文献情報
SajibDasguptaand VincentNg
Mine the Easy, Classify the Hard: A semi- Supervised Approach to Automatic Sentiment Classification
In Proceedings of the 47th Annual Meeting of the ACL and the 4th IJCNLP of the AFNLP, pp 701-709.
2009
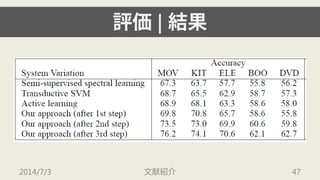
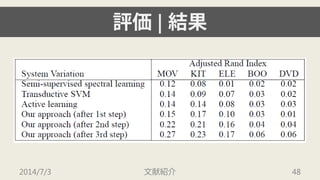
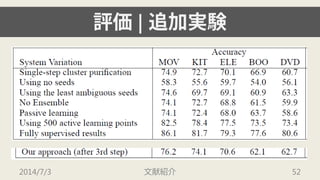
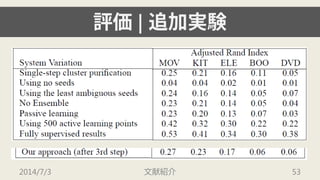
2014/7/3 文献紹介 2
























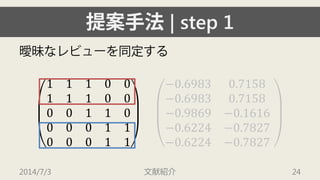
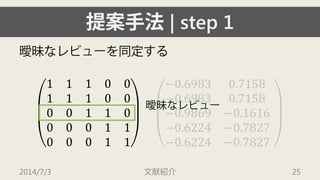






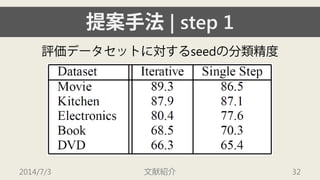
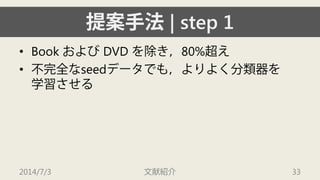




































![[XP祭り2015]野良LT~重音楽戦士特攻隊長の戯言~(公開版)](https://cdn.slidesharecdn.com/ss_thumbnails/random-150913014953-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会] “Asymmetric Tri-training for Unsupervised Domain Adaptation (ICML2017...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks20170728-170728025901-thumbnail.jpg?width=640&height=640&fit=bounds)






































