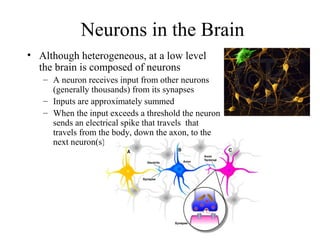
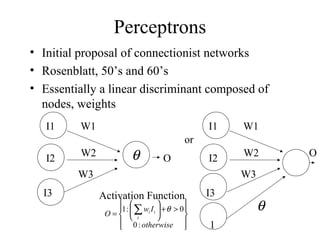
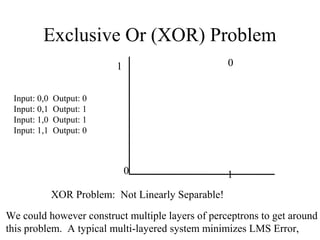
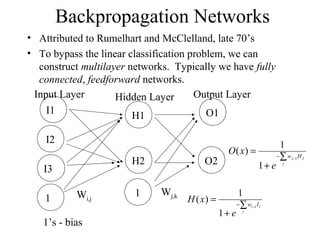
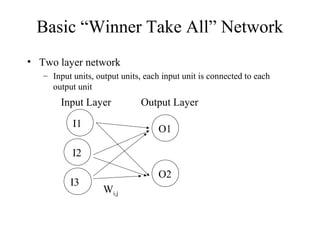
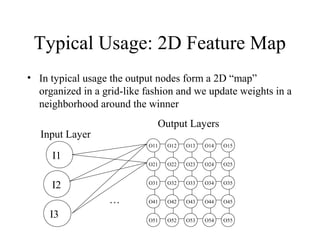
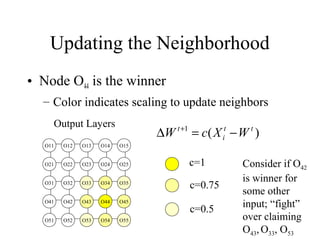
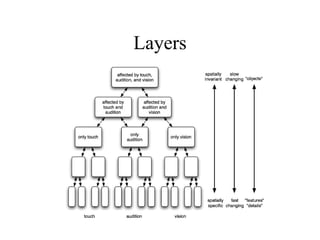
The document provides an introduction to neural networks, detailing connectionism as a computational model inspired by the brain's structure and functioning. It covers the history, types, and applications of neural networks, including perceptrons, backpropagation, and unsupervised learning methods like Hopfield networks and self-organizing maps. The text also discusses various learning mechanisms, the comparison of neural networks to traditional computers, and the philosophical debates surrounding cognitive abilities and consciousness in relation to neural models.











![LMS Learning
LMS = Least Mean Square learning Systems, more general than the
previous perceptron learning rule. The concept is to minimize the total
error, as measured over all training examples, P. O is the raw output,
as calculated by
( )∑ −=
P
PP OTLMSceDis
2
2
1
)(tan
E.g. if we have two patterns and
T1=1, O1=0.8, T2=0, O2=0.5 then D=(0.5)[(1-0.8)2
+(0-0.5)2
]=.145
We want to minimize the LMS:
E
W
W(old)
W(new)
C-learning rate
∑ +
i
ii Iw θ](https://image.slidesharecdn.com/nn-180821140513/85/Neutral-Network-14-320.jpg)




























































































![ONFH[AVN HIP] -TRIPLE REGIME -A NOVAL SURGICAL CONCEPT .pptx](https://cdn.slidesharecdn.com/ss_thumbnails/onfhavnhip2026koaconcalicutdrgokuldevdrmashraf-260210064517-213ec005-thumbnail.jpg?width=640&height=640&fit=bounds)






