Download as PDF, PPTX









![Helix Concepts
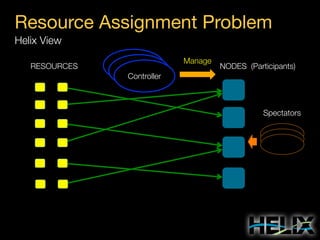
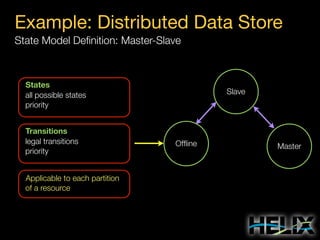
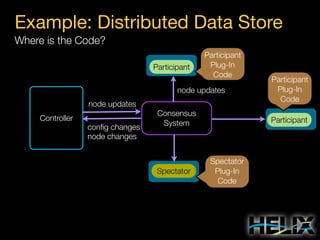
Constraints: Augmenting the State Model
State Constraints
MASTER: [1, 1]
SLAVE: [0, R]
Special Constraint Values
R: Replica count per partition
N: Number of participants](https://image.slidesharecdn.com/helixtalk-131017170712-phpapp02/85/Helix-talk-at-RelateIQ-20-320.jpg)
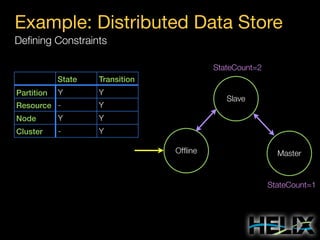
![Helix Concepts
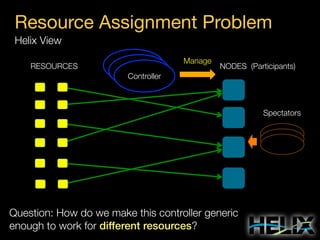
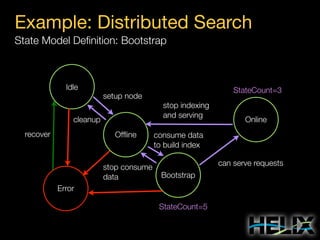
Constraints: Augmenting the State Model
State Constraints
MASTER: [1, 1]
SLAVE: [0, R]
Special Constraint Values
R: Replica count per partition
N: Number of participants
Transition Constraints
Scope: Cluster
OFFLINE-SLAVE: 3 concurrent
Scope: Resource R1
SLAVE-MASTER: 1 concurrent
Scope: Participant P4
OFFLINE-SLAVE: 2 concurrent](https://image.slidesharecdn.com/helixtalk-131017170712-phpapp02/85/Helix-talk-at-RelateIQ-21-320.jpg)
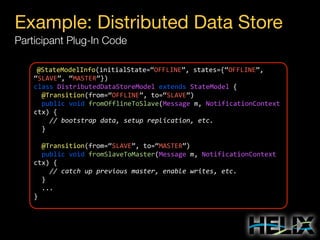
![Helix Concepts
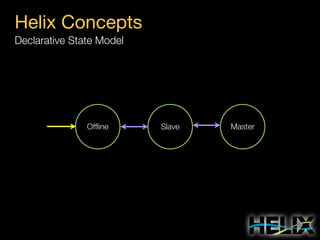
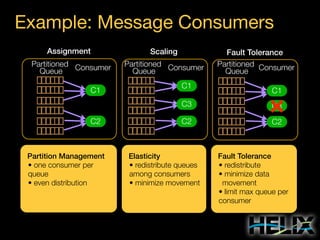
Constraints: Augmenting the State Model
State Constraints
MASTER: [1, 1]
SLAVE: [0, R]
Special Constraint Values
R: Replica count per partition
N: Number of participants
Transition Constraints
Scope: Cluster
OFFLINE-SLAVE: 3 concurrent
Scope: Resource R1
SLAVE-MASTER: 1 concurrent
Scope: Participant P4
OFFLINE-SLAVE: 2 concurrent
States and transitions are ordered by priority in computing replica states.
Transition constraints can be restricted to cluster, resource, and
participant scopes. The most restrictive constraint is used.](https://image.slidesharecdn.com/helixtalk-131017170712-phpapp02/85/Helix-talk-at-RelateIQ-22-320.jpg)












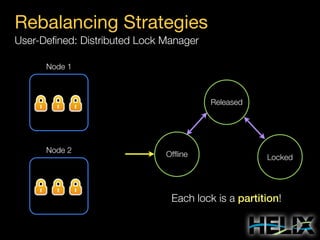
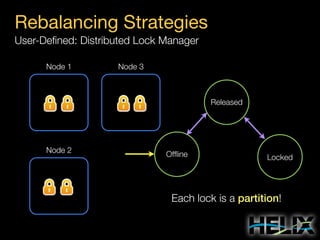


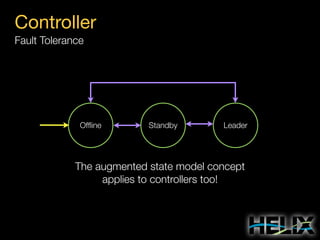
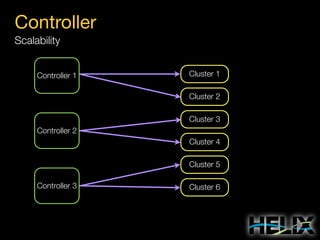
















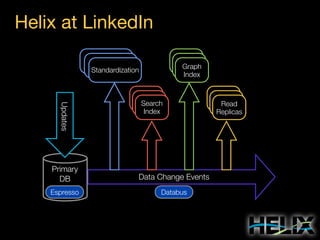





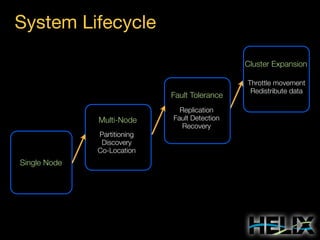
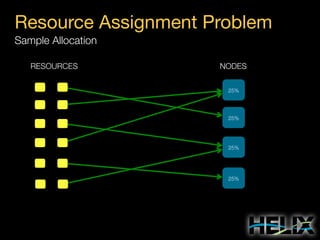
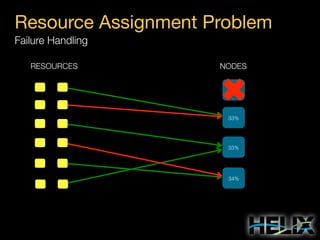
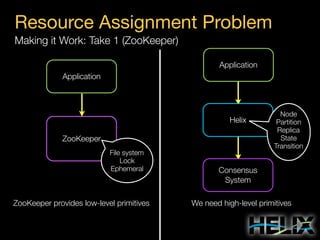
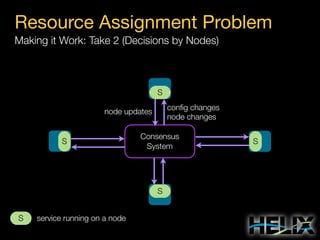
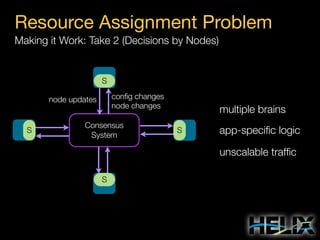
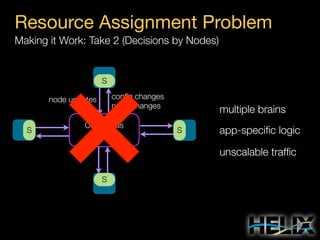
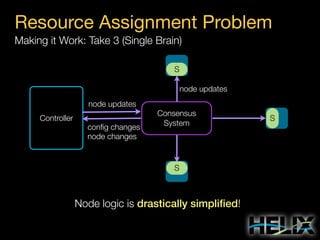
This document provides an overview of Apache Helix, which is a platform for building distributed systems. It discusses common problems that distributed systems need to solve, such as resource assignment, load balancing, and responding to node failures. It then introduces Helix concepts like resources, partitions, states, and constraints. It describes how Helix uses a controller and participants to manage replica placement and state transitions. It also covers rebalancing strategies and how applications can customize behavior. Finally, it provides examples of using Helix to implement a distributed data store. In summary, Helix aims to simplify building distributed systems by abstracting away common problems and providing a generic platform for managing resources and nodes.





















![[社内勉強会]ELBとALBと数万スパイク負荷テスト](https://cdn.slidesharecdn.com/ss_thumbnails/elbalb-160822022623-thumbnail.jpg?width=640&height=640&fit=bounds)



































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)
















