


















![Fluent API (0.13 release)
public class PageViewCounterExample implements StreamApplication {
@Override
public void init(StreamGraph graph, Config config) {
MessageStream<PageViewEvent> pageViewEvents = graph.createInputStream(“myinput”);
MessageStream<MyStreamOutput> outputStream = graph.createOutputStream(“myoutput”);
pageViewEvents.
partitionBy(m -> m.getMessage().memberId).
window(Windows.<PageViewEvent, String, Integer> keyedTumblingWindow(m ->
m.getMessage().memberId, Duration.ofSeconds(10), (m, c) -> c + 1).
map(MyStreamOutput::new).
sendTo(outputStream);
}
public static void main(String[] args) throws Exception {
CommandLine cmdLine = new CommandLine();
Config config = cmdLine.loadConfig(cmdLine.parser().parse(args));
ApplicationRunner localRunner = ApplicationRunner.getLocalRunner(config);
localRunner.run(new PageViewCounterExample());
}
}](https://image.slidesharecdn.com/joelandkarthikdataprocessinglinkedin-170524202610/85/Kafka-Summit-NYC-2017-Data-Processing-at-LinkedIn-with-Apache-Kafka-52-320.jpg)


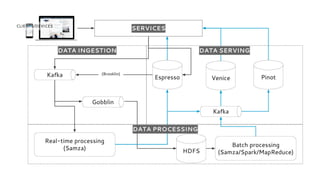



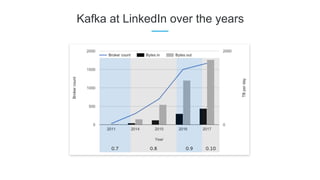
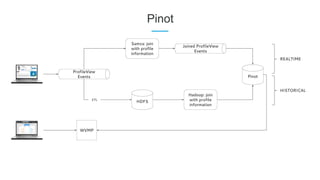
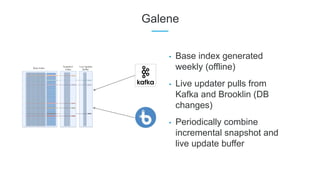
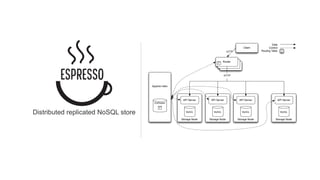
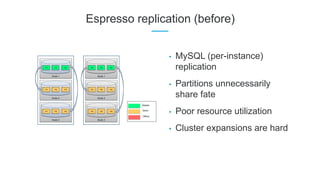
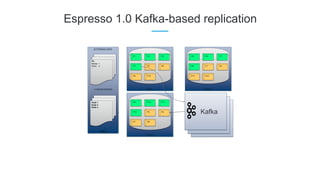
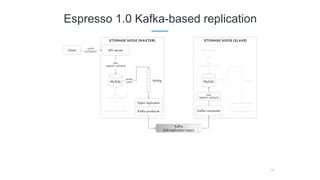
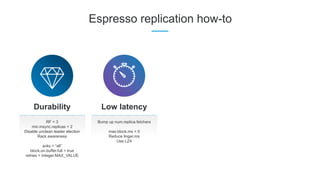
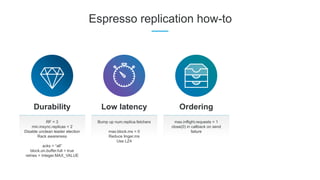
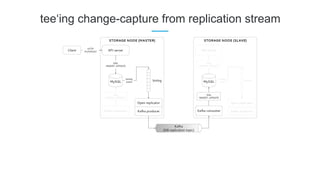
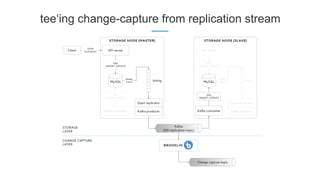
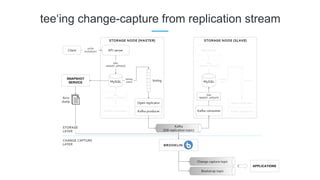
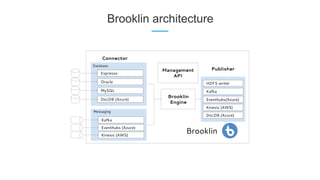
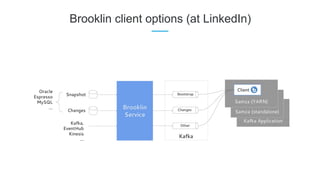
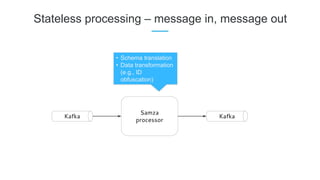
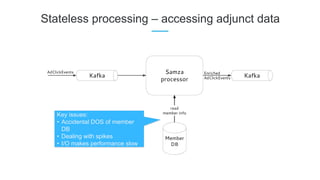
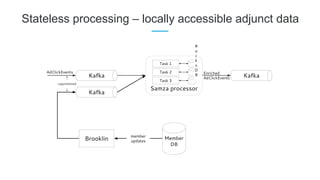
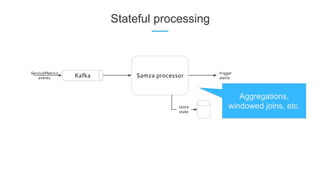
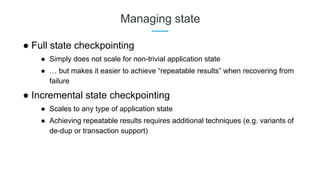
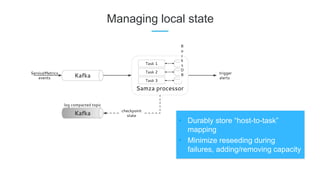
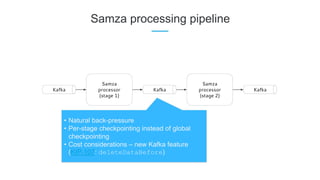
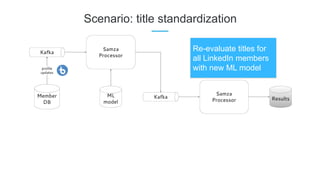
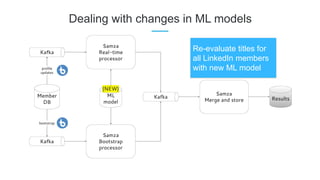
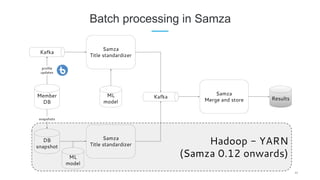
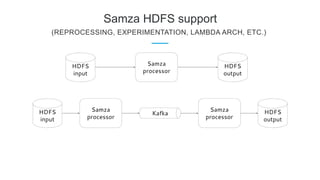
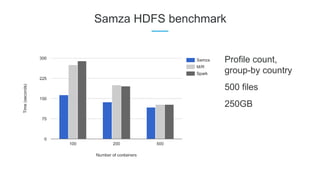
LinkedIn uses Apache Kafka extensively to power various data pipelines and platforms. Some key uses of Kafka include: 1) Moving data between systems for monitoring, metrics, search indexing, and more. 2) Powering the Pinot real-time analytics query engine which handles billions of documents and queries per day. 3) Enabling replication and partitioning for the Espresso NoSQL data store using a Kafka-based approach. 4) Streaming data processing using Samza to handle workflows like user profile evaluation. Samza is used for both stateless and stateful stream processing at LinkedIn.










































































![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)











![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)
