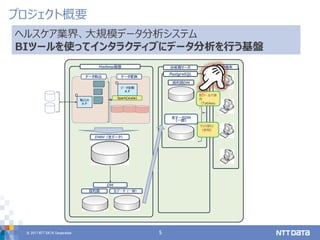
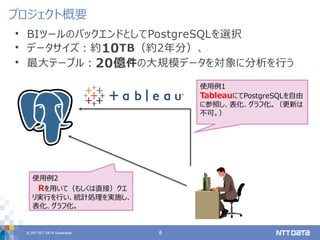
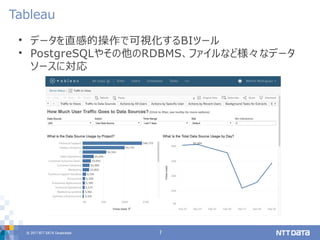
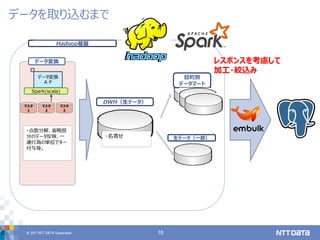
2017年12月5日に開催されたPGCONF.ASIAの講演資料です。 Data warehousing with PostgreSQL 10 : Know-hows which is extracted from case study








![© 2017 NTT DATA Corporation 12
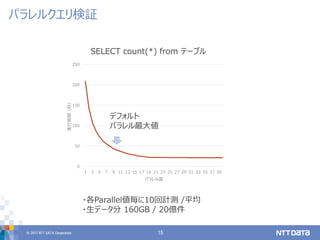
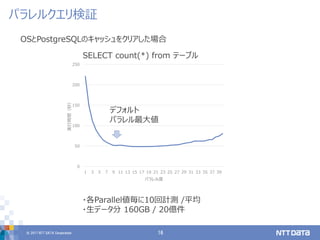
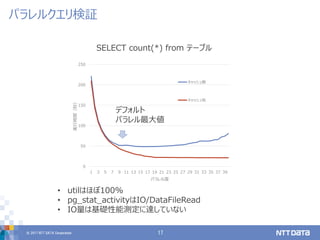
目的は、「パラレルクエリ活用」
CPU
• パラレルクエリの並列数×同時接続数で使用されるコア数の確保
メモリ
[本件の前提]データサイズが大きいため、全てがメモリに載りきるのは難しい
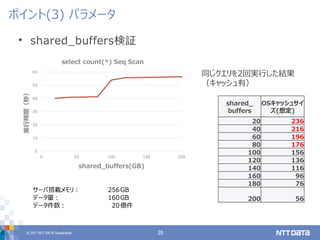
• 256GB
• 基本はIOで処理される前提で、IO重視
ストレージ
[本件の前提]ディスクアクセスが大量に走る
• SSD
• IOが弱いと、パラレルクエリの恩恵が受けられない
• RAID6
• 読み込み性能重視
ポイント(1) サイジング](https://image.slidesharecdn.com/postgresql10dwhcasestudy-171208044557/85/PostgreSQL10-DWH-PostgreSQL-12-320.jpg)





























































![[db tech showcase Tokyo 2014] D21: Postgres Plus Advanced Serverはここが使える&9.4新機...](https://cdn.slidesharecdn.com/ss_thumbnails/dbtstokyo2014d21hppostgresplusadvancedserverv9-141120232610-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)


























