Download to read offline



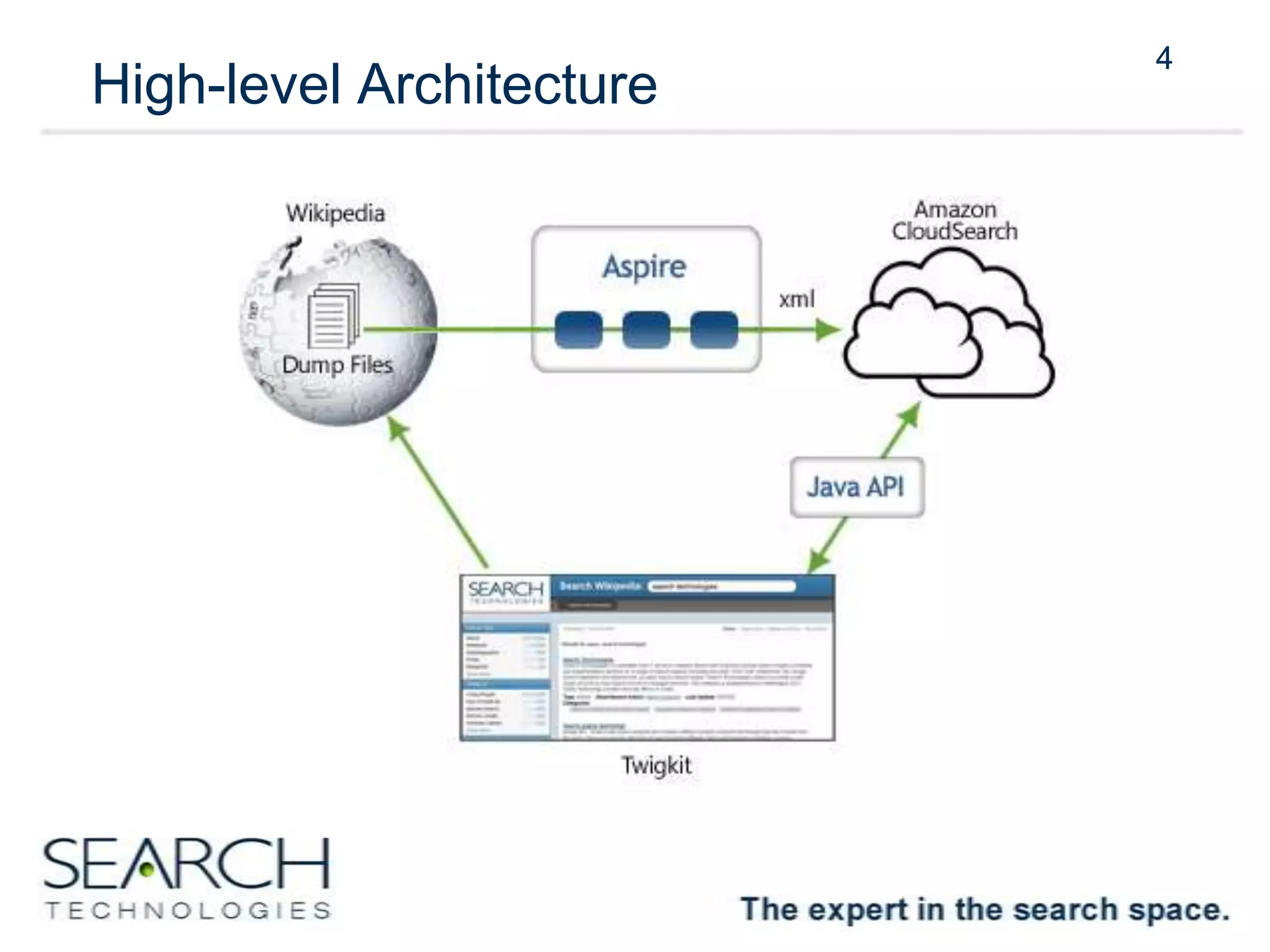






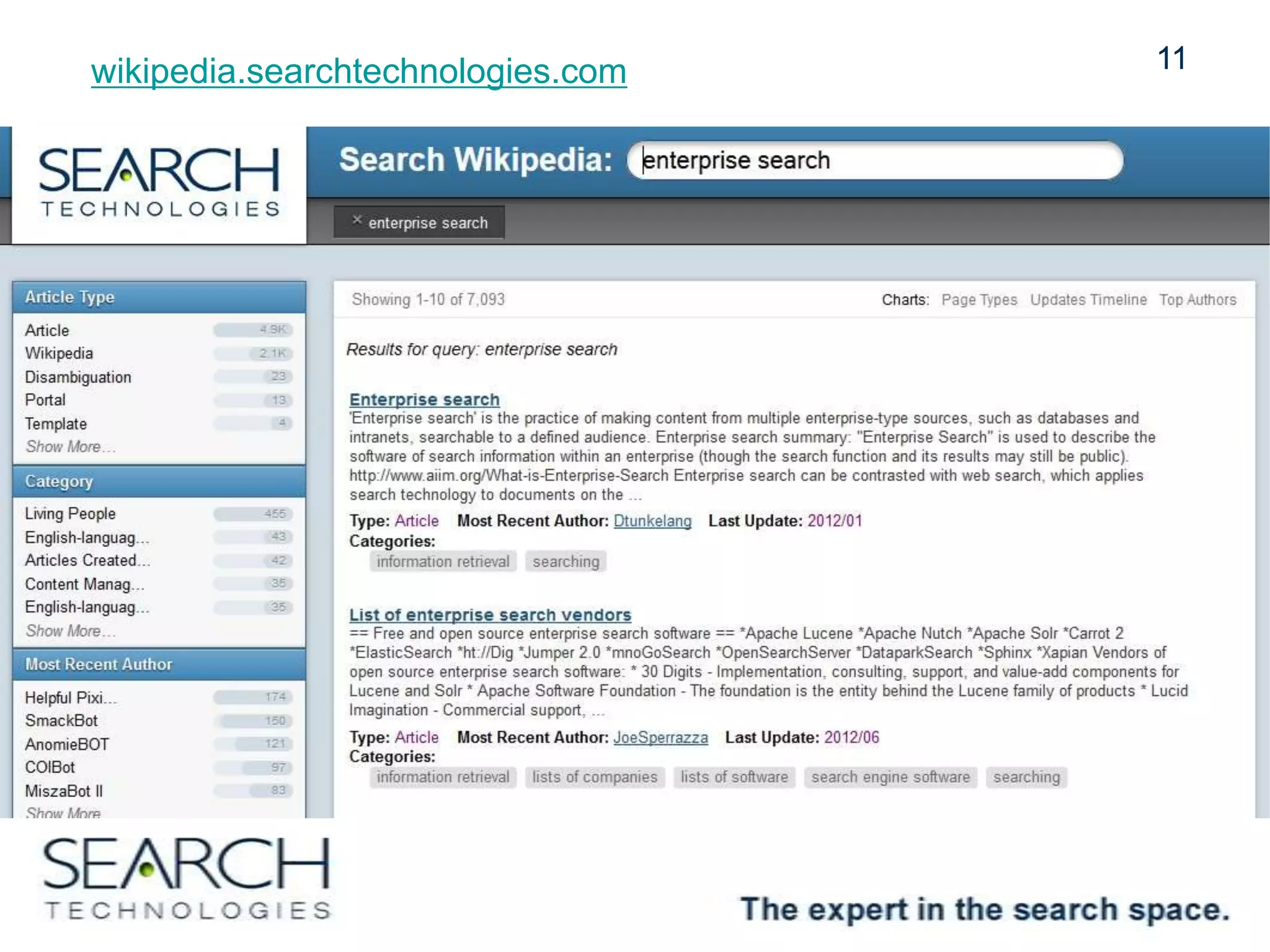
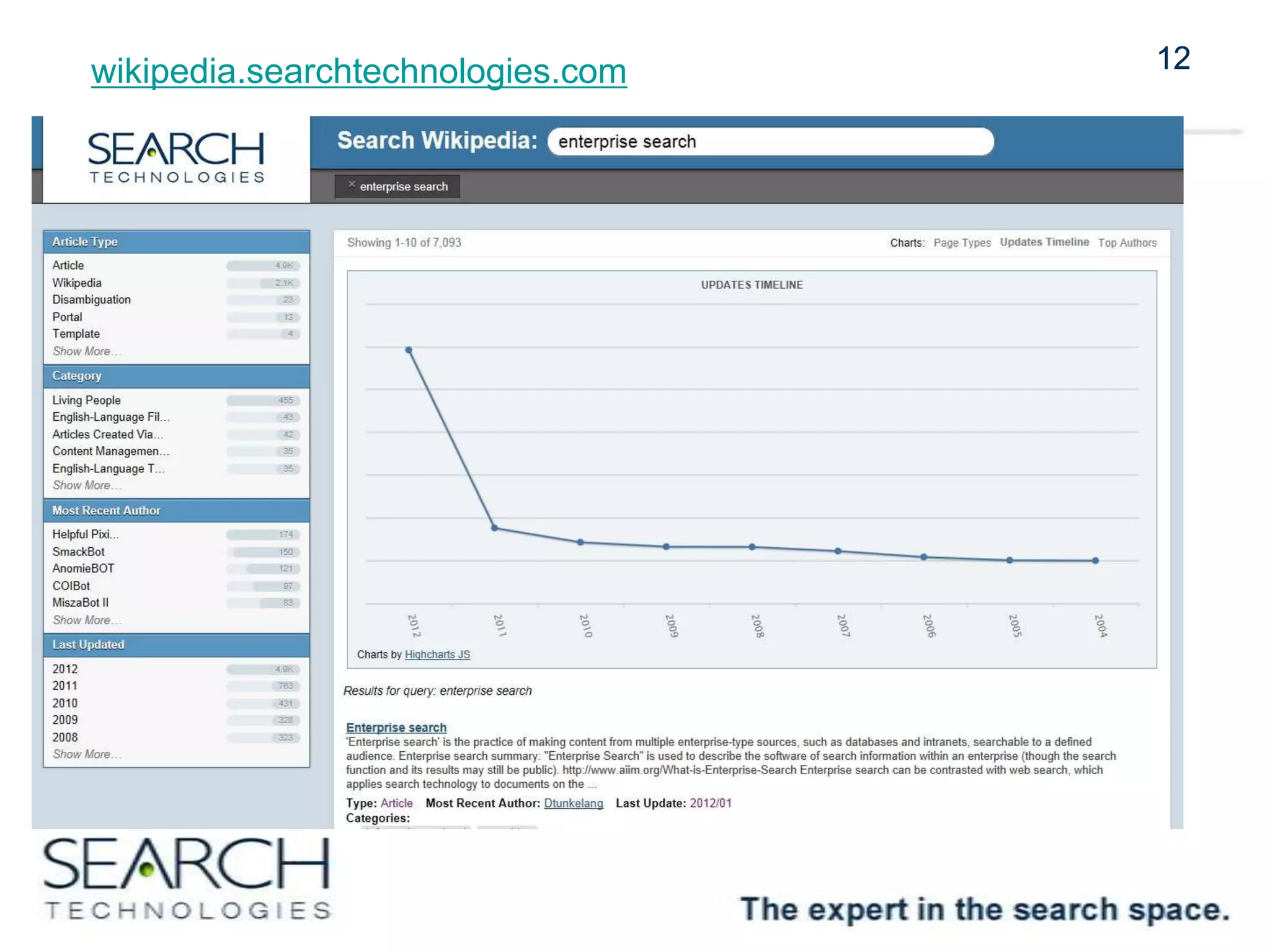




Amazon CloudSearch was beta-tested using Wikipedia as a data set, focusing on a high-level architecture that includes XML ingestion and various content processing tasks. The indexing process achieved 500 documents per second, utilizing cloud infrastructure efficiently, while a custom Java API facilitated user interface development for search capabilities. The project demonstrated cost-effectiveness and scalability, encouraging experimentation and agile usage.

















































































