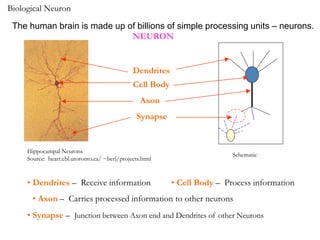
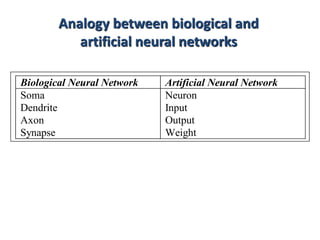
1. Neural networks are inspired by biological neural networks in the brain and are made up of simple processing units called neurons.
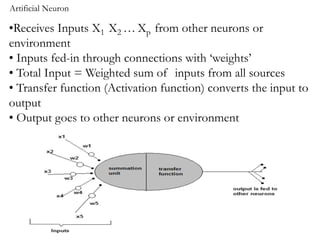
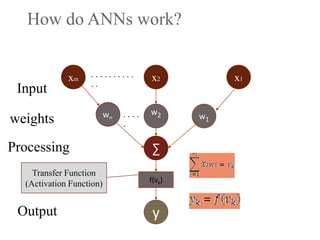
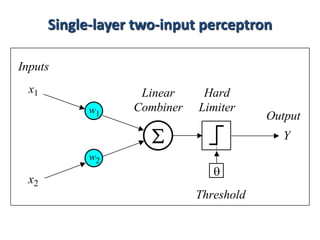
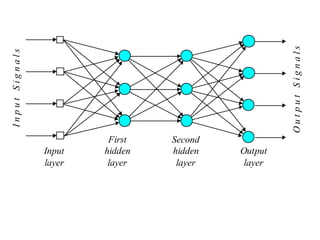
2. Artificial neural networks use a layer of input neurons that receive information and pass it through connections to other neurons.
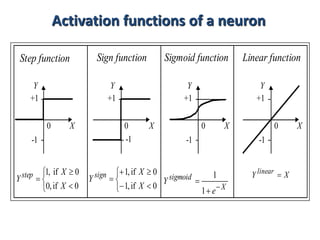
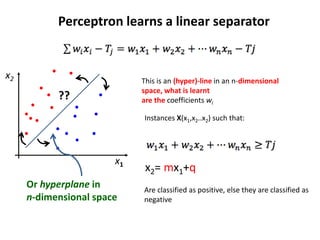
3. A neural network learns through a process of trial and error adjustment of the weights between neurons to minimize errors between the network's output and the desired output.









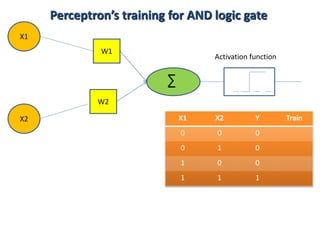
![Step 1: Initialisation
Set initial weights w1, w2,…, wn and threshold
to random numbers in the range [0.5, 0.5].
If the error, e(p), is positive, we need to increase
perceptron output Y(p), but if it is negative, we
need to decrease Y(p).
Perceptron’s training algorithm](https://image.slidesharecdn.com/raufasadov-neuralnetwork-180617134713/85/Neural-network-17-320.jpg)



































































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)


















