Download as PDF, PPTX


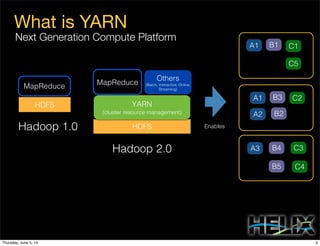
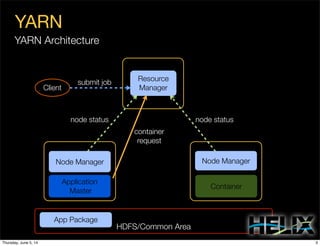

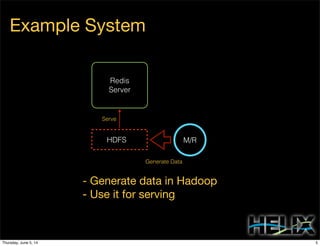
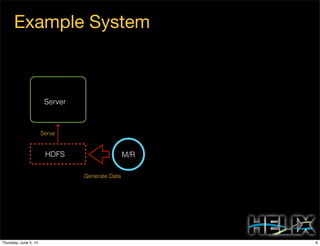
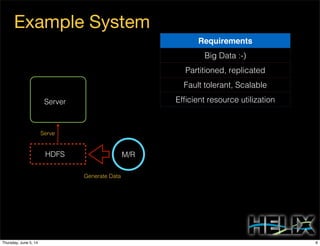
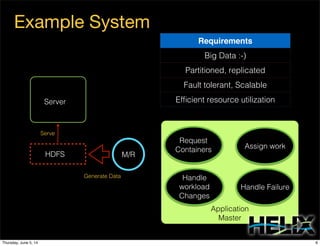
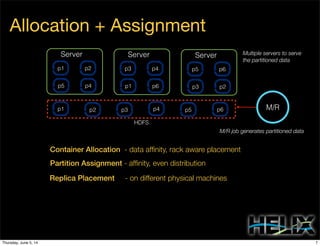







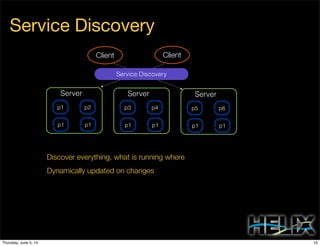
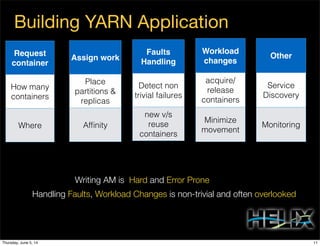



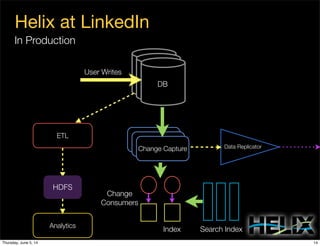



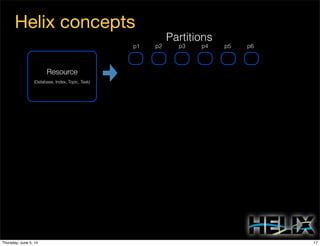

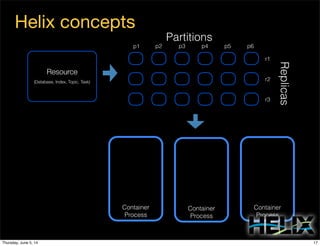
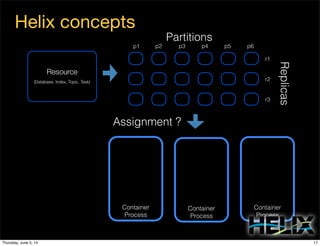

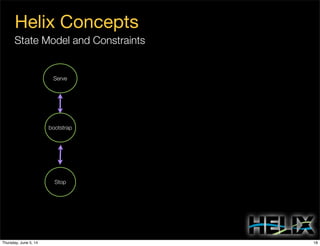
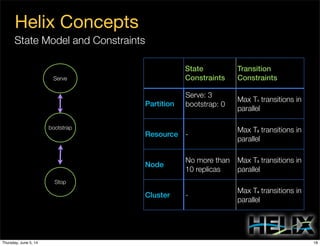
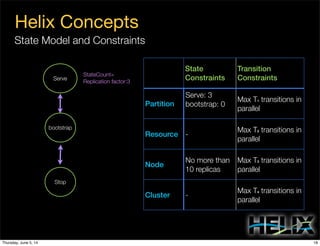
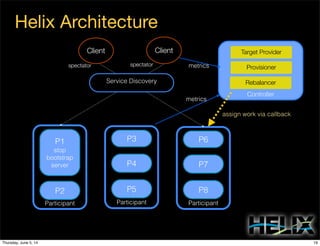
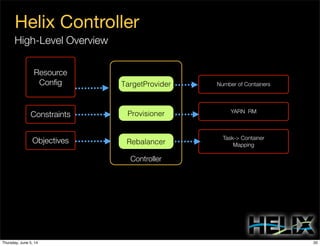
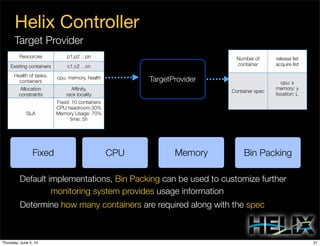

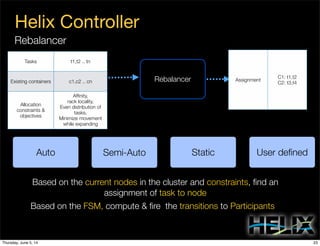
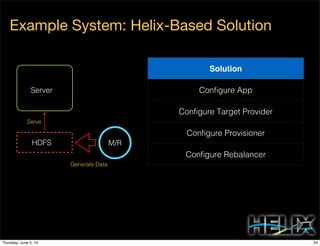




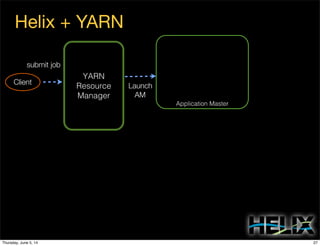
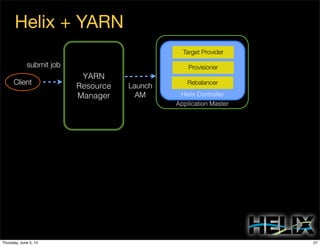
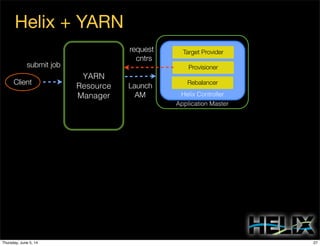
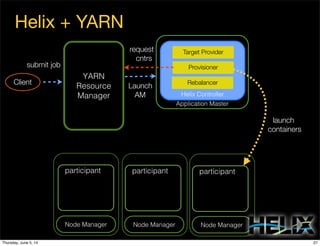
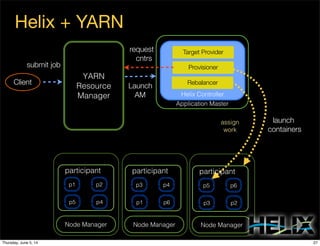
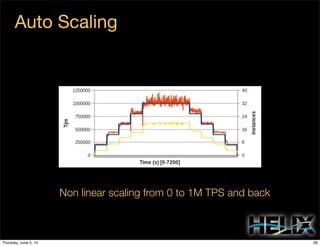
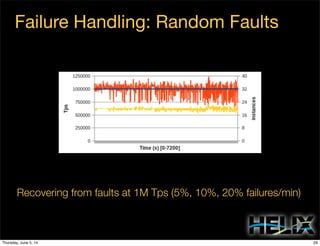



This document discusses using Apache Helix and YARN to build a multi-tenant data cloud. It describes Helix as a generic cluster management framework that handles tasks like resource partitioning, replica placement, workload balancing, and failure handling. The document provides an example of using Helix to build an application on YARN that generates and serves partitioned data from HDFS in a fault-tolerant and scalable way. Key components of Helix like the controller, target provider, provisioner, and rebalancer are overviewed.

















![[Hadoop Meetup] Apache Hadoop 3 community update - Rohith Sharma](https://cdn.slidesharecdn.com/ss_thumbnails/apachehadoop3communityupdate-rohith-171222071357-thumbnail.jpg?width=640&height=640&fit=bounds)





































































