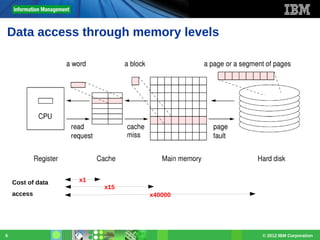
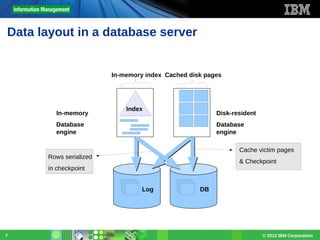
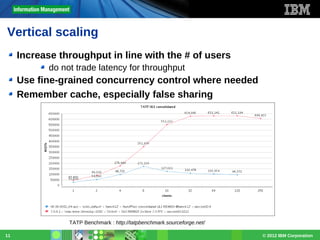
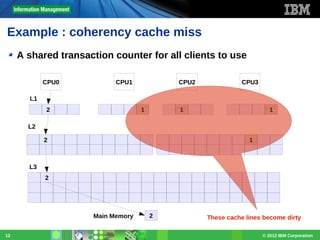
Download as PDF, PPTX









![Example : false sharing
Independent data share a cache line
Remember spatial locality, avoid false sharing
Update t1 set name='fo' where id=1
Select * from t1 where id=2
CPU1
CPU0
L1
[1, 'foo'],[2,'bar']
[1, 'fo'],[2,'bar']
[1, 'foo'],[2,'bar']
Whole cache line becomes dirty
Main Memory
[1, 'foo'],[2,'bar']
[1, 'fo'],[2,'bar']
Cache line – unit of transfer
13
© 2012 IBM Corporation](https://image.slidesharecdn.com/vilhoraatikkakalvot-131104021230-phpapp02/85/In-Memory-Databases-Trends-and-Technologies-2012-13-320.jpg)





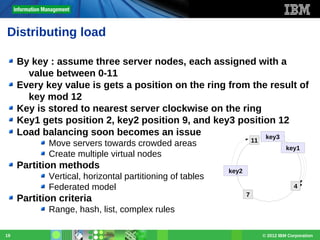


This document discusses the trends and technologies surrounding in-memory databases (IMDB), highlighting their advantages over traditional disk-based databases, such as reduced latency and improved performance due to faster RAM access. It addresses challenges in maximizing throughput and maintaining ACID properties while scaling out systems, and also emphasizes the importance of low latencies for application responsiveness. Various technical strategies, including log writing, checkpointing, and load distribution, are explored to optimize IMDB performance.





![[IC Manage] Workspace Acceleration & Network Storage Reduction](https://cdn.slidesharecdn.com/ss_thumbnails/workspace-acceleration-ic-manage-paper-130524110237-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)







































![Kb 40 kevin_klineukug_reading20070717[1]](https://cdn.slidesharecdn.com/ss_thumbnails/kb40kevinklineukugreading200707171-101026100915-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)




















