Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
NS
Uploaded by
NTT DATA OSS Professional Services
10,073 views
データ活用をもっともっと円滑に! ~データ処理・分析基盤編を少しだけ~
データ活用をもっともっと円滑に! ~データ処理・分析基盤編を少しだけ~ 2016/7/26 Spark Summit2016報告会&データ分析勉強会
Technology
◦
Related topics:
Apache Spark
•
Read more
9
Save
Share
Embed
Embed presentation
1
/ 22
2
/ 22
3
/ 22
4
/ 22
5
/ 22
6
/ 22
7
/ 22
8
/ 22
9
/ 22
10
/ 22
11
/ 22
12
/ 22
13
/ 22
14
/ 22
15
/ 22
16
/ 22
17
/ 22
18
/ 22
19
/ 22
20
/ 22
21
/ 22
22
/ 22
More Related Content
PDF
Ansibleで構成管理始める人のモチベーションをあげたい! (Cloudera World Tokyo 2014LT講演資料)
by
NTT DATA OSS Professional Services
PDF
Spark MLlibではじめるスケーラブルな機械学習
by
NTT DATA OSS Professional Services
PDF
ビッグデータ活用を加速する!分散SQLエンジン Spark SQL のご紹介 20161105 OSC Tokyo Fall
by
YusukeKuramata
PDF
Sparkコミュニティに飛び込もう!(Spark Meetup Tokyo 2015 講演資料、NTTデータ 猿田 浩輔)
by
NTT DATA OSS Professional Services
PDF
Apache Hadoop 2.8.0 の新機能 (抜粋)
by
NTT DATA OSS Professional Services
PDF
Sparkをノートブックにまとめちゃおう。Zeppelinでね!(Hadoopソースコードリーディング 第19回 発表資料)
by
NTT DATA OSS Professional Services
PDF
Hadoop ecosystem NTTDATA osc15tk
by
NTT DATA OSS Professional Services
PDF
Apache Spark超入門 (Hadoop / Spark Conference Japan 2016 講演資料)
by
NTT DATA OSS Professional Services
Ansibleで構成管理始める人のモチベーションをあげたい! (Cloudera World Tokyo 2014LT講演資料)
by
NTT DATA OSS Professional Services
Spark MLlibではじめるスケーラブルな機械学習
by
NTT DATA OSS Professional Services
ビッグデータ活用を加速する!分散SQLエンジン Spark SQL のご紹介 20161105 OSC Tokyo Fall
by
YusukeKuramata
Sparkコミュニティに飛び込もう!(Spark Meetup Tokyo 2015 講演資料、NTTデータ 猿田 浩輔)
by
NTT DATA OSS Professional Services
Apache Hadoop 2.8.0 の新機能 (抜粋)
by
NTT DATA OSS Professional Services
Sparkをノートブックにまとめちゃおう。Zeppelinでね!(Hadoopソースコードリーディング 第19回 発表資料)
by
NTT DATA OSS Professional Services
Hadoop ecosystem NTTDATA osc15tk
by
NTT DATA OSS Professional Services
Apache Spark超入門 (Hadoop / Spark Conference Japan 2016 講演資料)
by
NTT DATA OSS Professional Services
What's hot
PDF
ちょっと理解に自信がないな という皆さまに贈るHadoop/Sparkのキホン (IBM Datapalooza Tokyo 2016講演資料)
by
hamaken
PDF
15.05.21_ビッグデータ分析基盤Sparkの最新動向とその活用-Spark SUMMIT EAST 2015-
by
LINE Corp.
PDF
Hadoop2.6の最新機能+
by
NTT DATA OSS Professional Services
PDF
SIerとオープンソースの美味しい関係 ~コミュニティの力を活かして世界を目指そう~
by
NTT DATA OSS Professional Services
PDF
Hadoopエコシステムの最新動向とNTTデータの取り組み (OSC 2016 Tokyo/Spring 講演資料)
by
NTT DATA OSS Professional Services
PDF
Apache Spark 1000 nodes NTT DATA
by
NTT DATA OSS Professional Services
PDF
Hadoop 2.6の最新機能(Cloudera World Tokyo 2014 LT講演資料)
by
NTT DATA OSS Professional Services
PDF
ビッグデータ関連Oss動向調査とニーズ分析
by
Yukio Yoshida
PPSX
HBaseとSparkでセンサーデータを有効活用 #hbasejp
by
FwardNetwork
PDF
Spark勉強会_ibm_20151014-公開版
by
Atsushi Tsuchiya
PDF
Spark Summit 2015 参加報告
by
Katsunori Kanda
PDF
Apache Spark の紹介(前半:Sparkのキホン)
by
NTT DATA OSS Professional Services
PDF
Apache Sparkに手を出してヤケドしないための基本 ~「Apache Spark入門より」~ (デブサミ 2016 講演資料)
by
NTT DATA OSS Professional Services
PDF
Apache Sparkの紹介
by
Ryuji Tamagawa
PDF
分散処理基盤ApacheHadoop入門とHadoopエコシステムの最新技術動向(OSC2015 Kansai発表資料)
by
NTT DATA OSS Professional Services
PPTX
Pythonで入門するApache Spark at PyCon2016
by
Tatsuya Atsumi
PDF
分散処理基盤Apache Hadoopの現状と、NTTデータのHadoopに対する取り組み
by
NTT DATA OSS Professional Services
PPT
はやわかりHadoop
by
Shinpei Ohtani
PDF
基幹業務もHadoopで!! -ローソンにおける店舗発注業務への Hadoop + Hive導入と その取り組みについて-
by
Keigo Suda
PPTX
リクルートライフスタイルの考える ストリームデータの活かし方(Hadoop Spark Conference2016)
by
Atsushi Kurumada
ちょっと理解に自信がないな という皆さまに贈るHadoop/Sparkのキホン (IBM Datapalooza Tokyo 2016講演資料)
by
hamaken
15.05.21_ビッグデータ分析基盤Sparkの最新動向とその活用-Spark SUMMIT EAST 2015-
by
LINE Corp.
Hadoop2.6の最新機能+
by
NTT DATA OSS Professional Services
SIerとオープンソースの美味しい関係 ~コミュニティの力を活かして世界を目指そう~
by
NTT DATA OSS Professional Services
Hadoopエコシステムの最新動向とNTTデータの取り組み (OSC 2016 Tokyo/Spring 講演資料)
by
NTT DATA OSS Professional Services
Apache Spark 1000 nodes NTT DATA
by
NTT DATA OSS Professional Services
Hadoop 2.6の最新機能(Cloudera World Tokyo 2014 LT講演資料)
by
NTT DATA OSS Professional Services
ビッグデータ関連Oss動向調査とニーズ分析
by
Yukio Yoshida
HBaseとSparkでセンサーデータを有効活用 #hbasejp
by
FwardNetwork
Spark勉強会_ibm_20151014-公開版
by
Atsushi Tsuchiya
Spark Summit 2015 参加報告
by
Katsunori Kanda
Apache Spark の紹介(前半:Sparkのキホン)
by
NTT DATA OSS Professional Services
Apache Sparkに手を出してヤケドしないための基本 ~「Apache Spark入門より」~ (デブサミ 2016 講演資料)
by
NTT DATA OSS Professional Services
Apache Sparkの紹介
by
Ryuji Tamagawa
分散処理基盤ApacheHadoop入門とHadoopエコシステムの最新技術動向(OSC2015 Kansai発表資料)
by
NTT DATA OSS Professional Services
Pythonで入門するApache Spark at PyCon2016
by
Tatsuya Atsumi
分散処理基盤Apache Hadoopの現状と、NTTデータのHadoopに対する取り組み
by
NTT DATA OSS Professional Services
はやわかりHadoop
by
Shinpei Ohtani
基幹業務もHadoopで!! -ローソンにおける店舗発注業務への Hadoop + Hive導入と その取り組みについて-
by
Keigo Suda
リクルートライフスタイルの考える ストリームデータの活かし方(Hadoop Spark Conference2016)
by
Atsushi Kurumada
Similar to データ活用をもっともっと円滑に! ~データ処理・分析基盤編を少しだけ~
PPTX
NTTデータが考えるデータ基盤の次の一手 ~AI活用のために知っておくべき新潮流とは?~(NTTデータ テクノロジーカンファレンス 2020 発表資料)
by
NTT DATA Technology & Innovation
PDF
【講演資料】ビッグデータ時代の経営を支えるビジネスアナリティクスソリューション
by
Dell TechCenter Japan
PDF
利用者主体で行う分析のための分析基盤
by
Sotaro Kimura
PDF
並列分散処理基盤Hadoopの紹介と、開発者が語るHadoopの使いどころ (Silicon Valley x 日本 / Tech x Business ...
by
NTT DATA OSS Professional Services
PPTX
Spark+AI Summit Europe 2019 セッションハイライト(Spark Meetup Tokyo #2 講演資料)
by
NTT DATA Technology & Innovation
PDF
データ分析基盤について
by
Yuta Inamura
PDF
Spark + AI Summit 2020セッションのハイライト(Spark Meetup Tokyo #3 Online発表資料)
by
NTT DATA Technology & Innovation
PDF
[db tech showcase Tokyo 2016] B31: Spark Summit 2016@SFに参加してきたので最新事例などを紹介しつつデ...
by
Insight Technology, Inc.
PDF
Spark SQL - The internal -
by
NTT DATA OSS Professional Services
PPTX
R&D部門におけるデータ共有・利活用はなぜ難しいのか
by
恵 桂木
PPTX
ils202202
by
恵 桂木
PPTX
R&D部門におけるデータ共有・利活用はなぜ難しいのか
by
恵 桂木
PPTX
R&D部門におけるデータ共有・利活用はなぜ難しいのか
by
恵 桂木
PPTX
ils202202
by
恵 桂木
PPTX
R&D部門におけるデータ共有・利活用はなぜ難しいのか
by
恵 桂木
PDF
変わる!? リクルートグループのデータ解析基盤
by
Recruit Technologies
PPTX
ITインフラsummit 2017発表資料
by
Masayuki Hyugaji
PDF
データファースト開発
by
Katsunori Kanda
PPTX
Devsumi 2016 b_4 KafkaとSparkを組み合わせたリアルタイム分析基盤の構築
by
Tanaka Yuichi
PDF
Yahoo! JAPANのデータ基盤とHadoop #dbts2016
by
Yahoo!デベロッパーネットワーク
NTTデータが考えるデータ基盤の次の一手 ~AI活用のために知っておくべき新潮流とは?~(NTTデータ テクノロジーカンファレンス 2020 発表資料)
by
NTT DATA Technology & Innovation
【講演資料】ビッグデータ時代の経営を支えるビジネスアナリティクスソリューション
by
Dell TechCenter Japan
利用者主体で行う分析のための分析基盤
by
Sotaro Kimura
並列分散処理基盤Hadoopの紹介と、開発者が語るHadoopの使いどころ (Silicon Valley x 日本 / Tech x Business ...
by
NTT DATA OSS Professional Services
Spark+AI Summit Europe 2019 セッションハイライト(Spark Meetup Tokyo #2 講演資料)
by
NTT DATA Technology & Innovation
データ分析基盤について
by
Yuta Inamura
Spark + AI Summit 2020セッションのハイライト(Spark Meetup Tokyo #3 Online発表資料)
by
NTT DATA Technology & Innovation
[db tech showcase Tokyo 2016] B31: Spark Summit 2016@SFに参加してきたので最新事例などを紹介しつつデ...
by
Insight Technology, Inc.
Spark SQL - The internal -
by
NTT DATA OSS Professional Services
R&D部門におけるデータ共有・利活用はなぜ難しいのか
by
恵 桂木
ils202202
by
恵 桂木
R&D部門におけるデータ共有・利活用はなぜ難しいのか
by
恵 桂木
R&D部門におけるデータ共有・利活用はなぜ難しいのか
by
恵 桂木
ils202202
by
恵 桂木
R&D部門におけるデータ共有・利活用はなぜ難しいのか
by
恵 桂木
変わる!? リクルートグループのデータ解析基盤
by
Recruit Technologies
ITインフラsummit 2017発表資料
by
Masayuki Hyugaji
データファースト開発
by
Katsunori Kanda
Devsumi 2016 b_4 KafkaとSparkを組み合わせたリアルタイム分析基盤の構築
by
Tanaka Yuichi
Yahoo! JAPANのデータ基盤とHadoop #dbts2016
by
Yahoo!デベロッパーネットワーク
More from NTT DATA OSS Professional Services
PDF
Global Top 5 を目指す NTT DATA の確かで意外な技術力
by
NTT DATA OSS Professional Services
PDF
Apache Kafkaって本当に大丈夫?~故障検証のオーバービューと興味深い挙動の紹介~
by
NTT DATA OSS Professional Services
PDF
Hadoopエコシステムのデータストア振り返り
by
NTT DATA OSS Professional Services
PDF
HDFS Router-based federation
by
NTT DATA OSS Professional Services
PDF
PostgreSQL10を導入!大規模データ分析事例からみるDWHとしてのPostgreSQL活用のポイント
by
NTT DATA OSS Professional Services
PDF
Apache Hadoopの新機能Ozoneの現状
by
NTT DATA OSS Professional Services
PDF
Distributed data stores in Hadoop ecosystem
by
NTT DATA OSS Professional Services
PDF
Structured Streaming - The Internal -
by
NTT DATA OSS Professional Services
PDF
Apache Hadoopの未来 3系になって何が変わるのか?
by
NTT DATA OSS Professional Services
PDF
Apache Hadoop and YARN, current development status
by
NTT DATA OSS Professional Services
PDF
HDFS basics from API perspective
by
NTT DATA OSS Professional Services
PDF
20170303 java9 hadoop
by
NTT DATA OSS Professional Services
PPTX
ブロックチェーンの仕組みと動向(入門編)
by
NTT DATA OSS Professional Services
PDF
Application of postgre sql to large social infrastructure jp
by
NTT DATA OSS Professional Services
PDF
Application of postgre sql to large social infrastructure
by
NTT DATA OSS Professional Services
PDF
商用ミドルウェアのPuppet化で気を付けたい5つのこと
by
NTT DATA OSS Professional Services
PPTX
今からはじめるPuppet 2016 ~ インフラエンジニアのたしなみ ~
by
NTT DATA OSS Professional Services
PDF
PostgreSQLでpg_bigmを使って日本語全文検索 (MySQLとPostgreSQLの日本語全文検索勉強会 発表資料)
by
NTT DATA OSS Professional Services
PDF
本当にあったHadoopの恐い話 Blockはどこへきえた? (Hadoop / Spark Conference Japan 2016 ライトニングトー...
by
NTT DATA OSS Professional Services
PDF
サポートメンバは見た! Hadoopバグワースト10 (adoop / Spark Conference Japan 2016 ライトニングトーク発表資料)
by
NTT DATA OSS Professional Services
Global Top 5 を目指す NTT DATA の確かで意外な技術力
by
NTT DATA OSS Professional Services
Apache Kafkaって本当に大丈夫?~故障検証のオーバービューと興味深い挙動の紹介~
by
NTT DATA OSS Professional Services
Hadoopエコシステムのデータストア振り返り
by
NTT DATA OSS Professional Services
HDFS Router-based federation
by
NTT DATA OSS Professional Services
PostgreSQL10を導入!大規模データ分析事例からみるDWHとしてのPostgreSQL活用のポイント
by
NTT DATA OSS Professional Services
Apache Hadoopの新機能Ozoneの現状
by
NTT DATA OSS Professional Services
Distributed data stores in Hadoop ecosystem
by
NTT DATA OSS Professional Services
Structured Streaming - The Internal -
by
NTT DATA OSS Professional Services
Apache Hadoopの未来 3系になって何が変わるのか?
by
NTT DATA OSS Professional Services
Apache Hadoop and YARN, current development status
by
NTT DATA OSS Professional Services
HDFS basics from API perspective
by
NTT DATA OSS Professional Services
20170303 java9 hadoop
by
NTT DATA OSS Professional Services
ブロックチェーンの仕組みと動向(入門編)
by
NTT DATA OSS Professional Services
Application of postgre sql to large social infrastructure jp
by
NTT DATA OSS Professional Services
Application of postgre sql to large social infrastructure
by
NTT DATA OSS Professional Services
商用ミドルウェアのPuppet化で気を付けたい5つのこと
by
NTT DATA OSS Professional Services
今からはじめるPuppet 2016 ~ インフラエンジニアのたしなみ ~
by
NTT DATA OSS Professional Services
PostgreSQLでpg_bigmを使って日本語全文検索 (MySQLとPostgreSQLの日本語全文検索勉強会 発表資料)
by
NTT DATA OSS Professional Services
本当にあったHadoopの恐い話 Blockはどこへきえた? (Hadoop / Spark Conference Japan 2016 ライトニングトー...
by
NTT DATA OSS Professional Services
サポートメンバは見た! Hadoopバグワースト10 (adoop / Spark Conference Japan 2016 ライトニングトーク発表資料)
by
NTT DATA OSS Professional Services
Recently uploaded
PDF
第21回 Gen AI 勉強会「NotebookLMで60ページ超の スライドを作成してみた」
by
嶋 是一 (Yoshikazu SHIMA)
PDF
100年後の知財業界-生成AIスライドアドリブプレゼン イーパテントYouTube配信
by
e-Patent Co., Ltd.
PDF
FY2025 IT Strategist Afternoon I Question-1 Balanced Scorecard
by
akipii ogaoga
PDF
Reiwa 7 IT Strategist Afternoon I Question-1 3C Analysis
by
akipii ogaoga
PDF
PMBOK 7th Edition_Project Management Process_WF Type Development
by
akipii ogaoga
PDF
自転車ユーザ参加型路面画像センシングによる点字ブロック検出における性能向上方法の模索 (20260123 SeMI研)
by
Yuto Matsuda
PDF
2025→2026宙畑ゆく年くる年レポート_100社を超える企業アンケート総まとめ!!_企業まとめ_1229_3版
by
sorabatake
PDF
Team Topology Adaptive Organizational Design for Rapid Delivery of Valuable S...
by
akipii ogaoga
PDF
ST2024_PM1_2_Case_study_of_local_newspaper_company.pdf
by
akipii ogaoga
PDF
Reiwa 7 IT Strategist Afternoon I Question-1 Ansoff's Growth Vector
by
akipii ogaoga
PDF
PMBOK 7th Edition Project Management Process Scrum
by
akipii ogaoga
PDF
PMBOK 7th Edition_Project Management Context Diagram
by
akipii ogaoga
PDF
Starlink Direct-to-Cell (D2C) 技術の概要と将来の展望
by
CRI Japan, Inc.
第21回 Gen AI 勉強会「NotebookLMで60ページ超の スライドを作成してみた」
by
嶋 是一 (Yoshikazu SHIMA)
100年後の知財業界-生成AIスライドアドリブプレゼン イーパテントYouTube配信
by
e-Patent Co., Ltd.
FY2025 IT Strategist Afternoon I Question-1 Balanced Scorecard
by
akipii ogaoga
Reiwa 7 IT Strategist Afternoon I Question-1 3C Analysis
by
akipii ogaoga
PMBOK 7th Edition_Project Management Process_WF Type Development
by
akipii ogaoga
自転車ユーザ参加型路面画像センシングによる点字ブロック検出における性能向上方法の模索 (20260123 SeMI研)
by
Yuto Matsuda
2025→2026宙畑ゆく年くる年レポート_100社を超える企業アンケート総まとめ!!_企業まとめ_1229_3版
by
sorabatake
Team Topology Adaptive Organizational Design for Rapid Delivery of Valuable S...
by
akipii ogaoga
ST2024_PM1_2_Case_study_of_local_newspaper_company.pdf
by
akipii ogaoga
Reiwa 7 IT Strategist Afternoon I Question-1 Ansoff's Growth Vector
by
akipii ogaoga
PMBOK 7th Edition Project Management Process Scrum
by
akipii ogaoga
PMBOK 7th Edition_Project Management Context Diagram
by
akipii ogaoga
Starlink Direct-to-Cell (D2C) 技術の概要と将来の展望
by
CRI Japan, Inc.
データ活用をもっともっと円滑に! ~データ処理・分析基盤編を少しだけ~
1.
Copyright © 2016
NTT DATA Corporation NTTデータ 技術革新統括本部 OSSプロフェッショナルサービス 土橋 昌 データ活用をもっともっと円滑に! ~データ処理・分析基盤編を少しだけ~ Spark Summit2016報告会&データ分析勉強会
2.
2Copyright © 2016
NTT DATA Corporation 自己紹介 土橋 昌 - Masaru Dobashi OSSを徹底活用したシステム開発やR&Dに従事。エンジニア。 7、8年前にHadoopに出会い、1000台超えのHadoopのシステ ムの開発・運用などを担う。当時の課題感からStorm、Sparkの 取り組みをはじめ現在に至る。 技術コンサルから現場開発、インフラからデータ処理、ゲテモノ から定番まで、捻じ伏せてどうにかするのがお仕事です。 等々 Spark Summit Strata Hadoop World
3.
3Copyright © 2016
NTT DATA Corporation 分析に関わるエンジニアと分析者が円滑に仕事するために、 データ処理基盤が押さえるべきポイントは?の話 なぜ分析に関して基盤のことを考えなくてはならないか? => 要であるデータはそこを通ってやってから。 プロダクト固有の話は省略 ポイントは色々ある中からピックアップして紹介 今日のお話
4.
Copyright © 2015
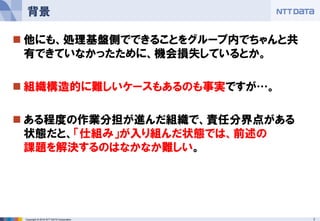
NTT DATA Corporation 4 背景
5.
5Copyright © 2016
NTT DATA Corporation データ活用の様々な現場で見てきた辛いやり取りの一例 背景
6.
6Copyright © 2016
NTT DATA Corporation データ活用の様々な現場で見てきた辛いやり取りの一例 背景 急だけど○○のデータ使いたいのだけ ど、すぐ出せない? やってみるよ。…あー、元データない かも?どうするかな HadoopとかSparkとか××とかで 一発で出せるよね? いや、HadoopやSparkや××も 万能じゃないし。 むしろ遅いときあるよね いつもの日次のバッチなんだけど、1 時間ごとにできないか?って聞かれれ たんだけど、どう? 処理は行けるかもしれないけど、そ もそも入力データって、たしか連携 先で自作した日次バッチで置いても らっているんじゃなかったかなぁ
7.
7Copyright © 2016
NTT DATA Corporation 他にも、処理基盤側でできることをグループ内でちゃんと共 有できていなかったために、機会損失しているとか。 組織構造的に難しいケースもあるのも事実ですが…。 ある程度の作業分担が進んだ組織で、責任分界点がある 状態だと、「仕組み」が入り組んだ状態では、前述の 課題を解決するのはなかなか難しい。 背景
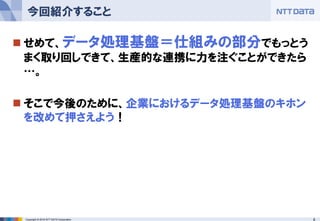
8.
8Copyright © 2016
NTT DATA Corporation せめて、データ処理基盤=仕組みの部分でもっとう まく取り回しできて、生産的な連携に力を注ぐことができたら …。 そこで今後のために、企業におけるデータ処理基盤のキホン を改めて押さえよう! 今回紹介すること
9.
Copyright © 2015
NTT DATA Corporation 9 分析のための処理基盤のキホン
10.
10Copyright © 2016
NTT DATA Corporation お手元のシステムで本観点で十分に機能していますか? ちなみに、Hadoop界隈でよく見られるキーワードを付記して みると… 結論:キホンは蓄積、処理、パイプラインを制すること 処理 蓄積 パイプライン Hadoop HDFS HBase Hive Hadoop MapReduce Spark Fluentd Embulk Kafka データの原石を加工して 価値のある情報をスムーズに 抽出するために最低限必要な要素は? 注:ここではデータを連携する仕 組み自体とします (やや狭義のパイプライン)
11.
11Copyright © 2016
NTT DATA Corporation これを突き詰めていくと最終的に、「データの基本セットを機 械的に生成」、「オンデマンドで必要なデータを生成」するため の環境が整う さらにデータマネジメント注の考え方と合わせて用いれば、管 理されたデータから必要なデータを取り出したり、生成するの が円滑になる。 …でも現実では、これを手堅く実現するのが意外とおざなり になるから大変だったりするわけですね 結論:キホンは蓄積、処理、パイプラインを制すること 注:ここでは単純に「データを価値のあるリソースとして管理するための規約」のこととします
12.
12Copyright © 2016
NTT DATA Corporation これを突き詰めていくと最終的に、「データの基本セットを機 械的に生成」、「オンデマンドで必要なデータを生成」するため の環境が整う さらにデータマネジメント注の考え方と合わせて用いれば、管 理されたデータから必要なデータを取り出したり、生成するの が円滑になる。 …でも現実では、これを手堅く実現するのが意外とおざなり になるから大変だったりするわけですね 結論:キホンは蓄積、処理、パイプラインを制すること 注:ここでは単純に「データを価値のあるリソースとして管理するための規約」のこととします このあたりの基本をおさえて調整 できるエンジニアと分析者が 組めるととても強力
13.
Copyright © 2015
NTT DATA Corporation 13 各観点のポイントをいくつか紹介 ポンポンポンと 紹介していきます。 別の場所でちゃんと 体系立てて説明したい。
14.
14Copyright © 2016
NTT DATA Corporation ログなどを扱う場合には、生データを溜めていざというときに 取り出せるようにしたい。 分析していると、ロジックの問題なのか元データの特徴なのか振り返 ることがある。「元データに原因があるか?」という検証をすることも 多々ある。また異なる分析処理に入れるために元があったほうが良 いことも多い。(異なる分析処理ではそれぞれ異なる解釈がある) ただし、ある程度活用先のスコープが絞れるならばスキーマ付データ ストアは当然強力。型を後でバリデートするのは大変…。 入力データだけでなく、中間データ、結果データも保存対象 になることが多い。したがって、必要な容量は意外と多いと 覚悟して検討をスタートするが良い。 蓄積のポイントの例(その1) 蓄積 処理 パイプ ライン
15.
15Copyright © 2016
NTT DATA Corporation 一方で、生成はもとより、削除、アーカイブ化にも注意 データストアは必ず容量が不足 or コストが問題化する。 容量見積もりが甘いから、という話もあるが、 現実的な問題として後から要件が追加されることは多い。 (分析業務においては) しばらく運用していると、もしかしたら「ごみの山」でいっぱいかも? でも、「ごみと認定するルール」は?オンデマンドの処理を許されたク ラスタでは利用度合いの可視化 & 強制対処も必要。 - データストアのユーザディレクトリの使用量可視化、計算リソースの使用量可視 化など アーカイブ化にも馬力が必要なことに注意。データ処理を前提として データストア(HDFSなど)に入れておかないと将来困る可能性がある。 蓄積のポイントの例(その2) 蓄積 処理 パイプ ライン
16.
16Copyright © 2016
NTT DATA Corporation 自分のワークロードで意図通り動くことを確認するのは大事 既存資料を参考にするにせよ、妄信するのは火傷の元…。 「コツ」と割り切って、本当に正しいかは手元で確認必要。 分散処理関連のOSSは、開発元の目的に特化したものが多い。 ハマれば非常に強いが、外したときの扱いづらさもなかなか大きい。 - 根本的に思ったような効果が得られないときは「もしかしたら使い方があっていな いのかも?」と考える思考も大事。 ログなどを扱う場合には、生データを加工、集計するための柔軟 な仕組みが欲しい。例えば前処理って大事。 複数の処理フレームワークで実現する方法は適材適所の利点 単一のフレームワークで実現する方法は取り回しのよさの利点 スケーラビリティが本当に必要かどうか?は重要な岐路。 結果としてPostgreSQL、Pythonなどのツールなどを採用するケースもある 処理のポイントの例(その1) 蓄積 処理 パイプ ライン
17.
17Copyright © 2016
NTT DATA Corporation 計画性は大事なのは前提だが、「試行錯誤」は残ると覚悟 試行錯誤するのに適した処理環境があると便利。 後発の分散処理(Sparkなど)はそれを意識したつくりになっている ただしリソース消費を読みづらい点から、リソース分離が鬼門になり がちなことに注意。最悪別環境で…とかも考える。そうすると後述の データパイプラインがキモになる。 「性能」、「汎用性」の間には直接の関係性はないが、トレード オフになることもあるから注意 蓄積する技術と比べて、処理するための技術は様々な趣向 が凝らされたプロダクトが生まれる傾向がある。様々な処理 系を実行できる環境があればベター。 処理のポイントの例(その2) 蓄積 処理 パイプ ライン
18.
18Copyright © 2016
NTT DATA Corporation 様々な場所からデータを届けるための仕掛けはとても重要 パイプライン前後のインターフェースや機能は、勝手に決めら れないことも多いうえに様々な種類があって大変。柔軟性に 富んだ仕組みにはコスト注 がかかる認識が必要。 外接部分はとにかく条件が複雑になりがちで心労も大きい…。 パイプラインのポイントの例(その1) 注:ここでいうコストは、稼働、金額などを含む広義のコスト 蓄積 処理 パイプ ライン
19.
19Copyright © 2016
NTT DATA Corporation 本当に柔軟性が必要ならメッセージングシステムなどを挟ん でリード・ライトのライフサイクルを分離する必要あり。 パイプラインにデータを流す頻度、速度に分析のサイクルが束縛され ることもあるから気が抜けない。 要求されるサイクルはビジネス要求によっても変化することに注意 データの利用者が複数になると、同じデータを異なるサイクルで消費 することもある。その目的でもメッセージングシステムを挟むのは有用 「高速に届ける。かつ、絶対に落とさないし、重複もしない」 という条件は、安易に合意するものではない。 結局のところ費用対効果の話に落ち着く。異常系発生時の影響を 考慮したうえで、やりすぎないように注意。「サービス(ビジネス)上は どんなインパクトがあるのか?」 パイプラインのポイントの例(その2) 蓄積 処理 パイプ ライン
20.
20Copyright © 2016
NTT DATA Corporation データ活用の様々な現場で見てきた辛いやり取りの一例 背景(再掲) 急だけど○○のデータ使いたいのだけ ど、すぐ出せない? やってみるよ。…あー、元データない かも?どうするかな HadoopとかSparkとか××とかで 一発で出せるよね? いや、HadoopやSparkや××も 万能じゃないし。 むしろ遅いときあるよね いつもの日次のバッチなんだけど、1 時間ごとにできないか?って聞かれれ たんだけど、どう? 処理は行けるかもしれないけど、そ もそも入力データって、たしか連携 先で自作した日次バッチで置いても らっているんじゃなかったかなぁ 蓄積 処理 パイプライン
21.
21Copyright © 2016
NTT DATA Corporation まとめ 多数のエンジニアや分析者が絡み、責任分界点があ る組織では複雑な仕組みが問題に拍車をかけること がある 仕組みを作るうえでのポイントを関係者間で認識し、 意図せずに問題を難しくしないように心がけたい 基本は、蓄積、処理、パイプライン。 注意点に気を付けて 「データの基本セットを機械的に 生成」、「オンデマンドで必要なデータを生成」する環 境を手にしよう そのあとは色々と希望に合わせて応用
22.
Copyright © 2011
NTT DATA Corporation Copyright © 2016 NTT DATA Corporation お問い合わせ先: 株式会社NTTデータ 技術革新統括本部 OSSプロフェッショナルサービス URL: http://oss.nttdata.co.jp/hadoop メール: hadoop@kits.nttdata.co.jp TEL: 050-5546-9000























































![[db tech showcase Tokyo 2016] B31: Spark Summit 2016@SFに参加してきたので最新事例などを紹介しつつデ...](https://cdn.slidesharecdn.com/ss_thumbnails/1oula7aqkczs8b8nxbbw-signature-52b95cf478429666da1eac73ad45213570cae72b7e57434c17b4c128f24099d3-poli-160722095519-thumbnail.jpg?width=640&height=640&fit=bounds)












































