Download as ODP, PPTX
































![How does it perform?
On this laptop
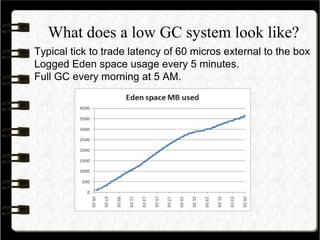
[GC 15925K->5838K(120320K), 0.0132370 secs]
[Full GC 5838K->5755K(120320K), 0.0521970 secs]
Started
processed 0
processed 1000000
Processed 2000000
… deleted …
processed 9000000
processed 10000000
Received 10000000
Processed 10,000,000 events in and out in 20.2 seconds
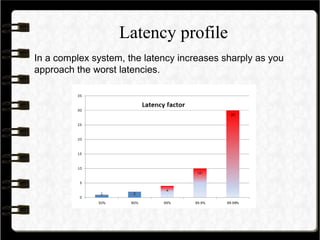
The latency distribution was 0.6, 0.7/2.7, 5/26 (611) us for the
50, 90/99, 99.9/99.99 %tile, (worst)
On an i7 desktop
Processed 10,000,000 events in and out in 20.0 seconds
The latency distribution was 0.3, 0.3/1.6, 2/12 (77) us for the
50, 90/99, 99.9/99.99 %tile, (worst)](https://image.slidesharecdn.com/writingandtestinghighfrequencytradingenginesinjava-130926073124-phpapp02/85/Writing-and-testing-high-frequency-trading-engines-in-java-37-320.jpg)


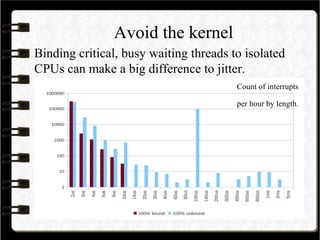
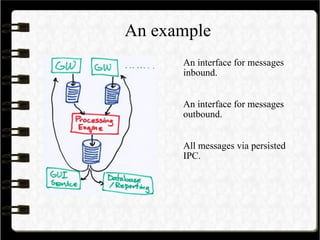
The document details the design and implementation of a high-frequency trading engine using Java, focusing on achieving low latency and high throughput. Key concepts include event-driven architecture, low garbage collection practices, and efficient memory management, highlighting the importance of minimizing operational delays and understanding latency profiles. The use of specialized libraries such as OpenHFT is emphasized for achieving optimal performance in trading applications.











































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)



