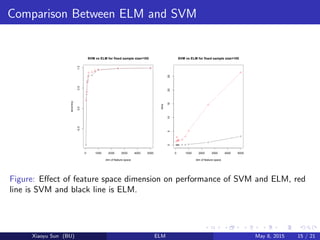
The document compares the performance of extreme learning machine (ELM) and support vector machines (SVM) in classification tasks. It finds that ELM achieves comparable or better accuracy than SVM and LS-SVM on cancer classification data, while being significantly faster. ELM requires less human intervention than SVMs since its hidden node parameters are randomly assigned rather than optimized. While ELM often has lower computational complexity than SVMs for large datasets, more analysis is needed to understand its behavior with different network sizes and datasets.

![Multiple Feed-forward Perceptrons Nerual Networks
Figure: A simple feed-forward perceptron with 8 input units, 2 layers of hidden
units, and 1 output unit. The gray-shading of the vector entries reflects their
numeric value. Cortes and Vapnik [1]
Xiaoyu Sun (BU) ELM May 8, 2015 2 / 21](https://image.slidesharecdn.com/cfe63e1b-6c4f-4f7c-bc28-40c899b4bff7-151110011335-lva1-app6891/85/elm-2-320.jpg)
![Support Vector Networks
Figure: SVM can be considered as a specific type of single-hidden-layer
feed-forward network(SLFN). Cortes and Vapnik [1]
Xiaoyu Sun (BU) ELM May 8, 2015 3 / 21](https://image.slidesharecdn.com/cfe63e1b-6c4f-4f7c-bc28-40c899b4bff7-151110011335-lva1-app6891/85/elm-3-320.jpg)