn.com/storm-nttdata-130422040216-phpapp02/75/Storm-50-2048.jpg)
![51Copyright © 2013 NTT DATA Corporation
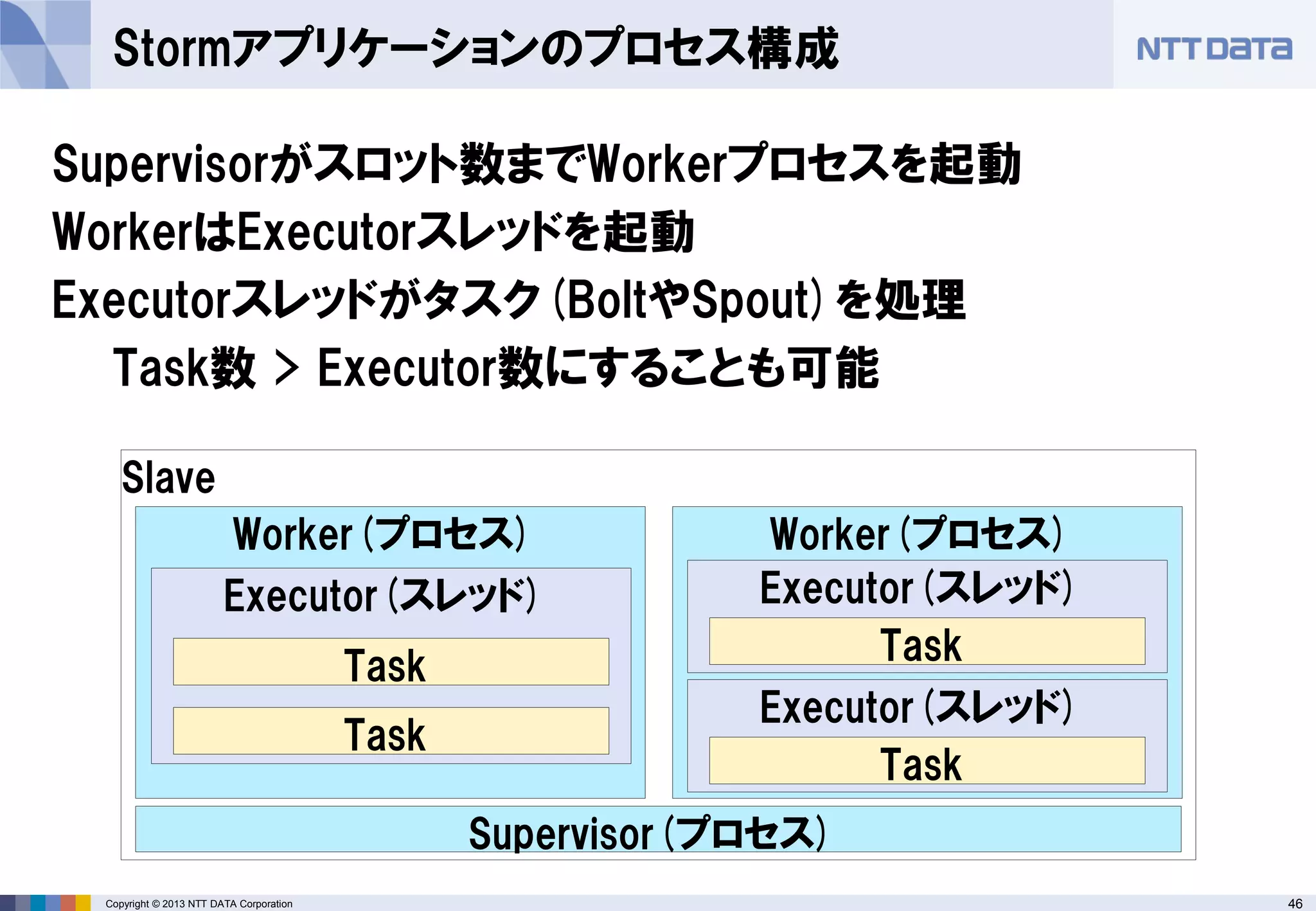
Javaで記述したStormアプリケーション
Boltの定義
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("spout", new RandomSentenceSpout(), 5);
builder.setBolt("split", new SplitSentence(), 8)
.shuffleGrouping("spout");
builder.setBolt("count", new WordCount(), 12)
.fieldsGrouping("split", new Fields("word"));
Config conf = new Config();
conf.setNumWorkers(3);
StormSubmitter.submitTopology(args[0], conf, builder.createTopology());
public static class WordCount extends BaseBasicBolt {
Map<String, Integer> counts = new HashMap<String, Integer>();
public void execute(Tuple tuple, BasicOutputCollector collector) {
String word = tuple.getString(0);
Integer count = counts.get(word);
if(count==null) count = 0;
count++;
counts.put(word, count);
collector.emit(new Values(word, count));
}
Topologyの定義と起動](https://image.slidesharecdn.com/storm-nttdata-130422040216-phpapp02/75/Storm-51-2048.jpg)



![55Copyright © 2013 NTT DATA Corporation
Clojure DSLで記述したStormアプリケーション
Boltの定義
(defn -main
([name]
(StormSubmitter/submitTopology
name
{TOPOLOGY-WORKERS 3}
(topology
{"spout" (spout-spec sentence-spout :p 5)}
{"split" (bolt-spec {"spout" :shuffle } split-sentence :p 8)
"count" (bolt-spec {"split" ["word"]} word-count:p 12)}
)))))
(defbolt word-count ["word" "count"] {:prepare true}
[conf context collector]
(let [counts (atom {})]
(bolt
(execute [tuple]
(let [word (.getString tuple 0)]
(swap! counts (partial merge-with +) {word 1})
(emit-bolt! collector [word (@counts word)] :anchor tuple)
(ack! collector tuple)
)))))
Topologyの定義と起動](https://image.slidesharecdn.com/storm-nttdata-130422040216-phpapp02/75/Storm-55-2048.jpg)

![57Copyright © 2013 NTT DATA Corporation
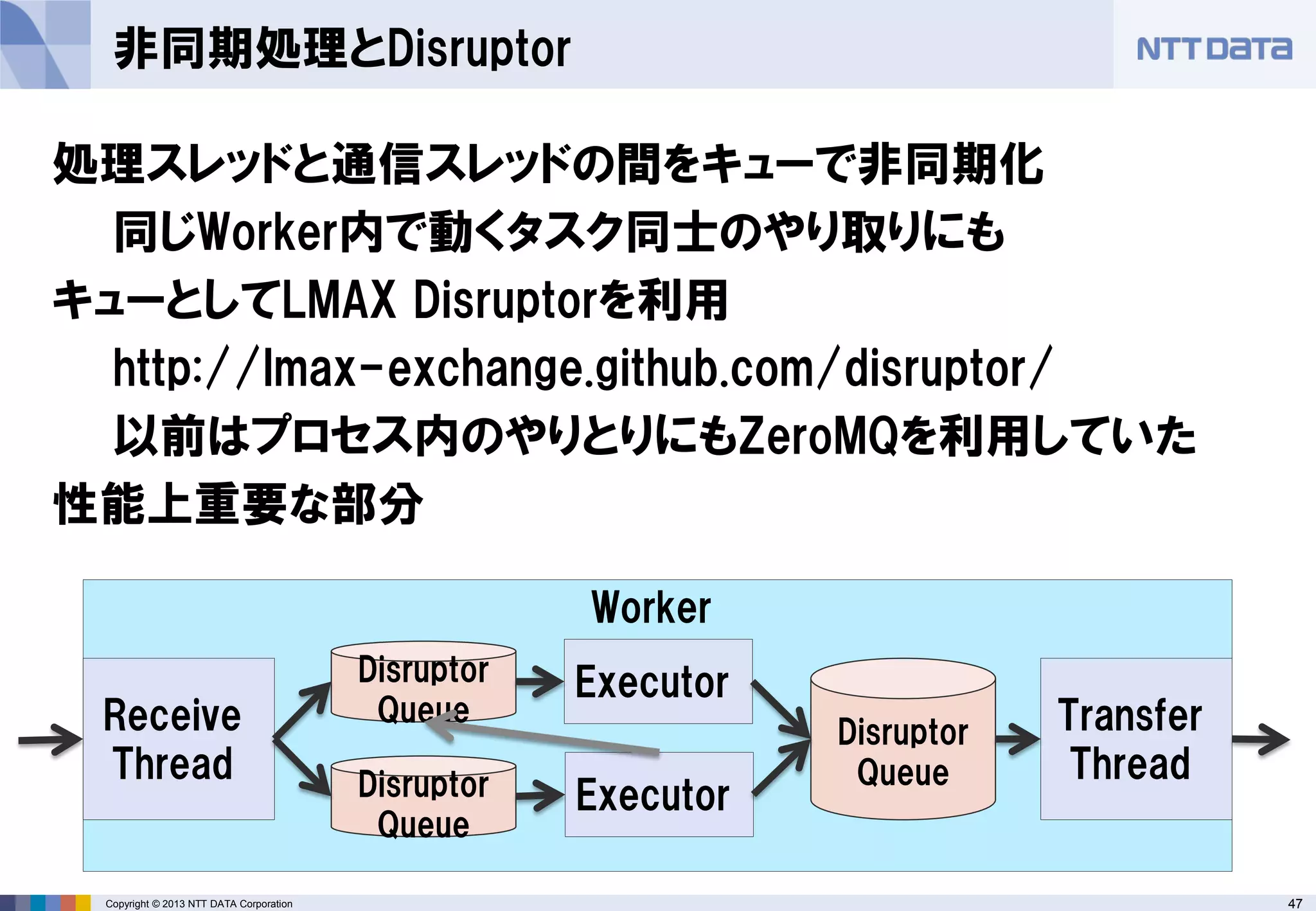
ShellBolt
Boltを外部コマンドとして起動
標準入出力経由のデータ受け渡しで制御
Hadoop Streamingと同じ
任意のプログラミング言語でアプリケーションが書ける
{"command": "next"}
{
"command": "emit",
"id": "12345",
"stream": "1",
"task": 3,
"tuple": ["foobar", 3, 0.2]
}
子プロセスに渡すコマンドの例:
子プロセスからの返却値の例:](https://image.slidesharecdn.com/storm-nttdata-130422040216-phpapp02/75/Storm-57-2048.jpg)




























![DeNAのインフラ戦略 〜クラウドジャーニーの舞台裏〜 [DeNA TechCon 2019]](https://cdn.slidesharecdn.com/ss_thumbnails/techcon2019kanekofinal-190218061927-thumbnail.jpg?width=640&height=640&fit=bounds)








![[社内勉強会]春の嵐を巻き起こせ Storm補完計画](https://cdn.slidesharecdn.com/ss_thumbnails/storm-160304020110-thumbnail.jpg?width=640&height=640&fit=bounds)

































