Downloaded 277 times









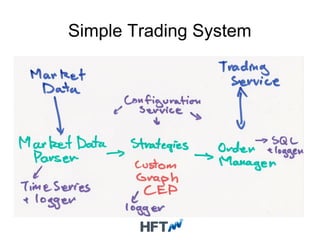



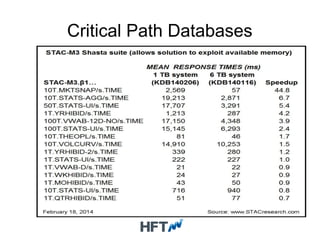















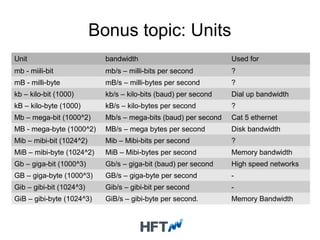


This document discusses high frequency trading systems and the requirements and technologies used, including: - HFT systems require extremely low latency databases (microseconds) and event-driven processing to minimize latency. - OpenHFT provides low-latency logging and data storage technologies like Chronicle and HugeCollections for use in HFT systems. - Chronicle provides microsecond-latency logging and replication between processes. HugeCollections provides high-throughput concurrent key-value storage with microsecond-level latencies. - These technologies are useful for critical data in HFT systems where traditional databases cannot meet the latency and throughput requirements.












































































![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)










