Download as PDF, PPTX



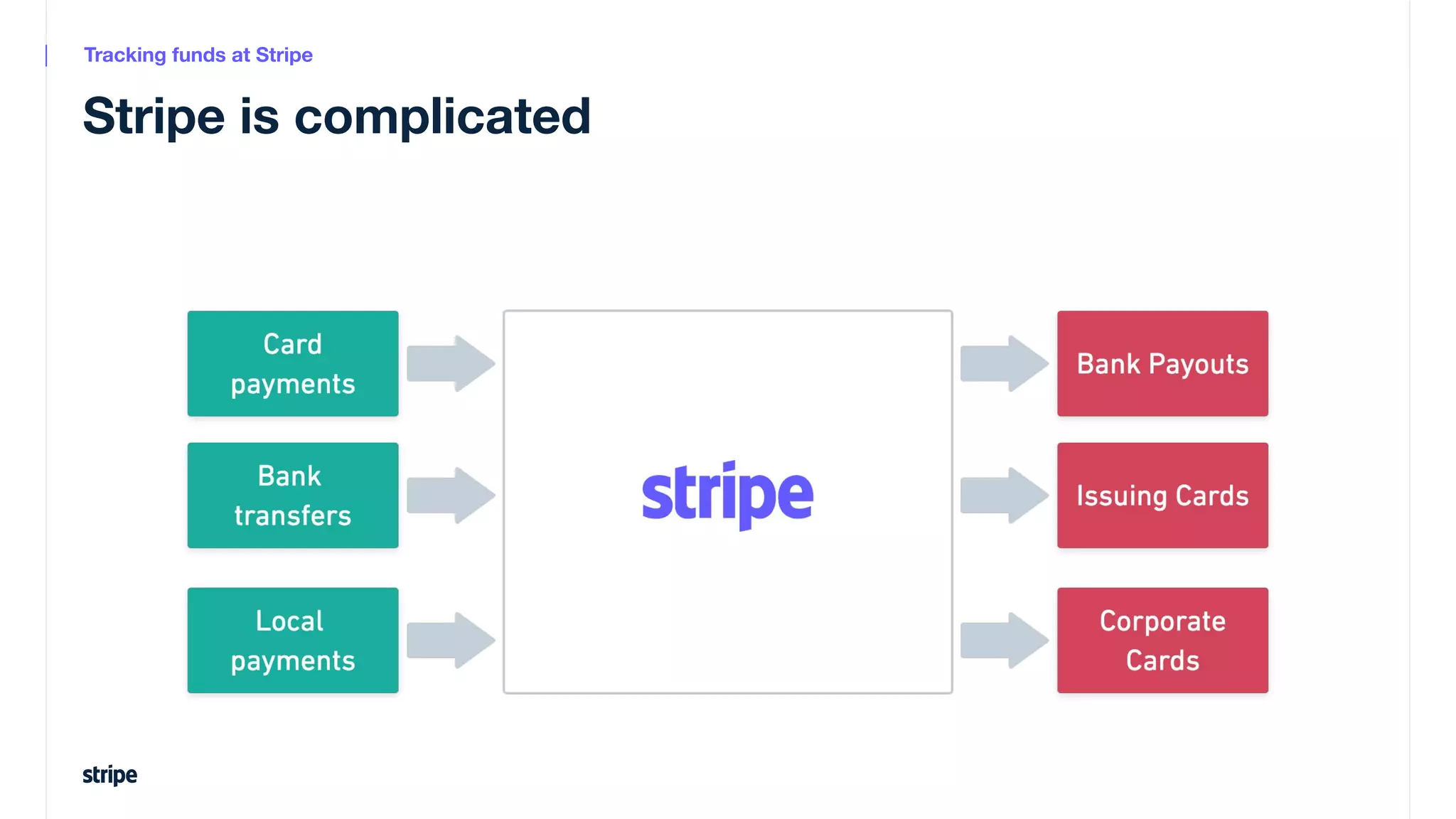
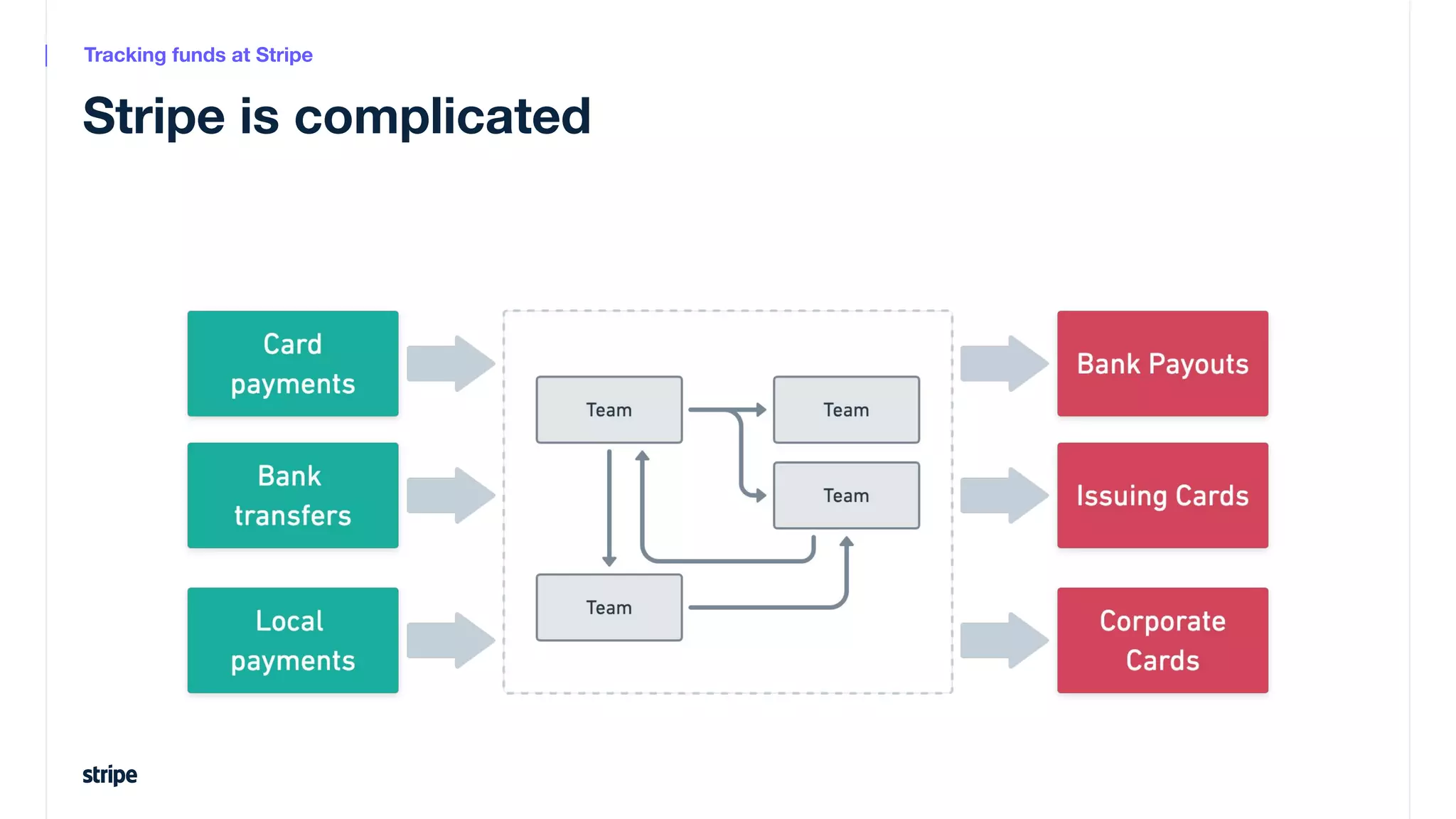
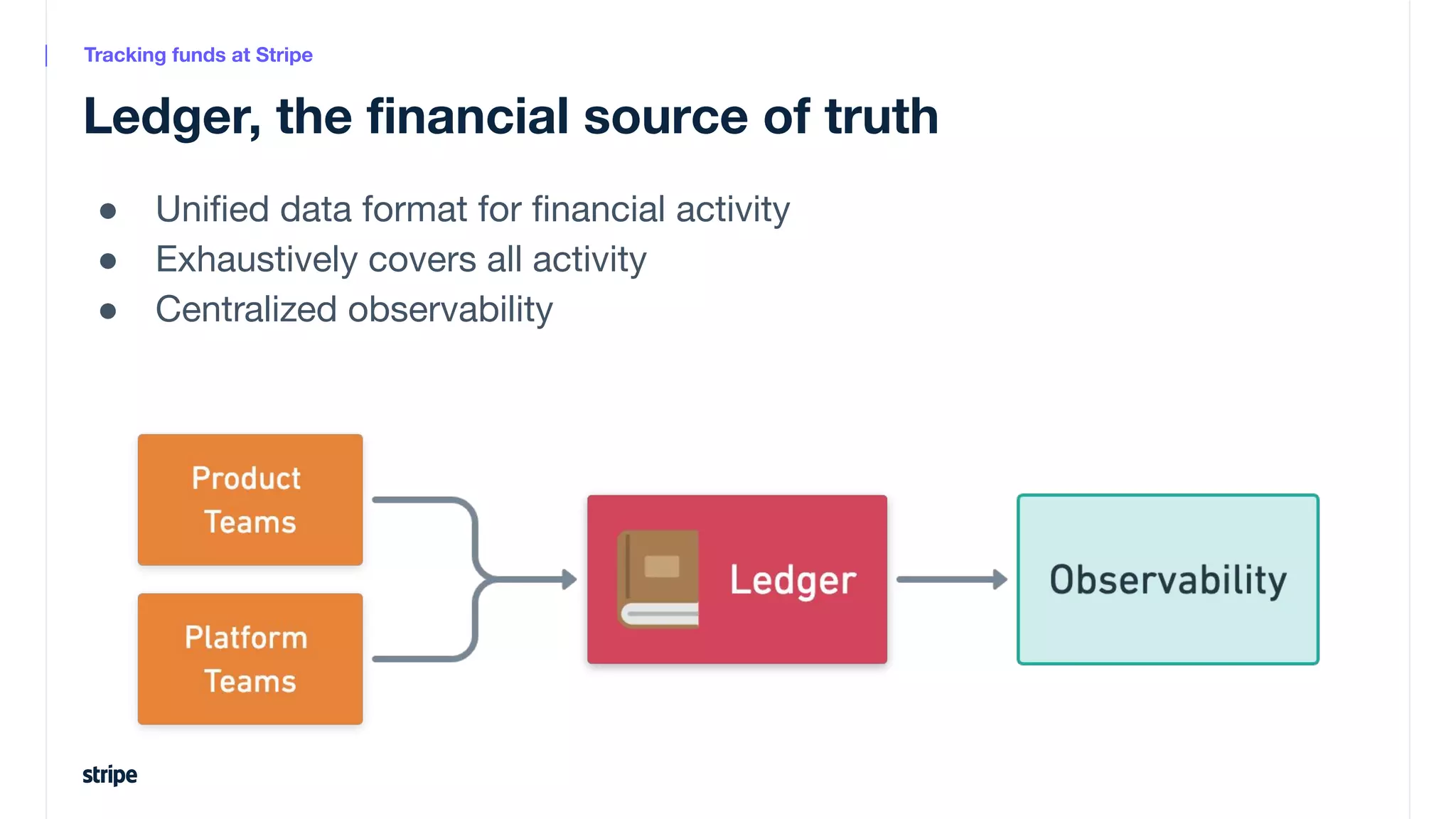
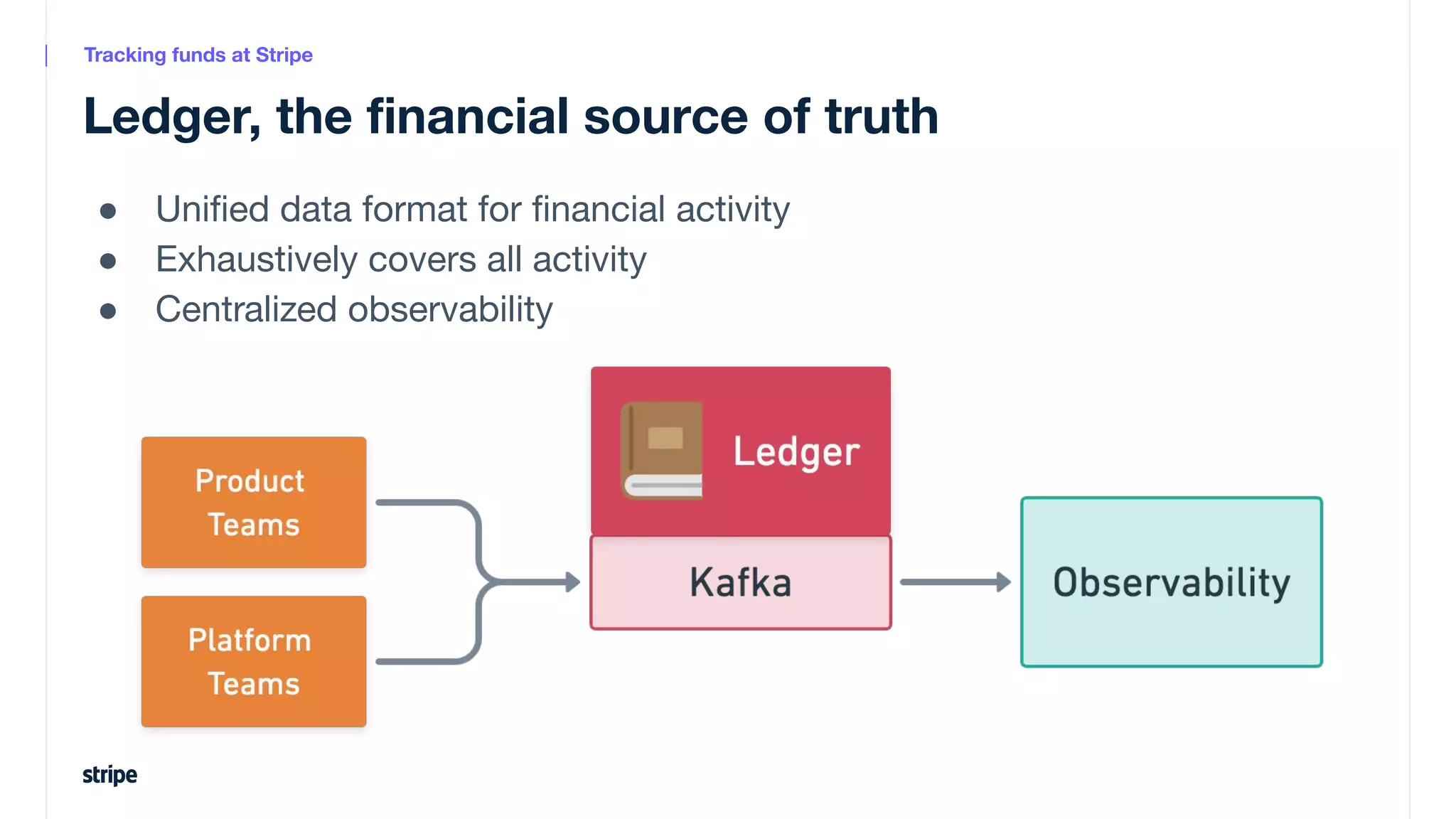

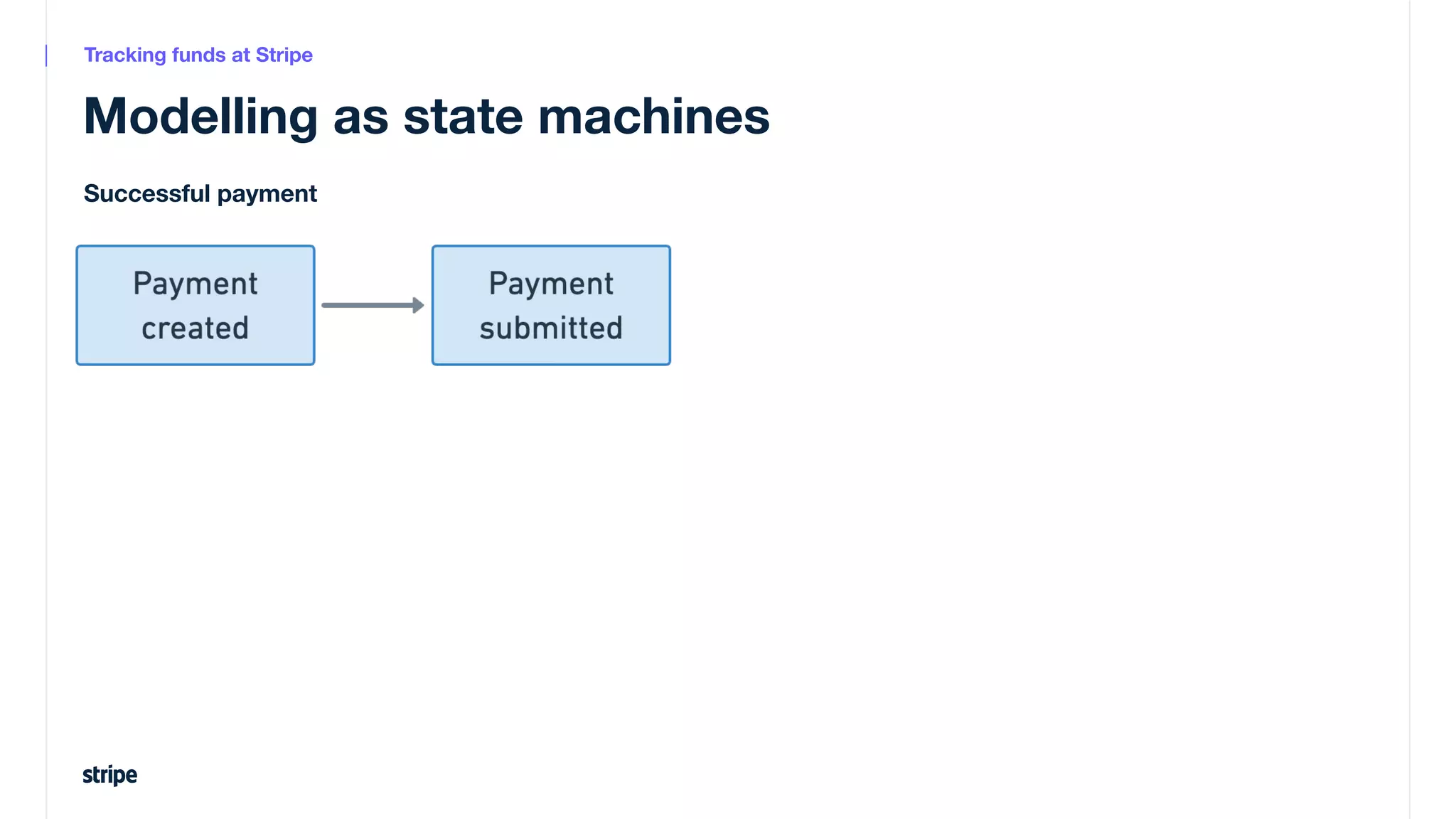
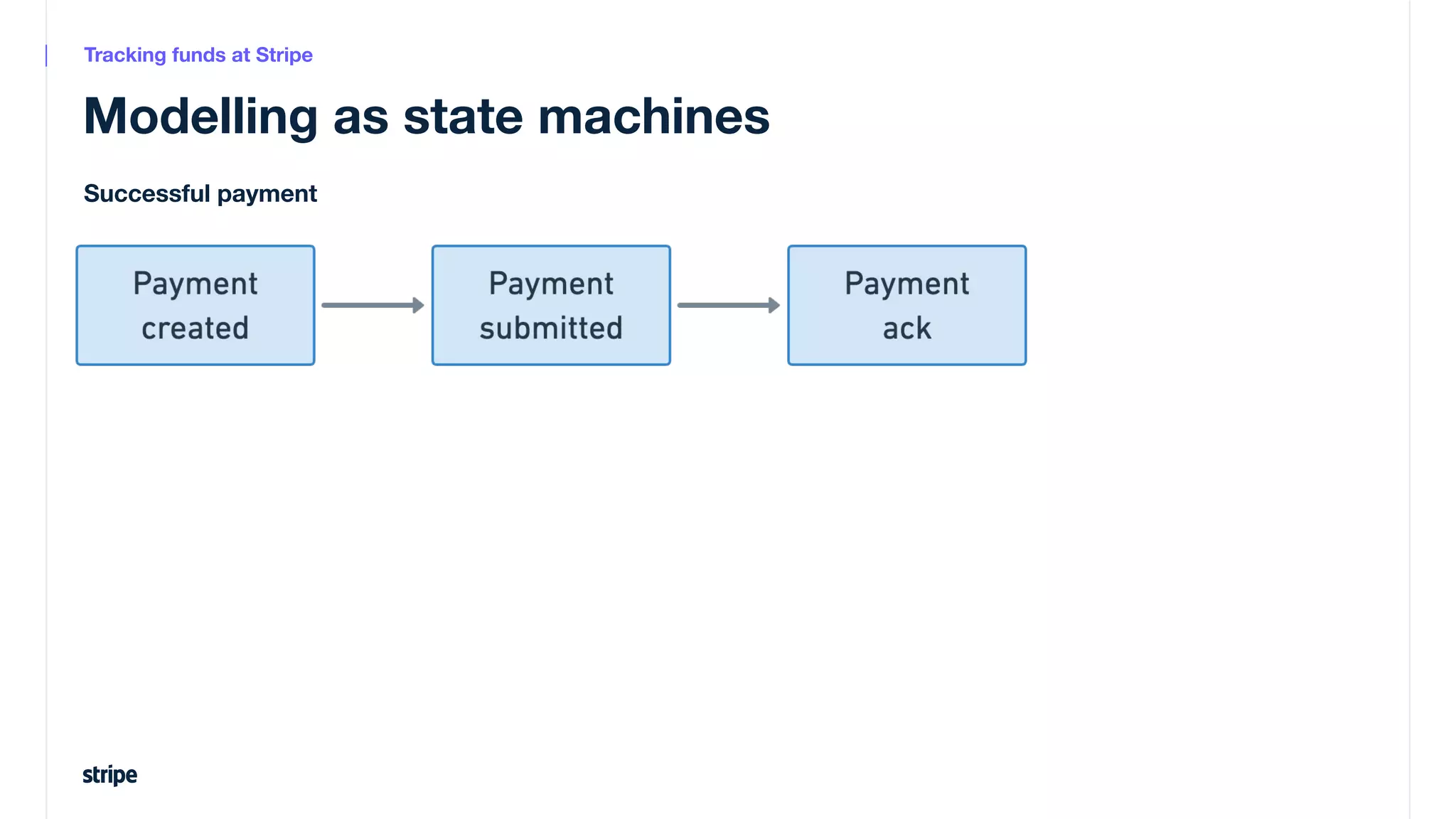
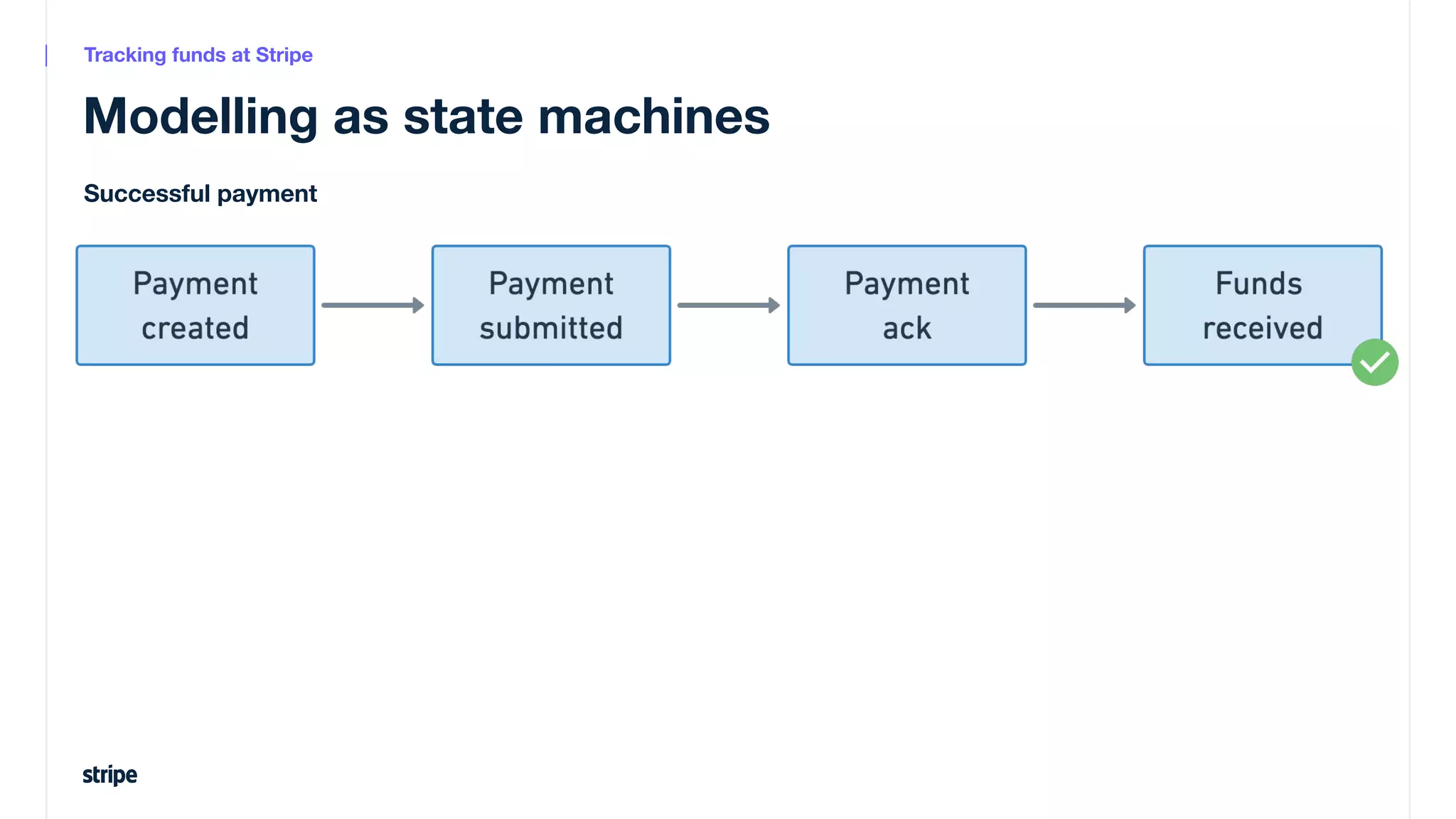
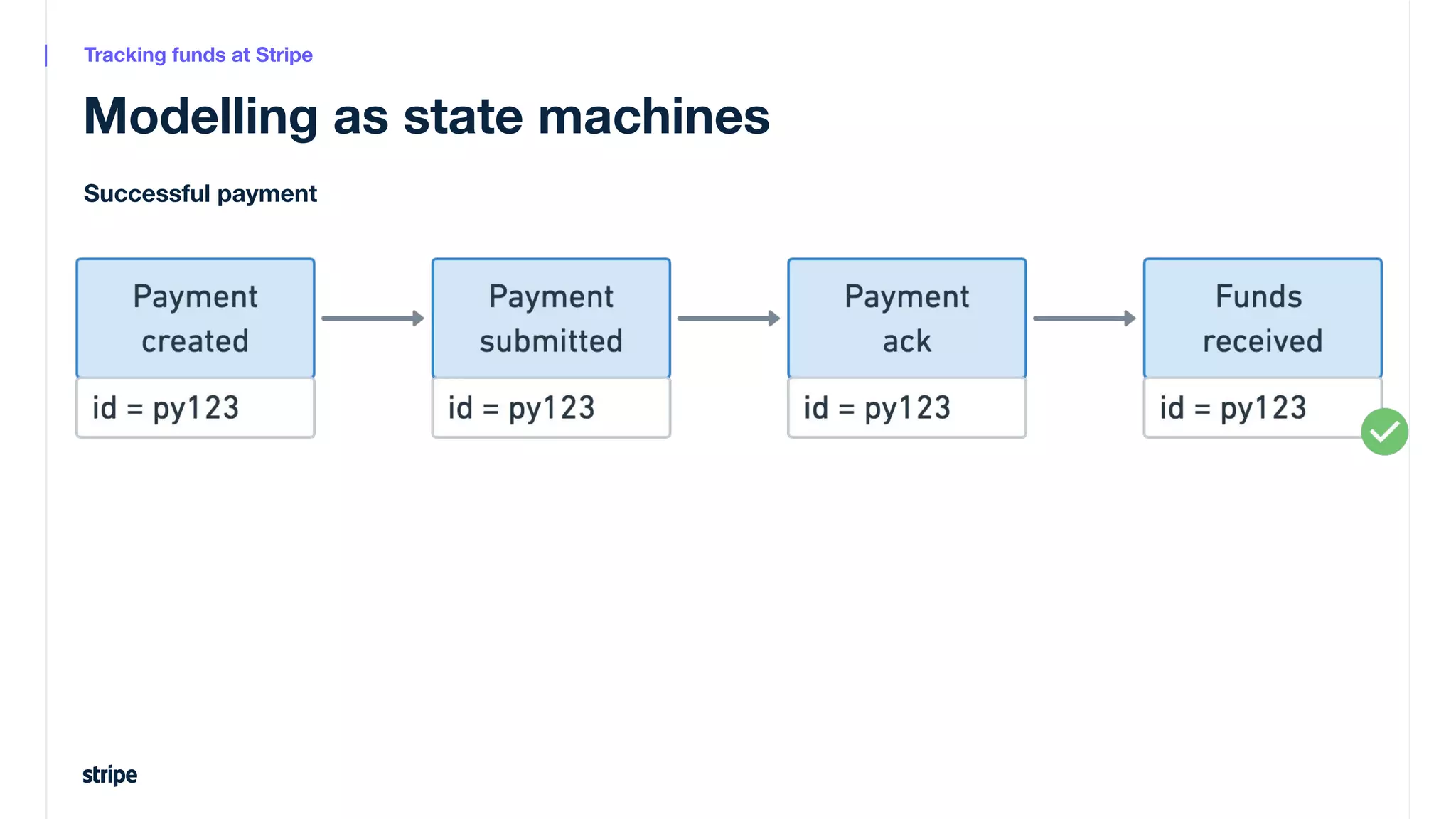
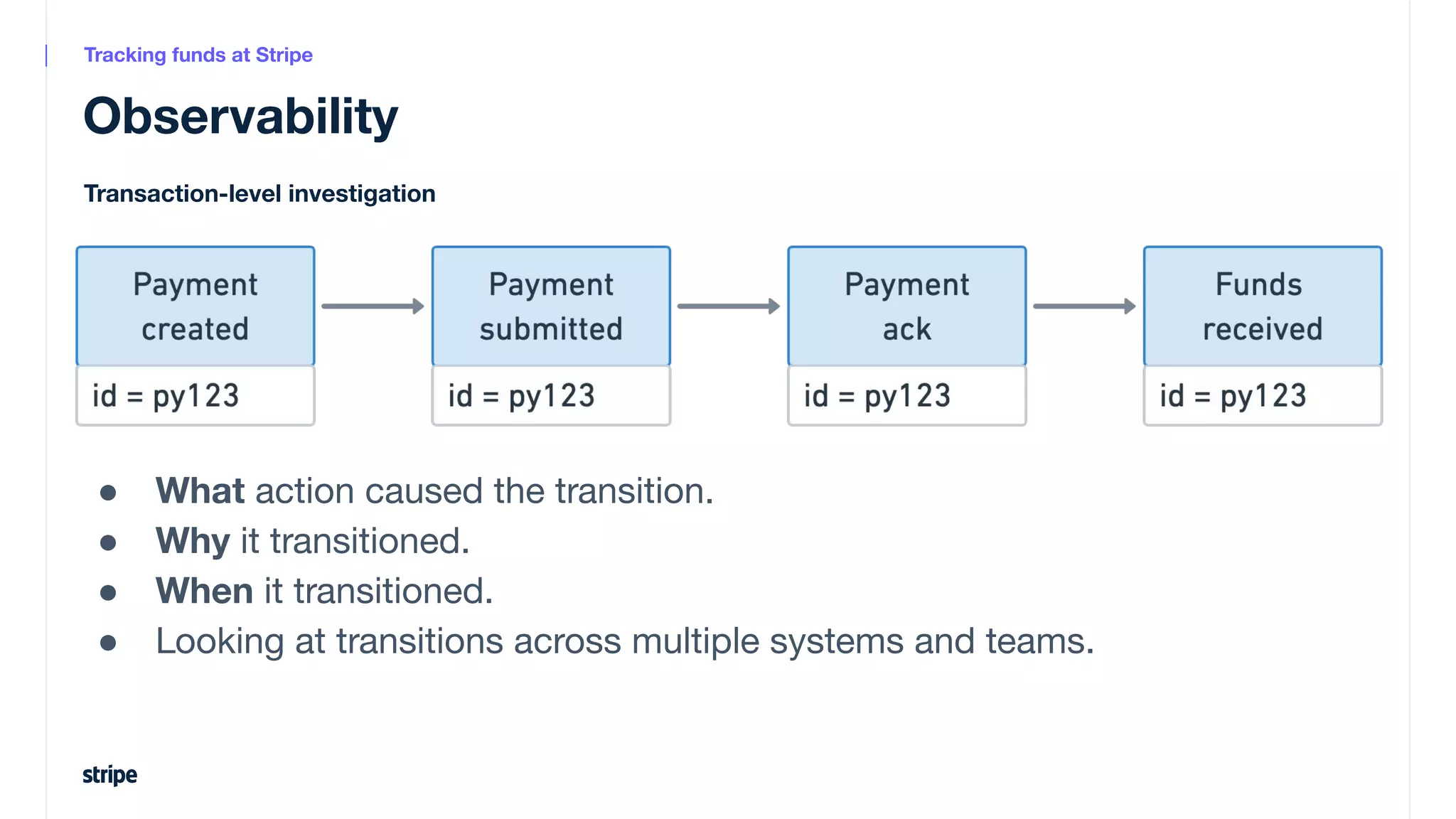
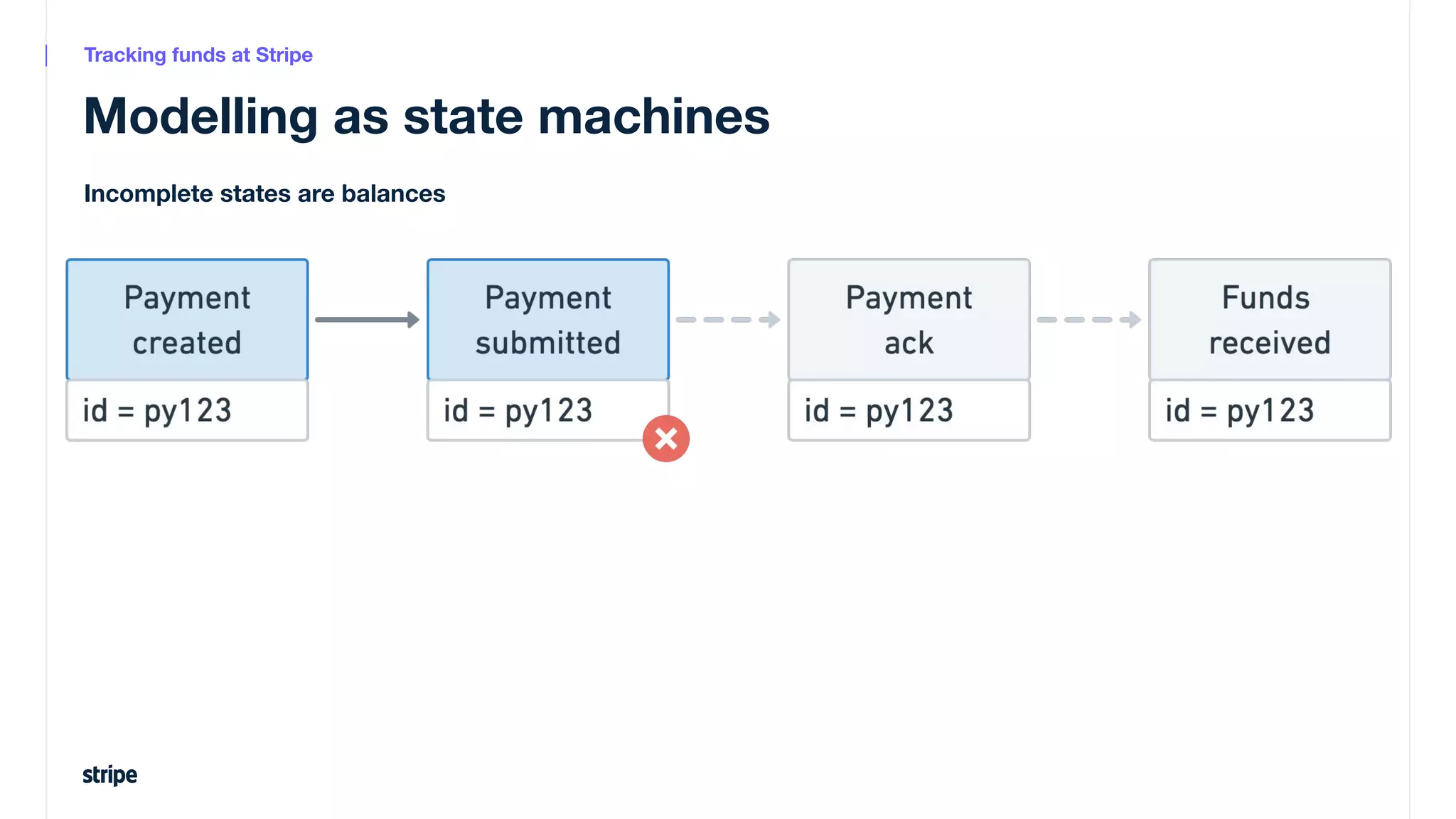
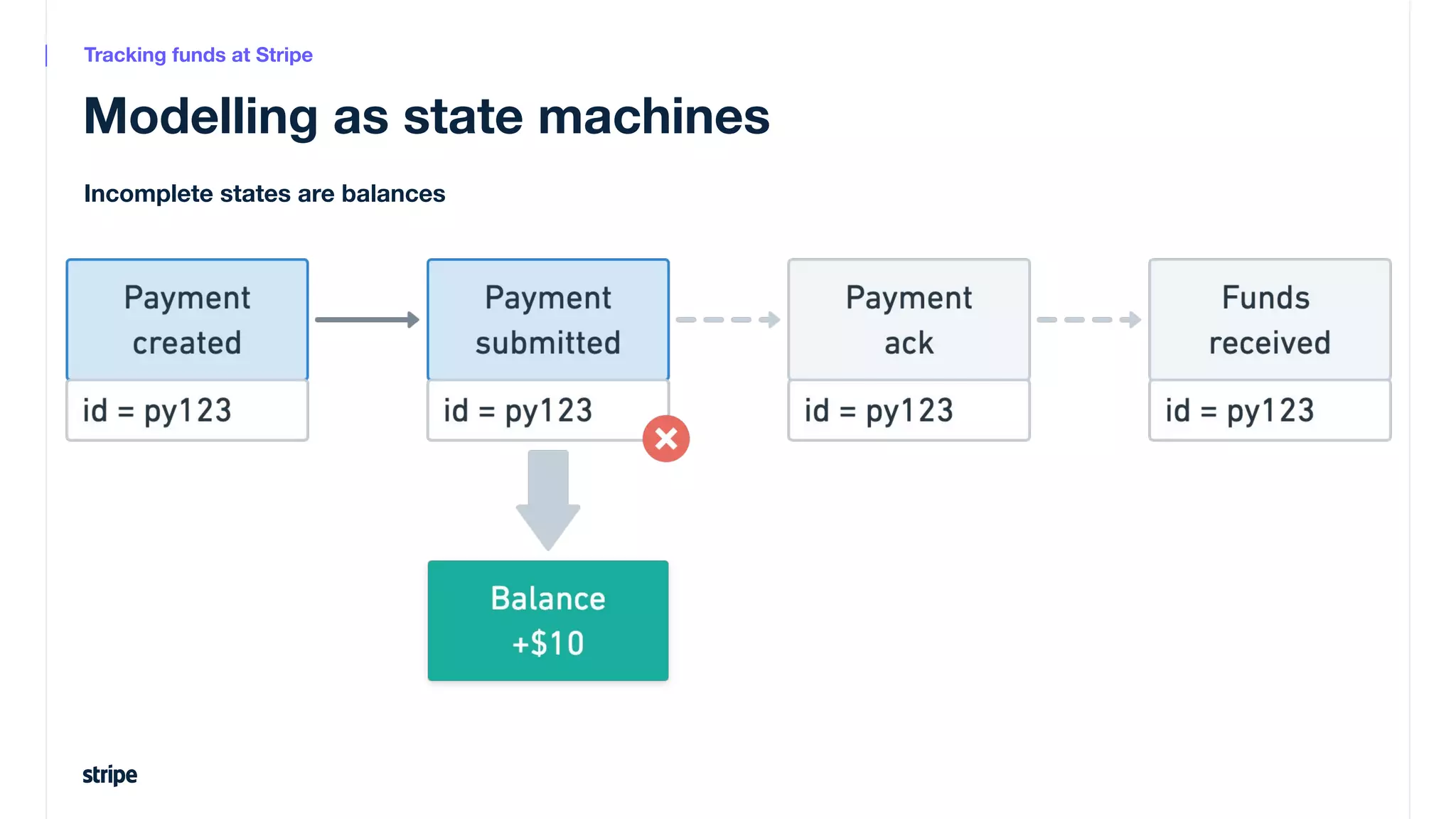
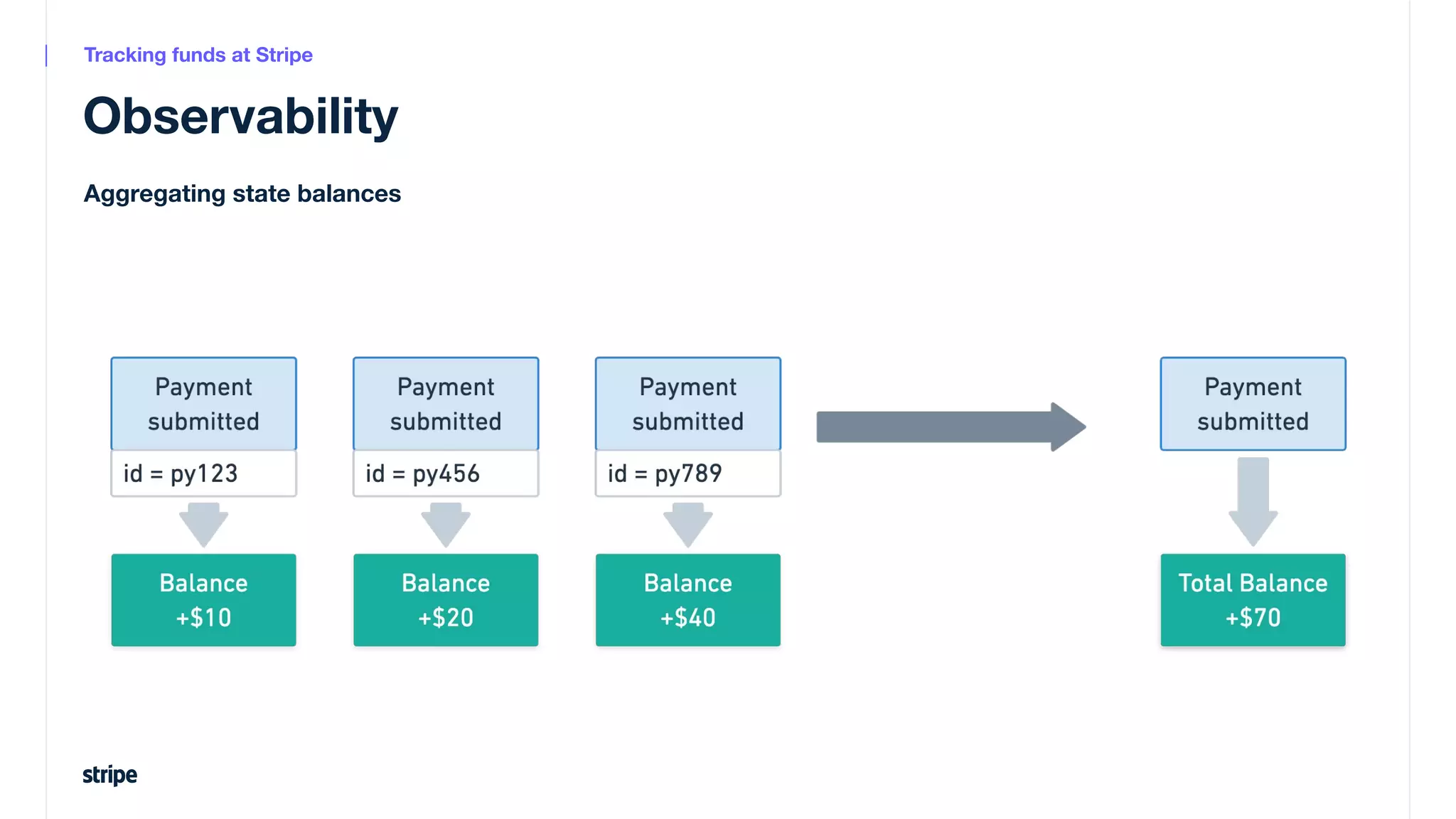
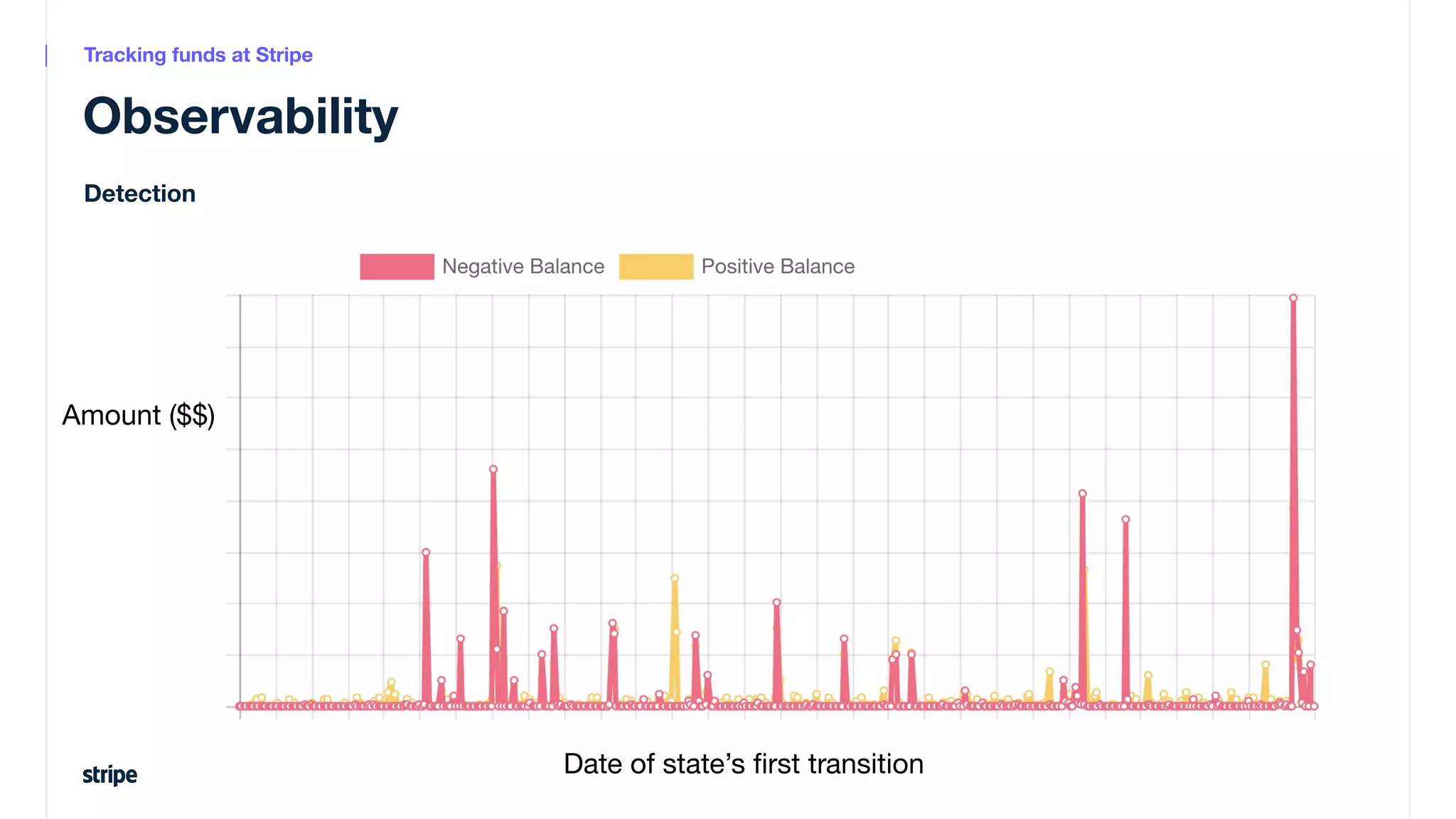


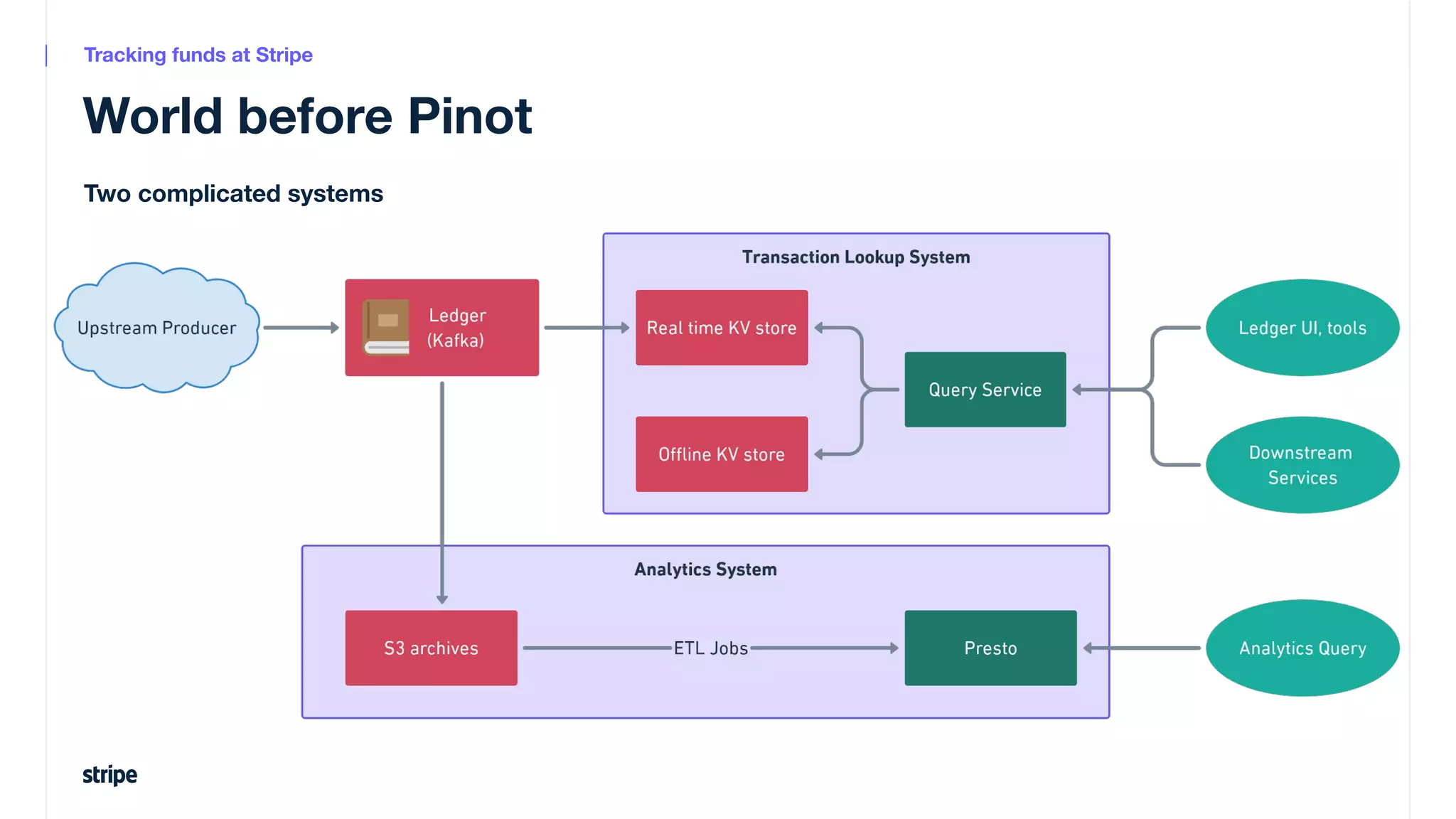
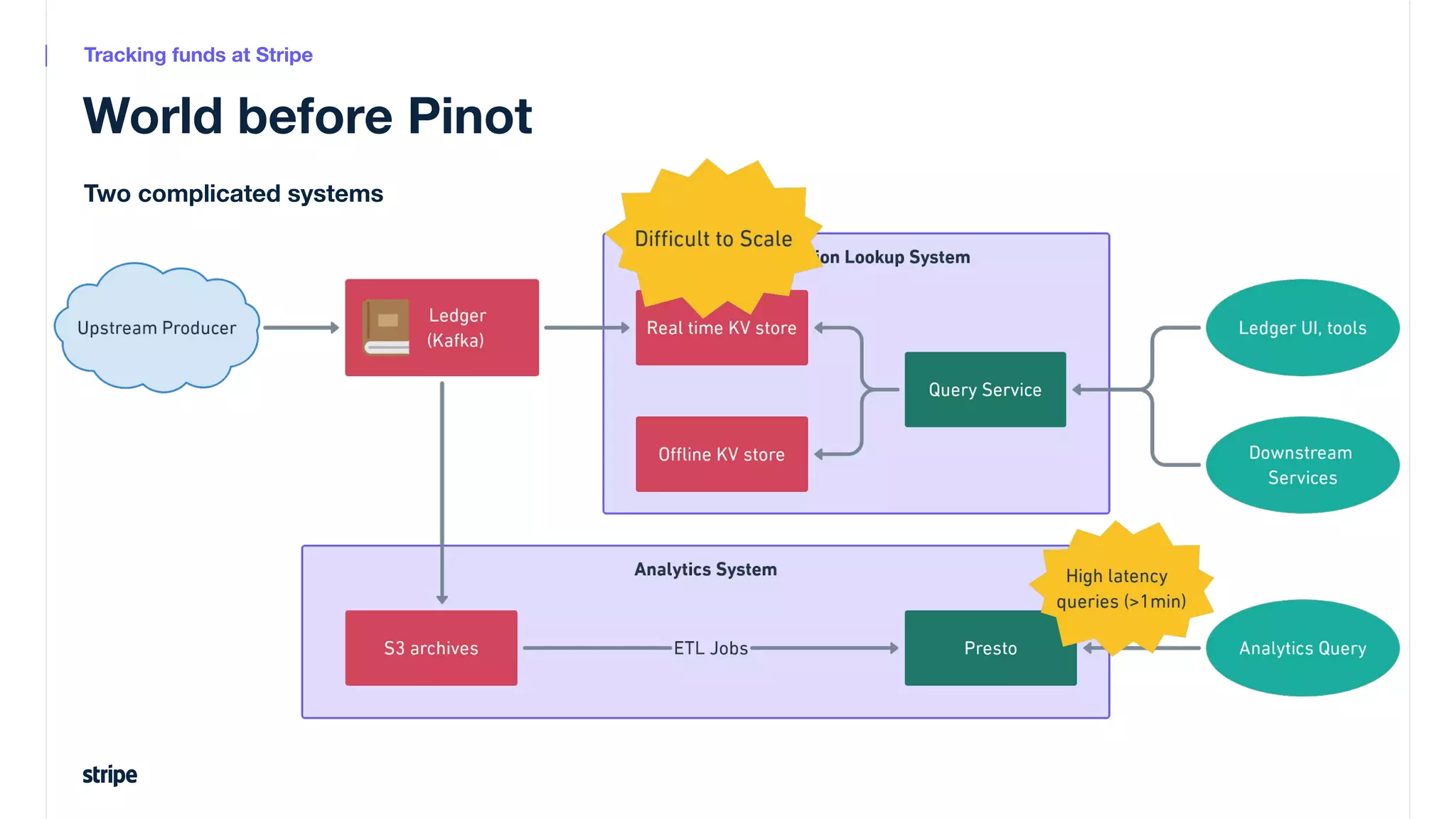
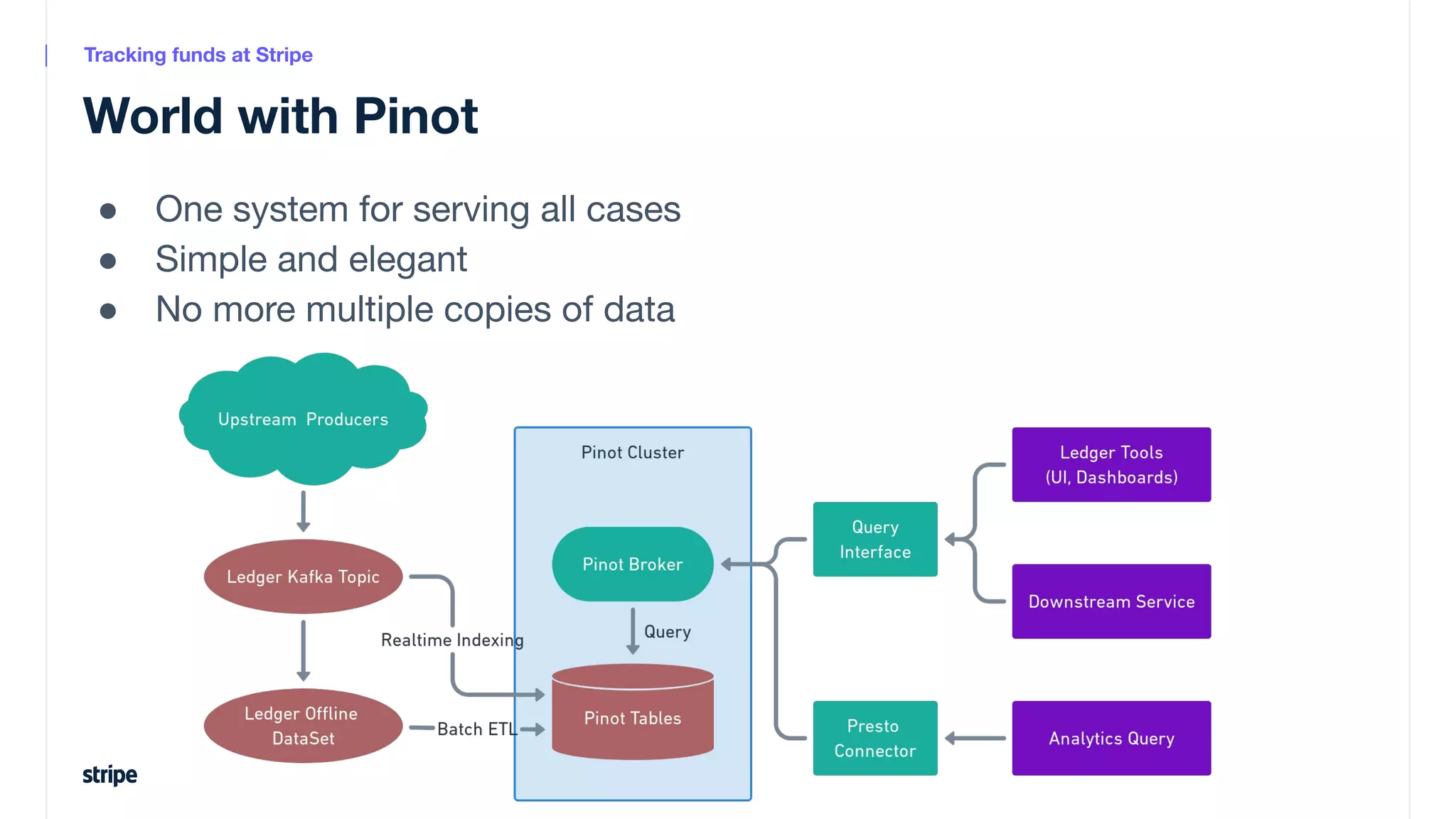

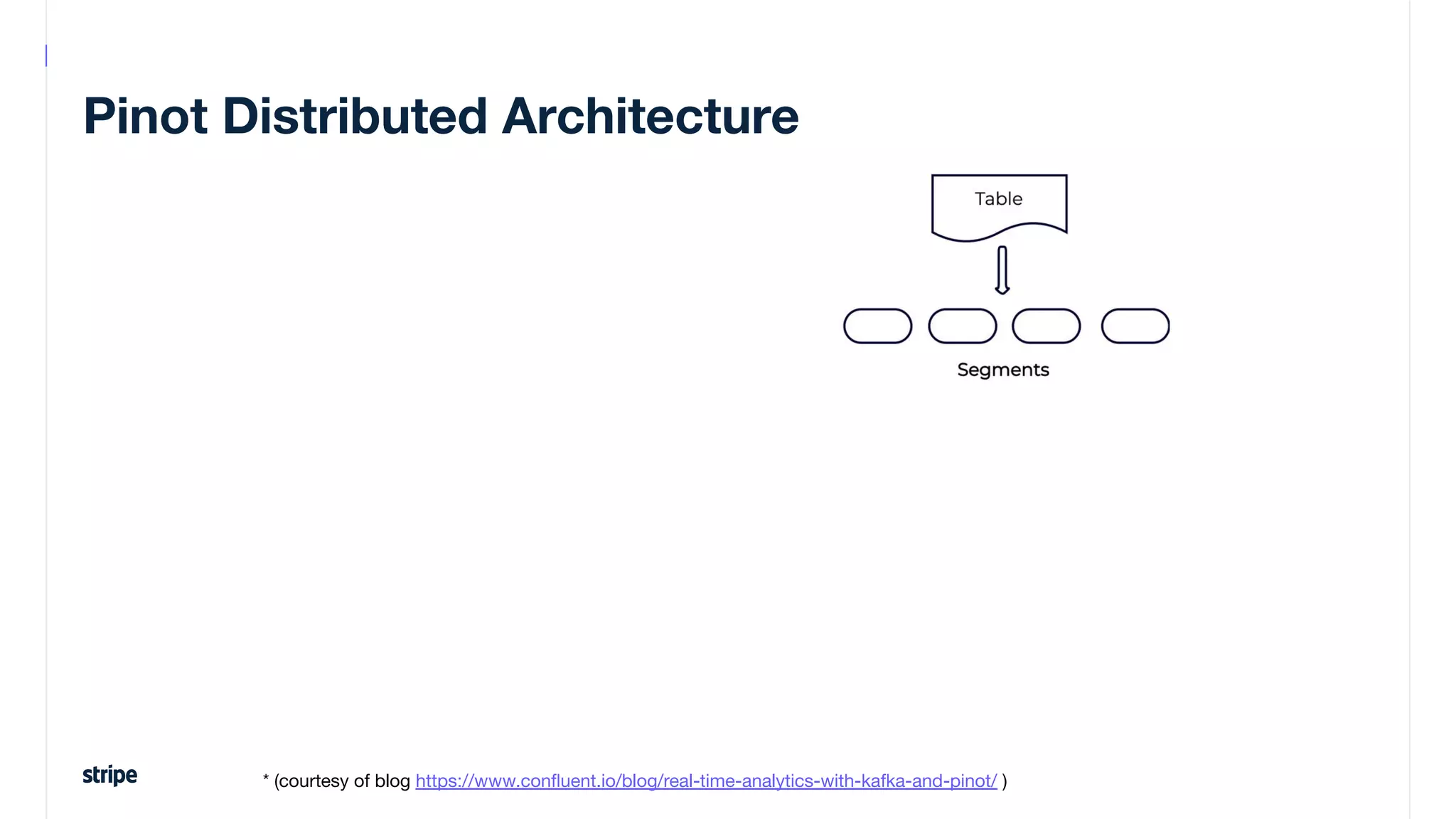
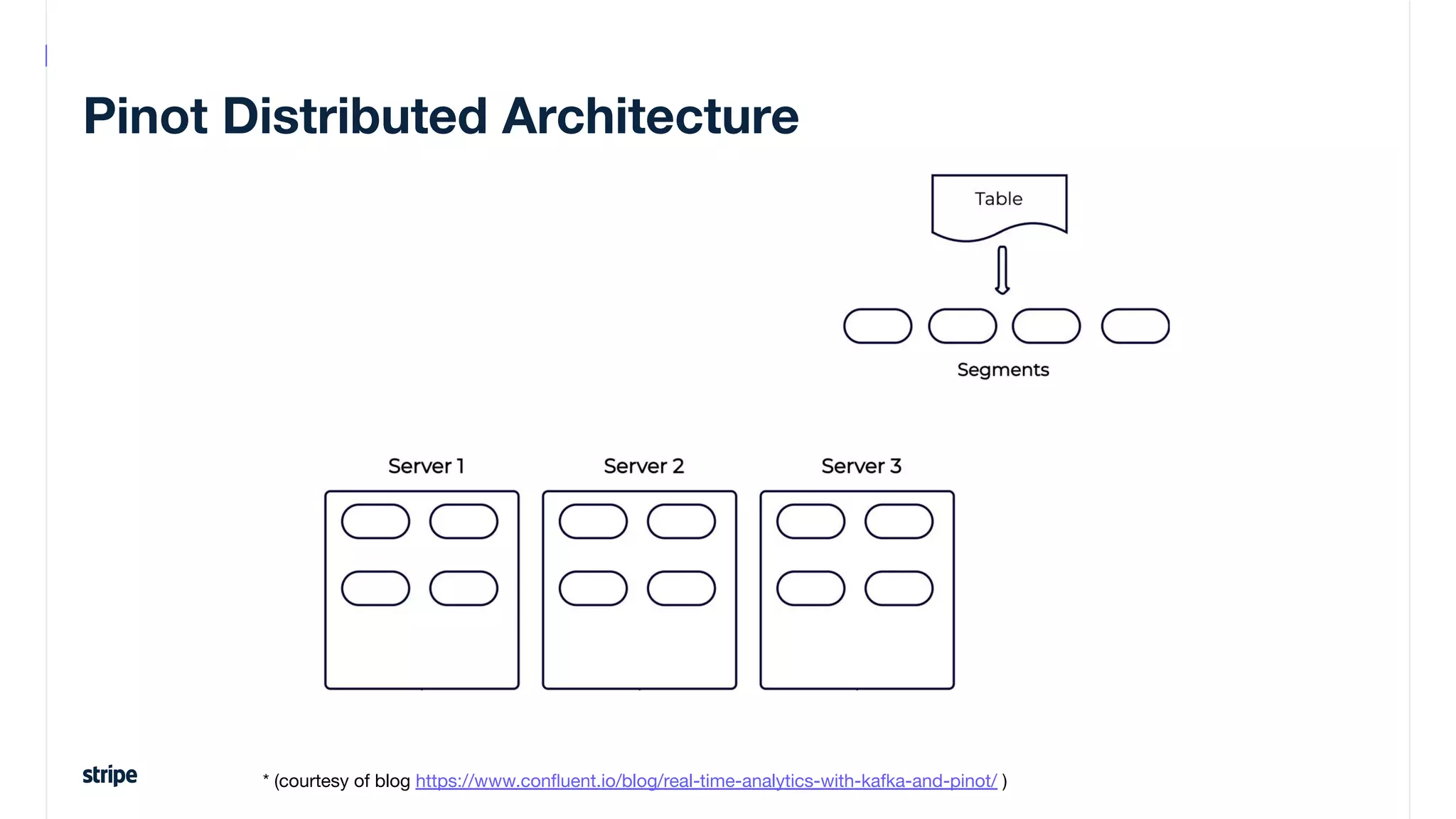
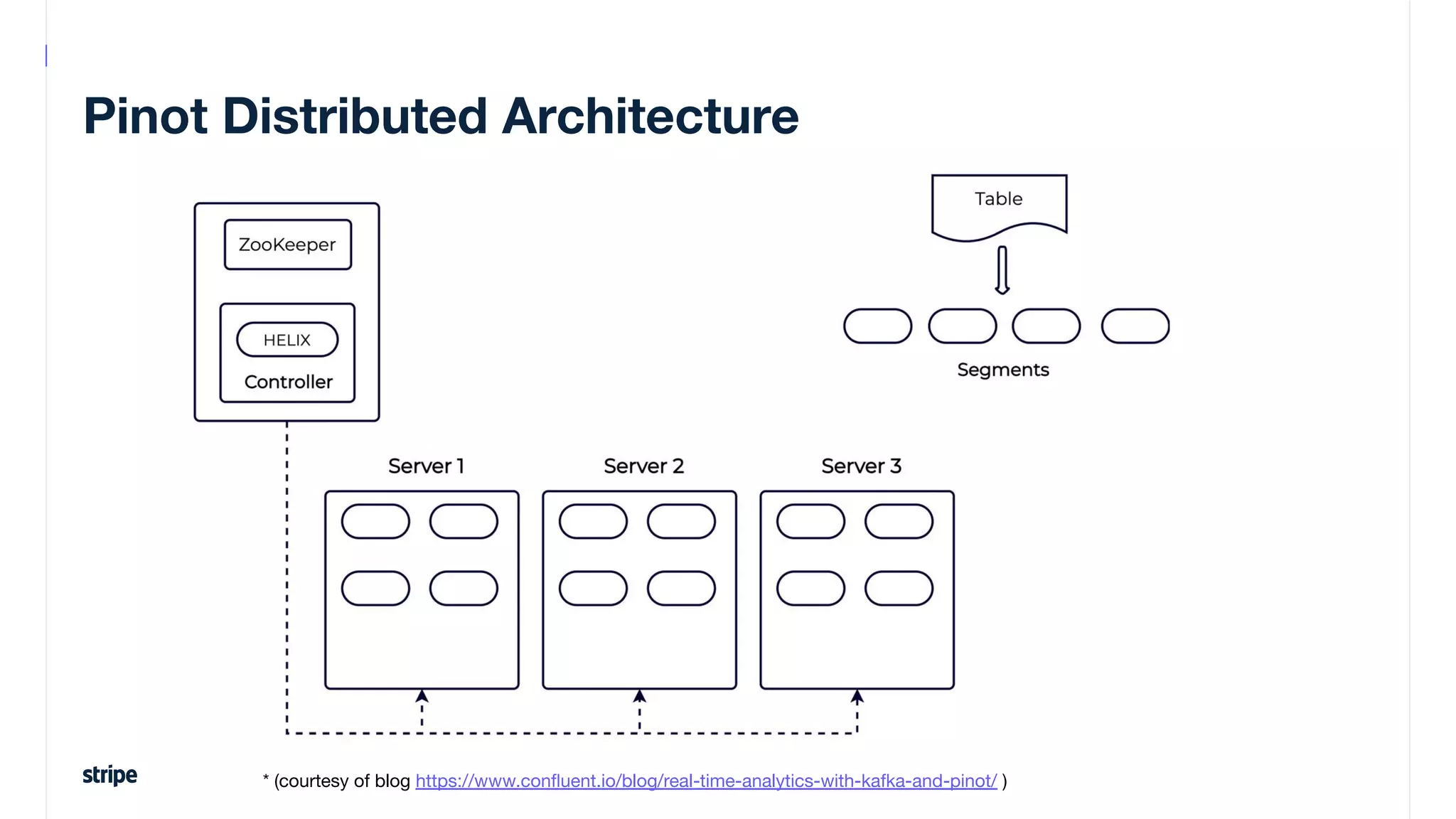
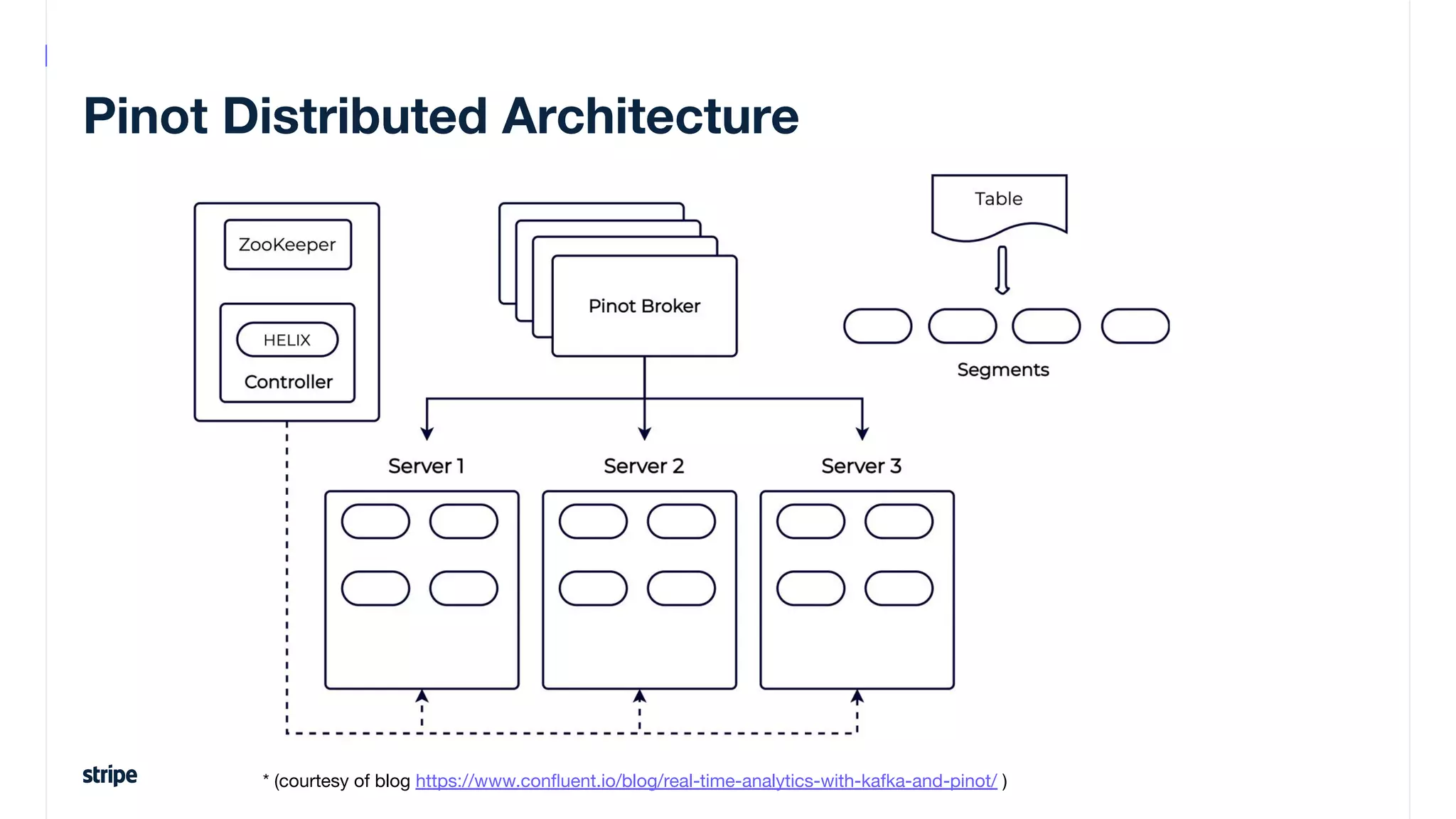





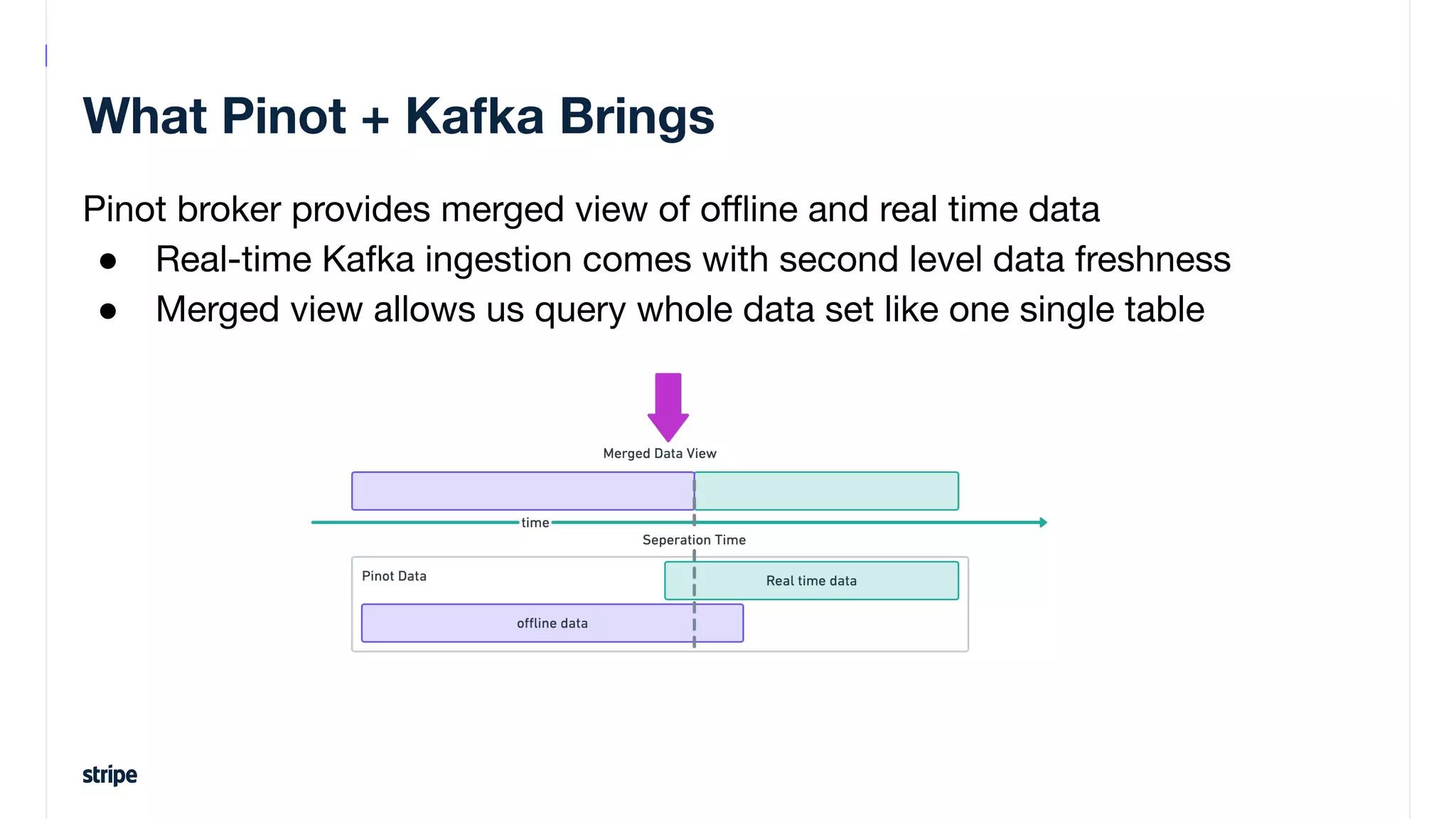

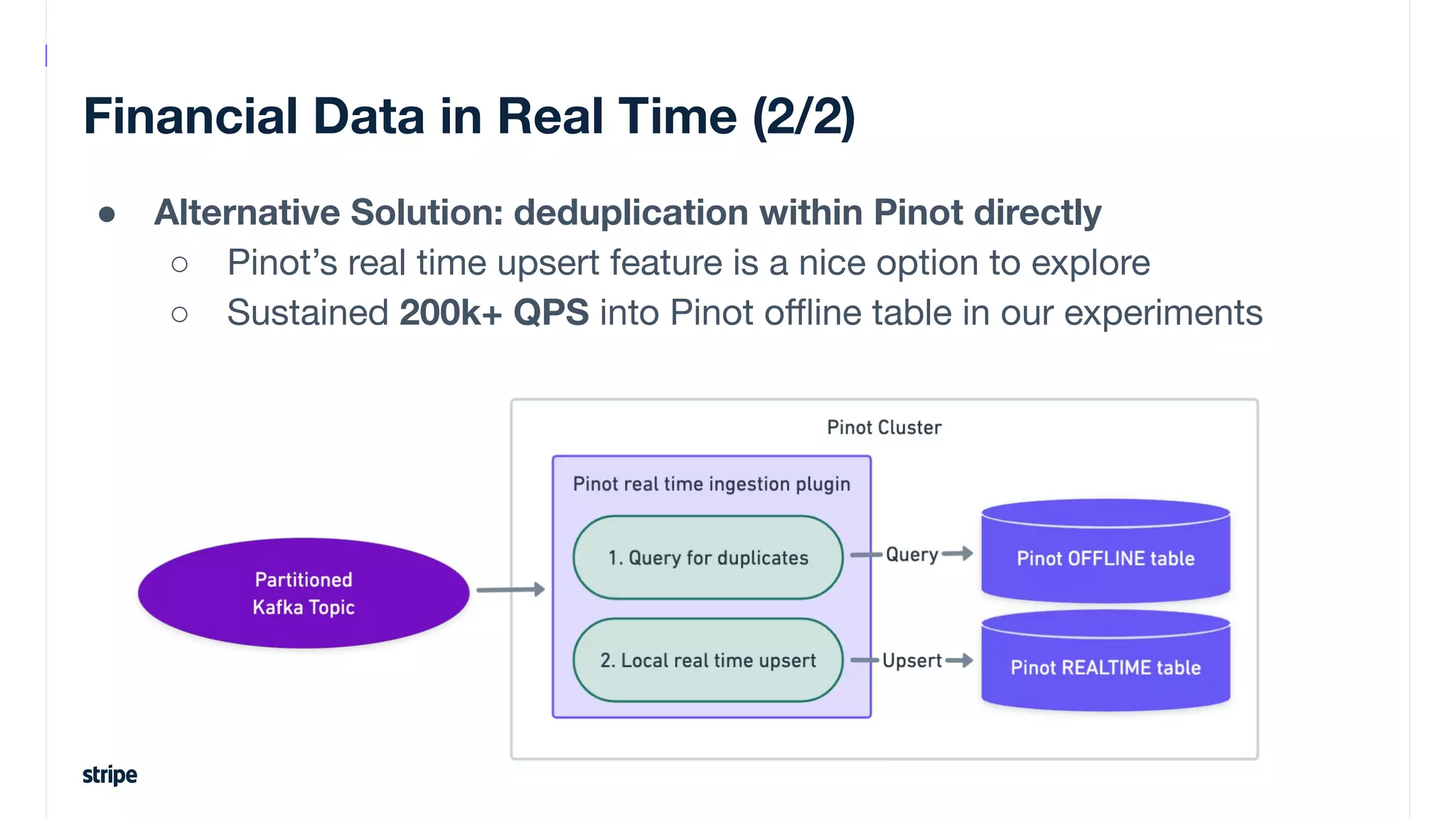

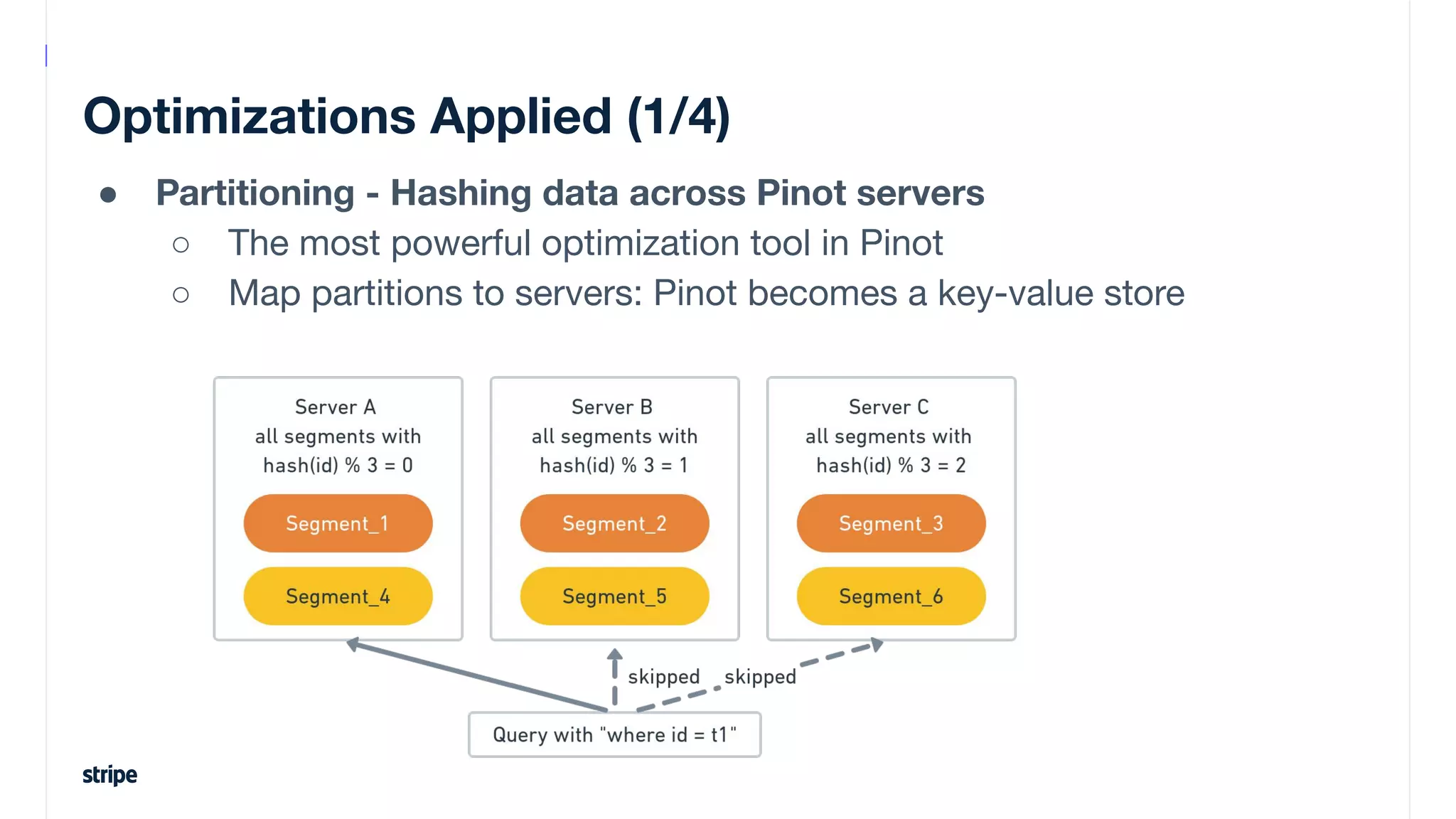
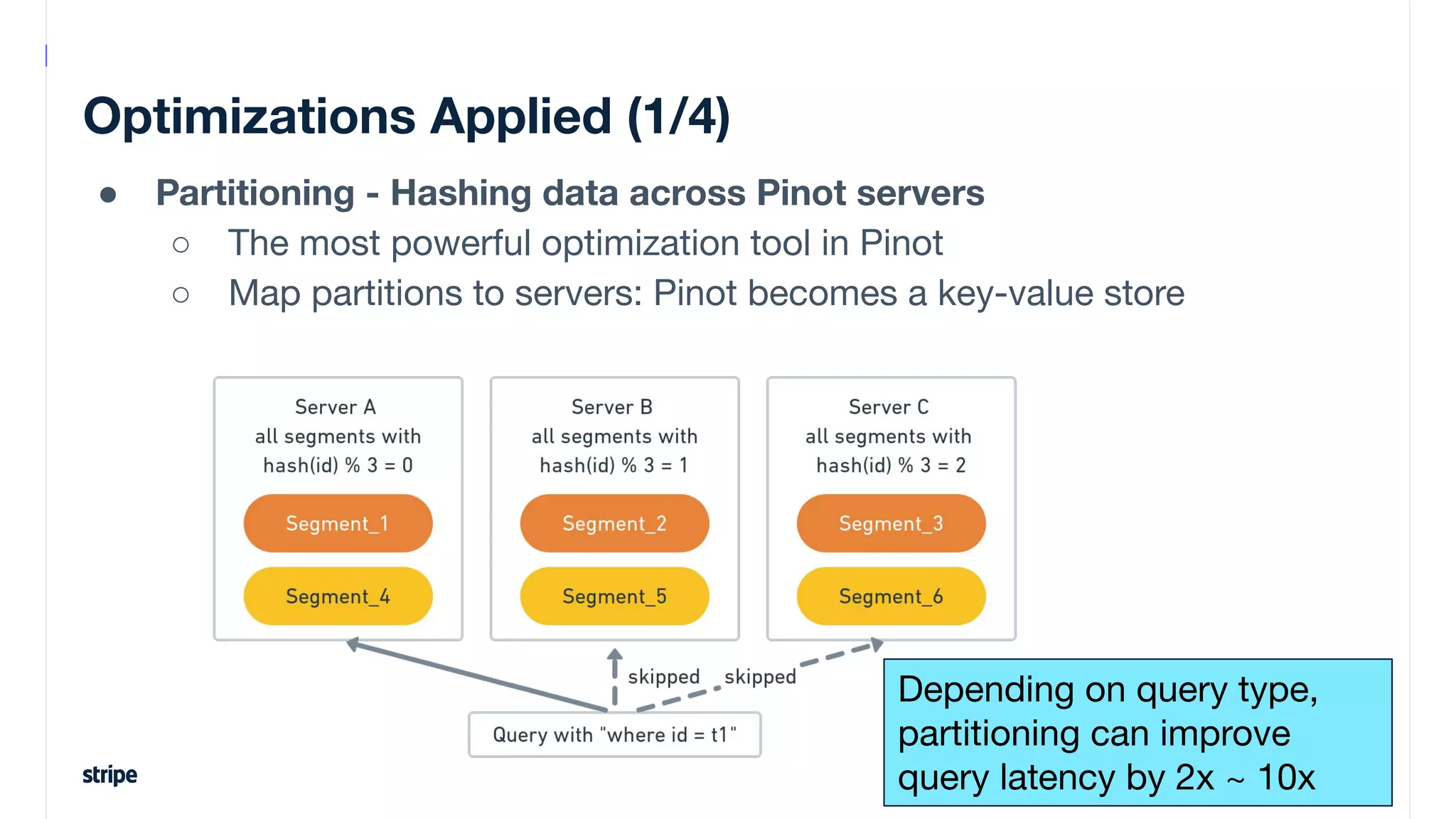



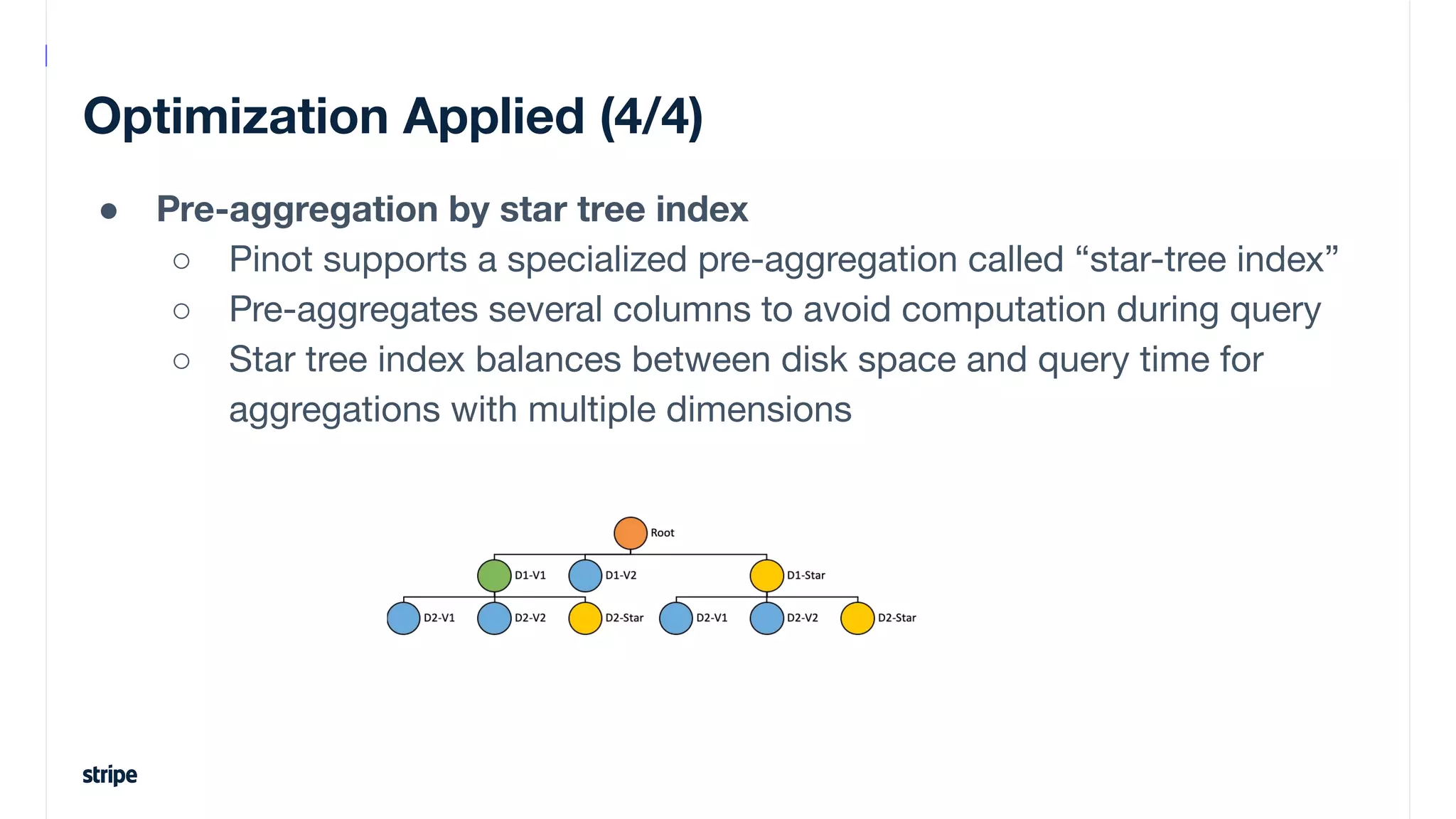
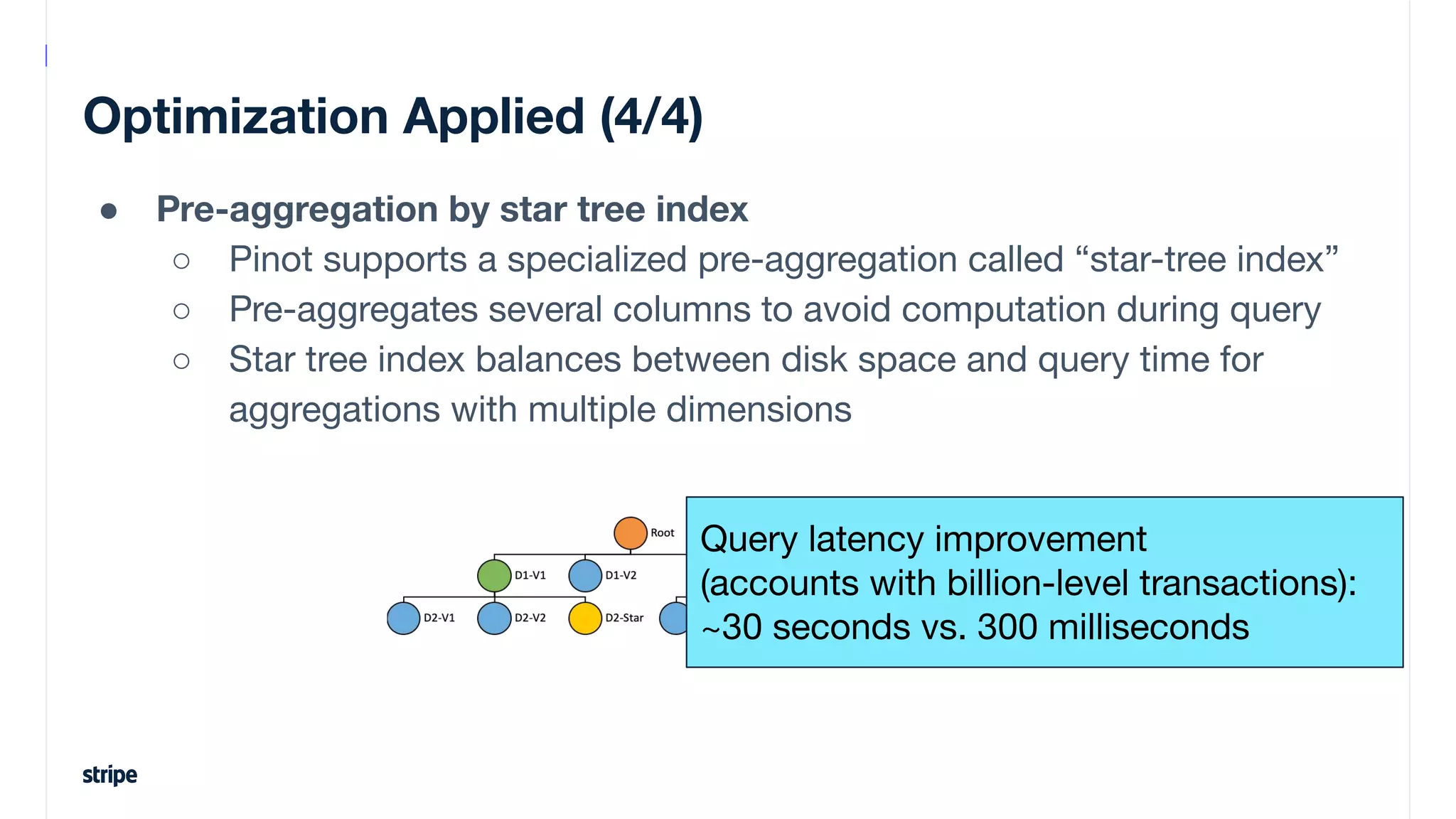




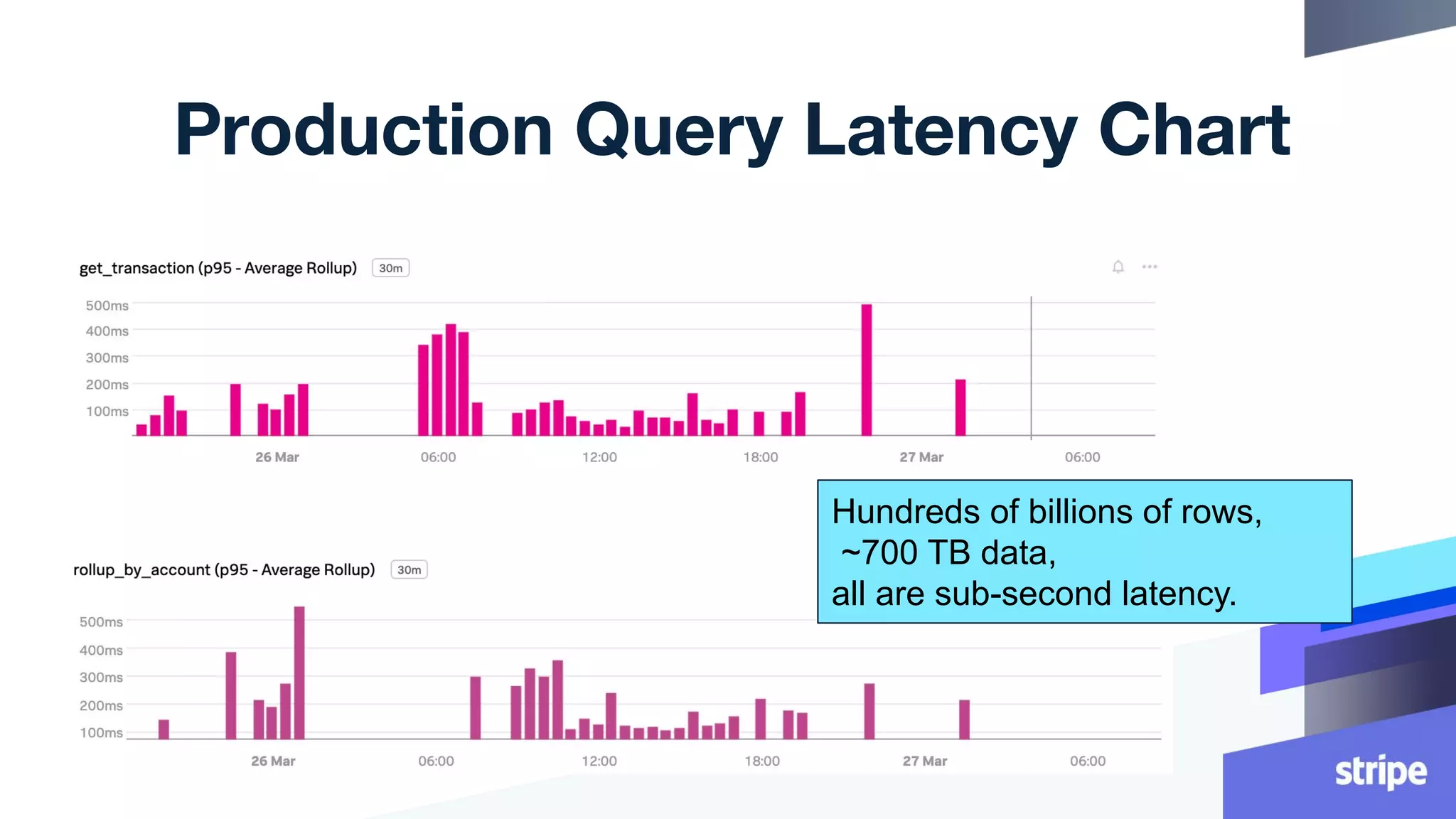






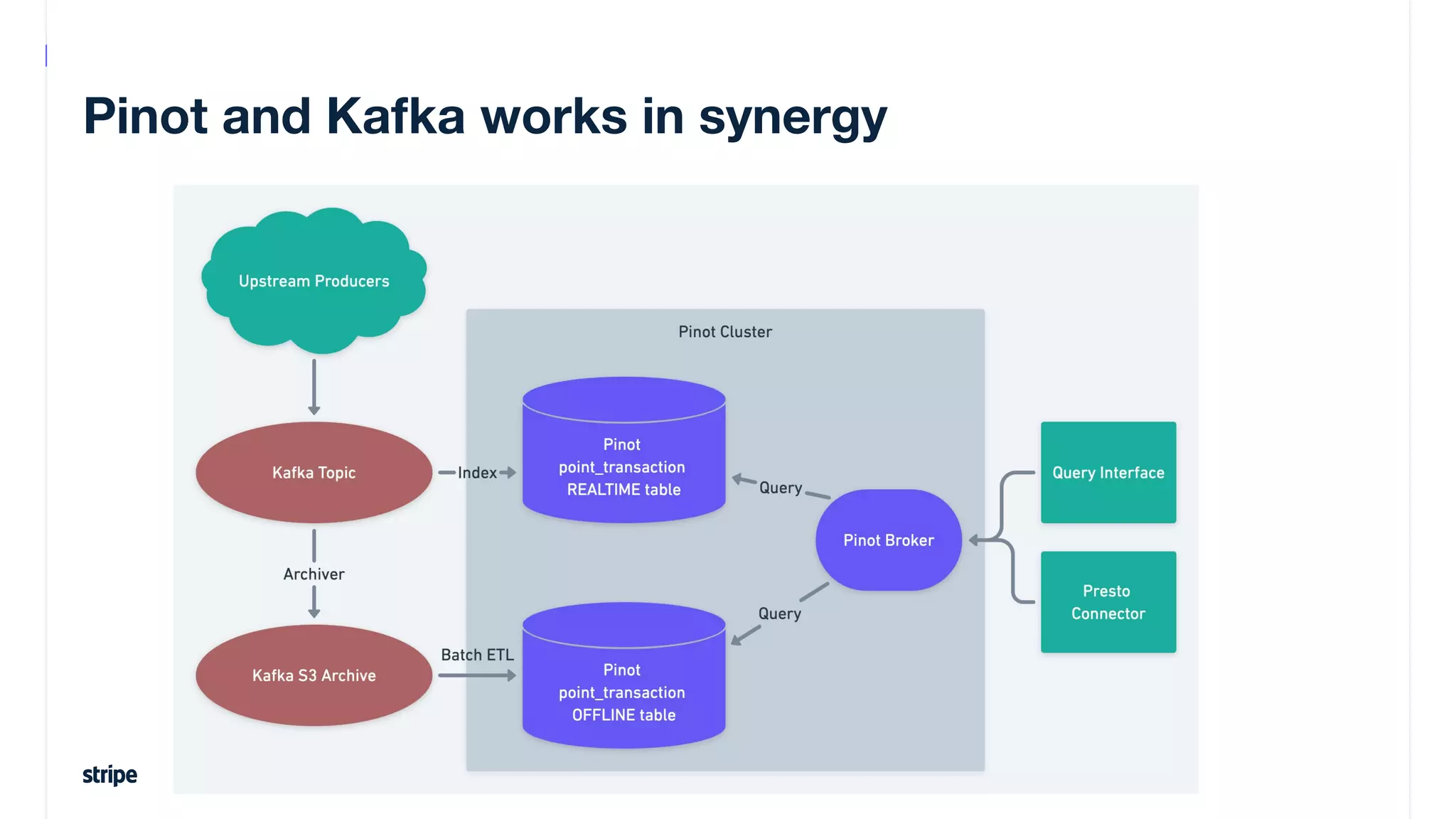

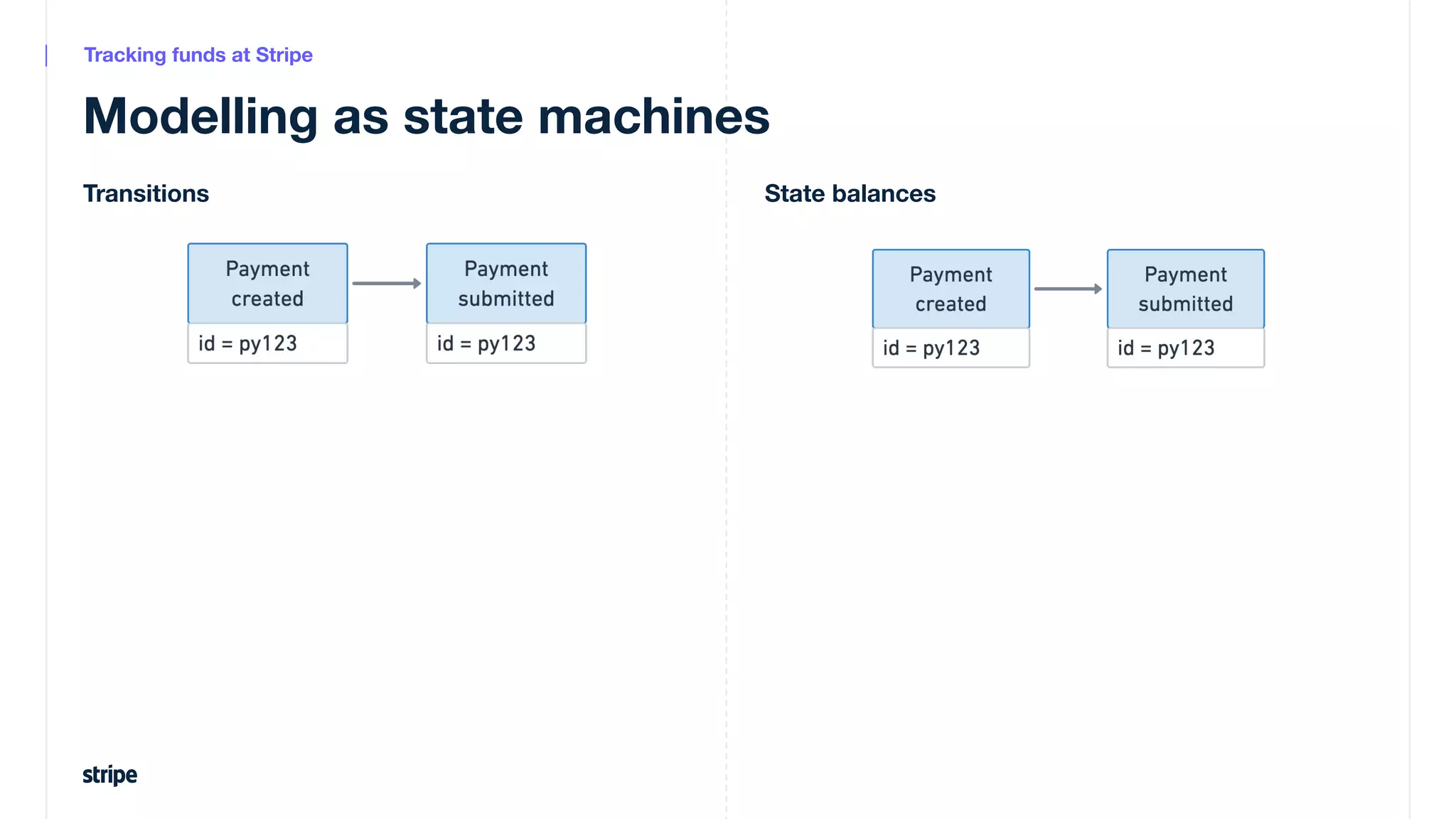
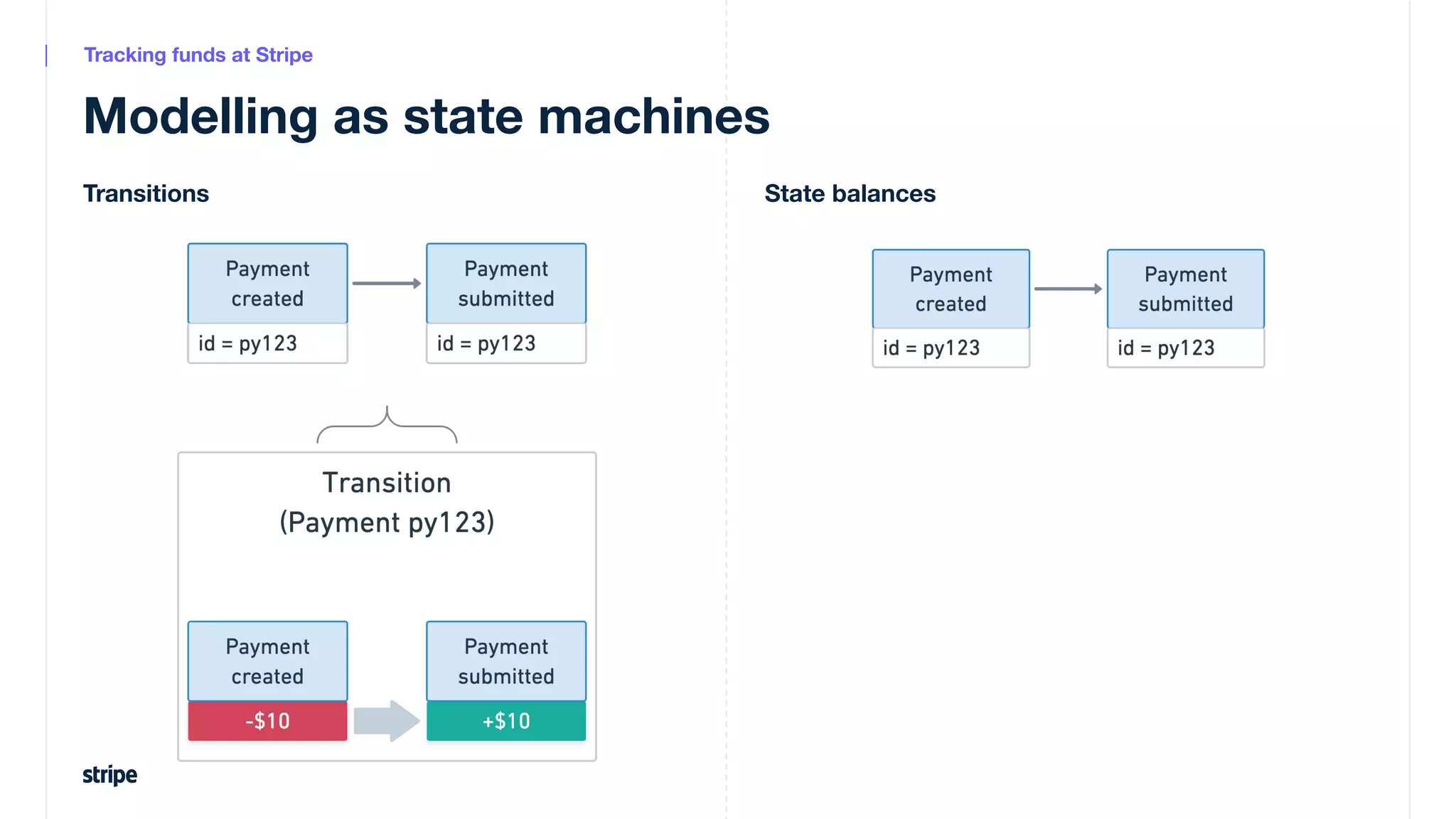
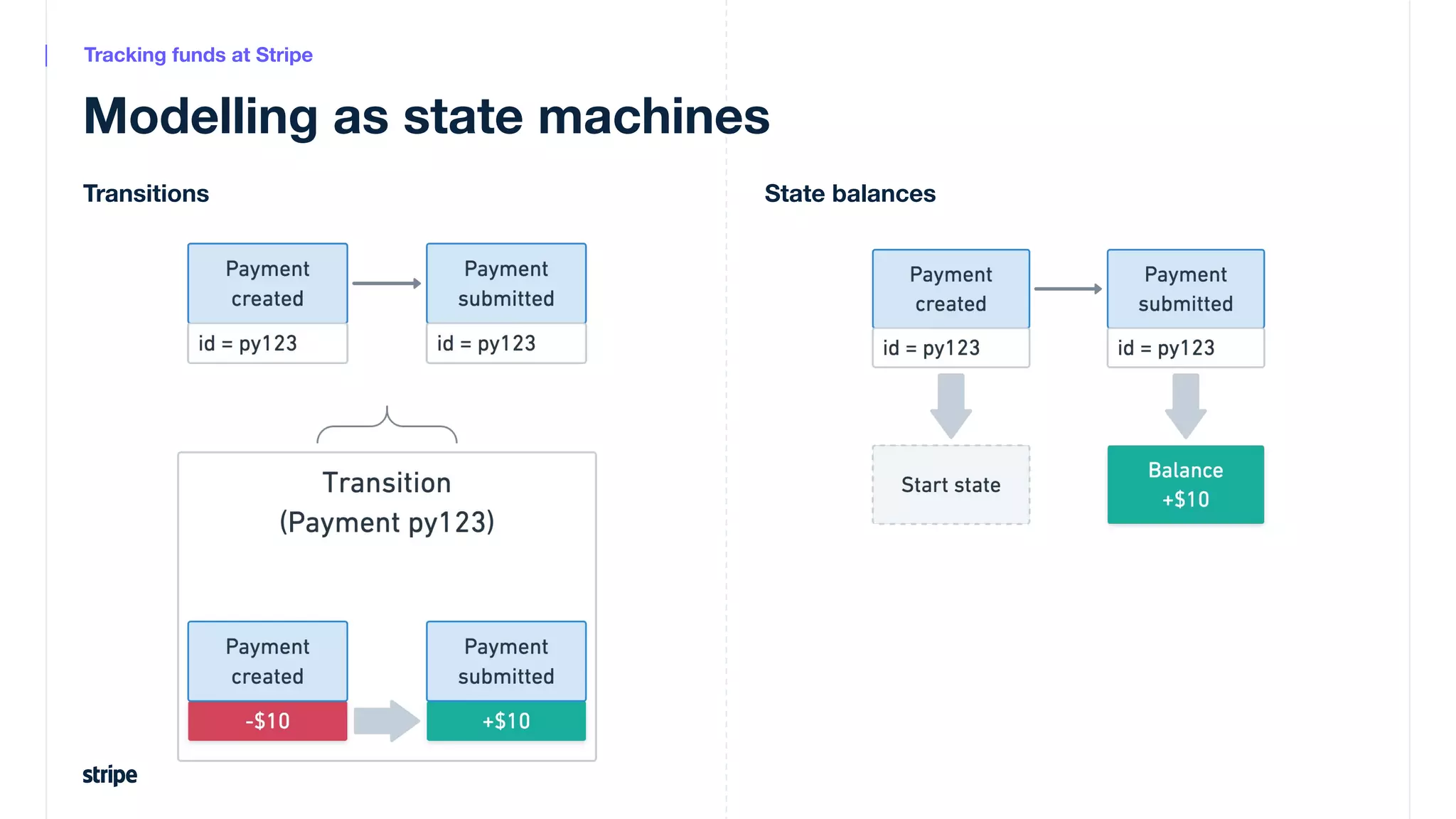
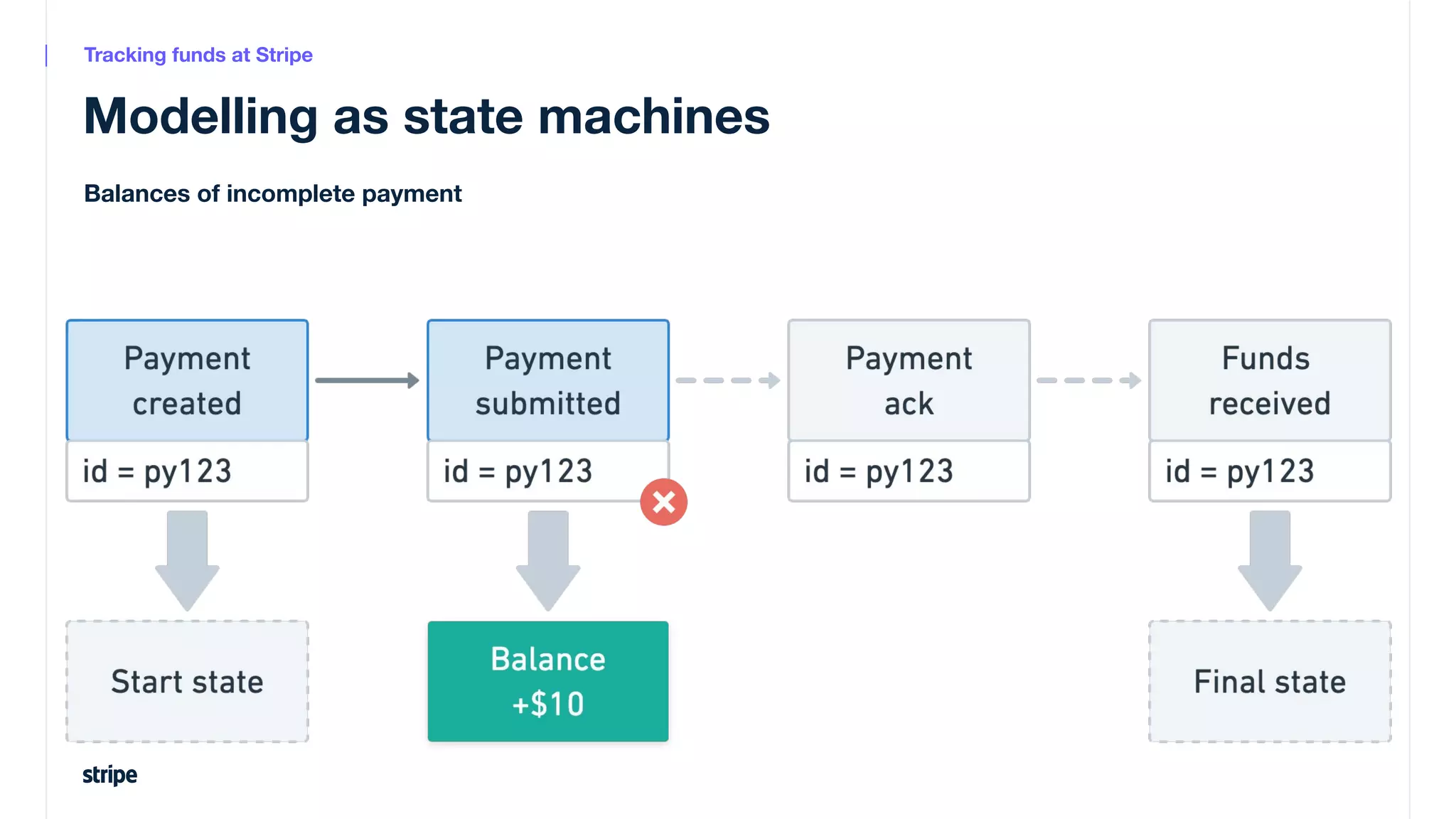
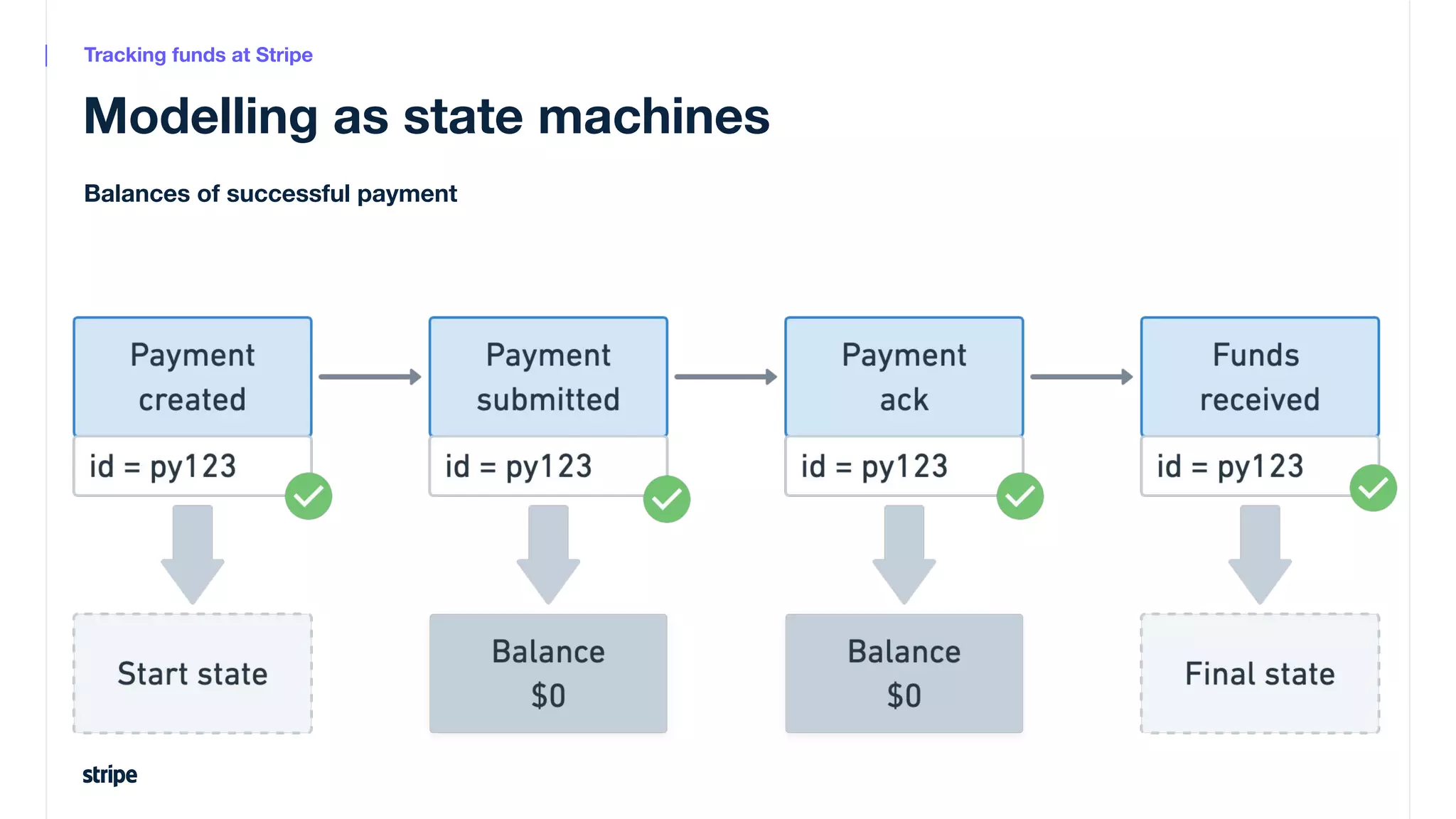


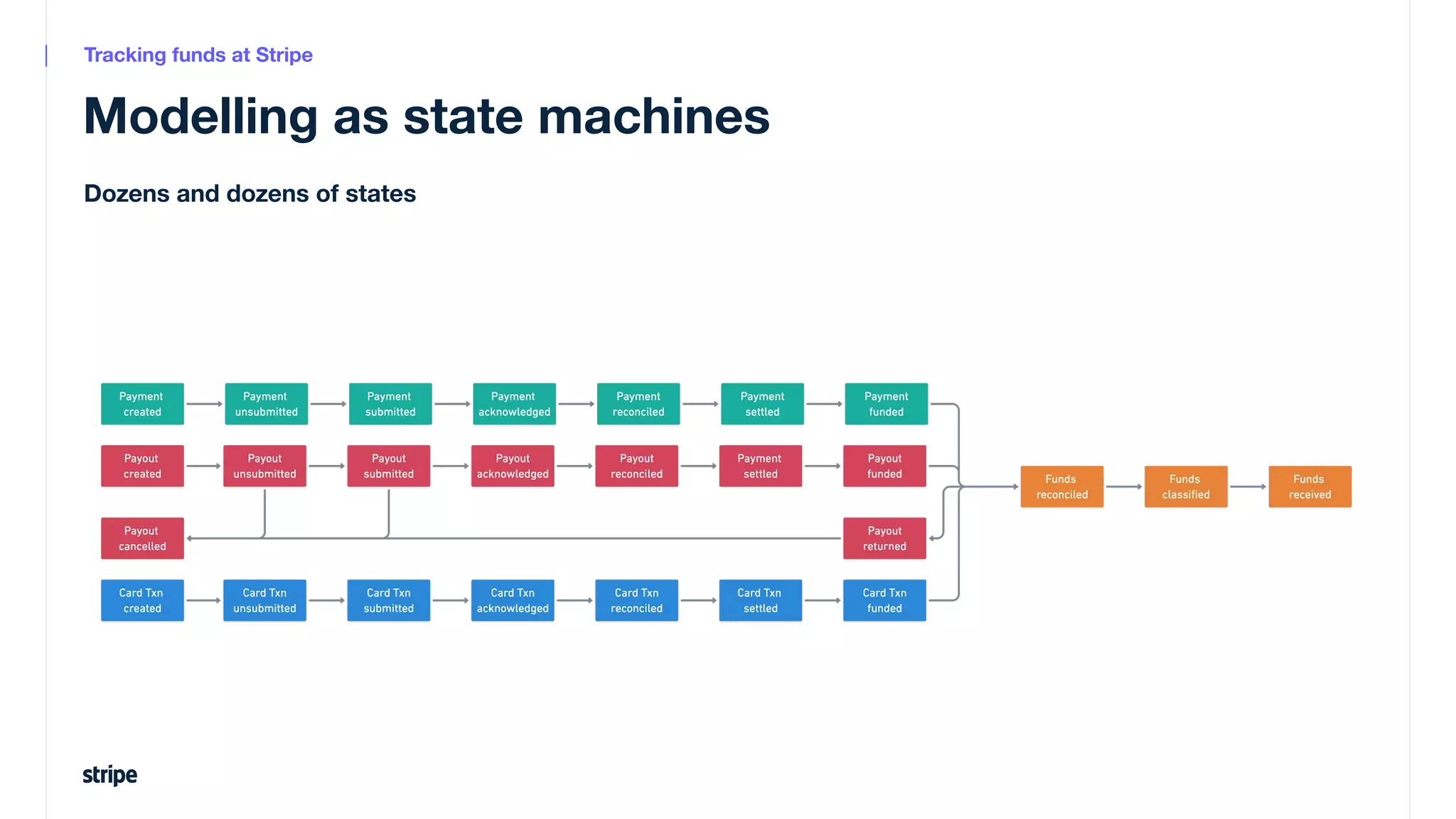

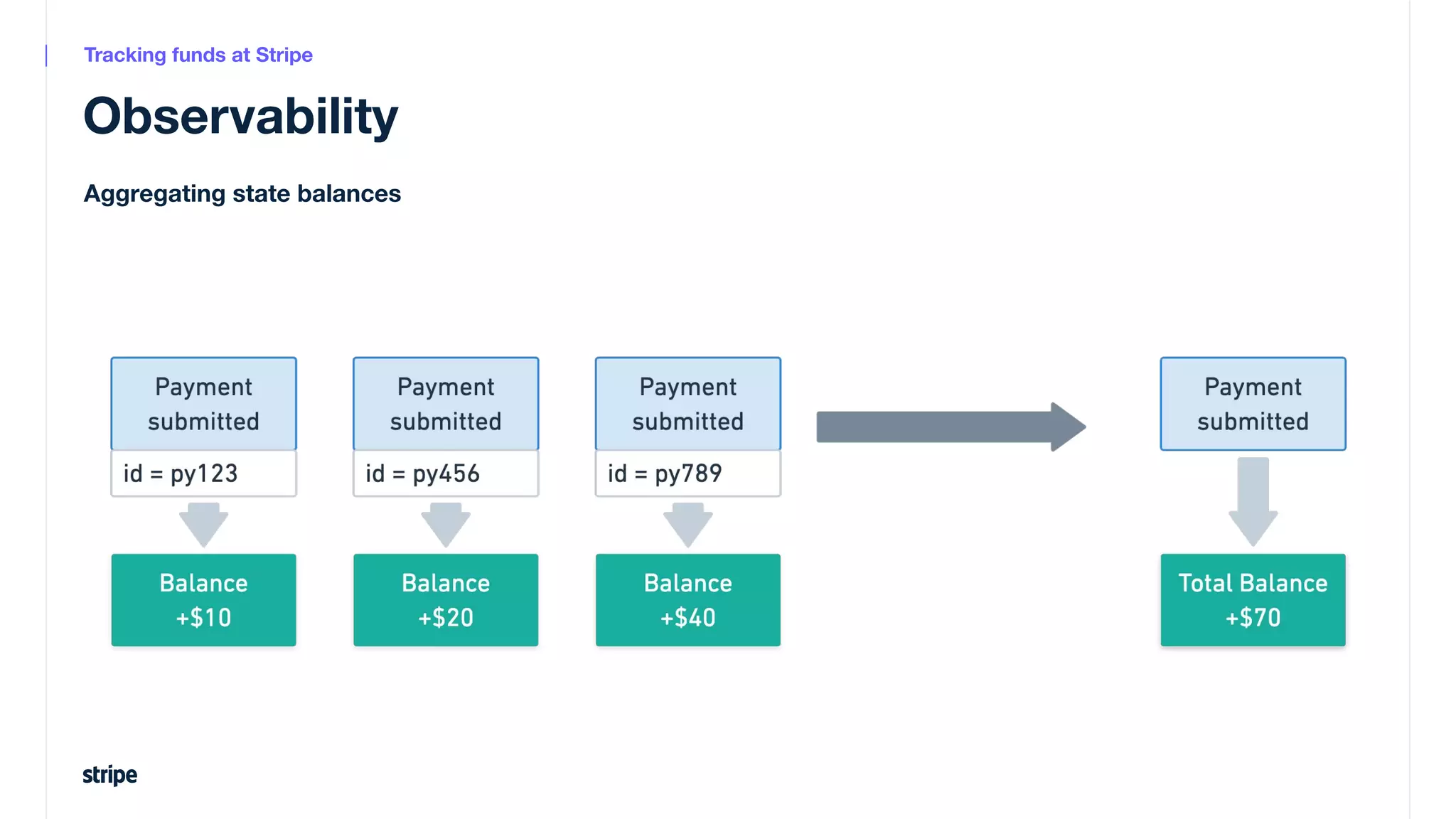

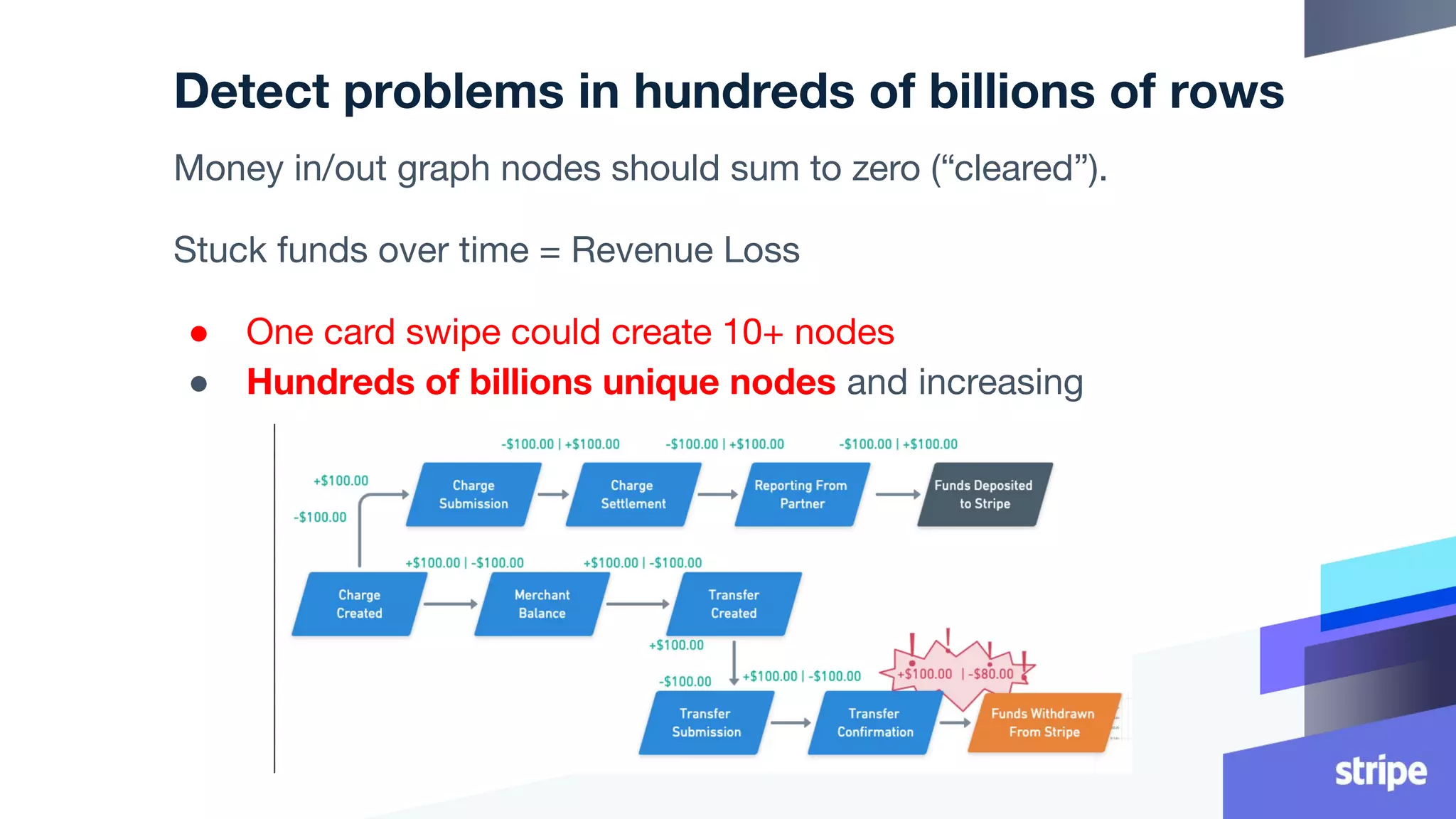
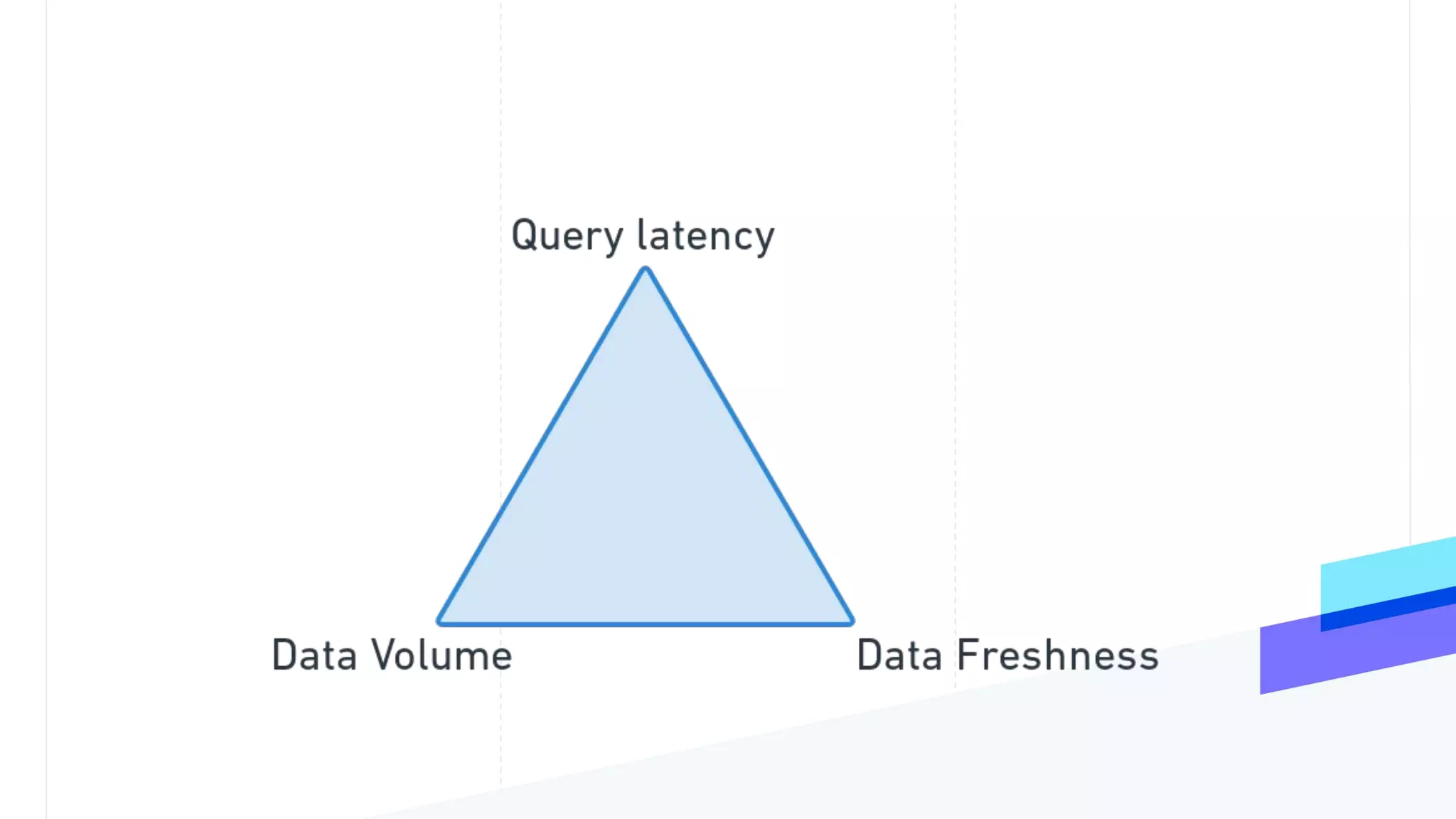

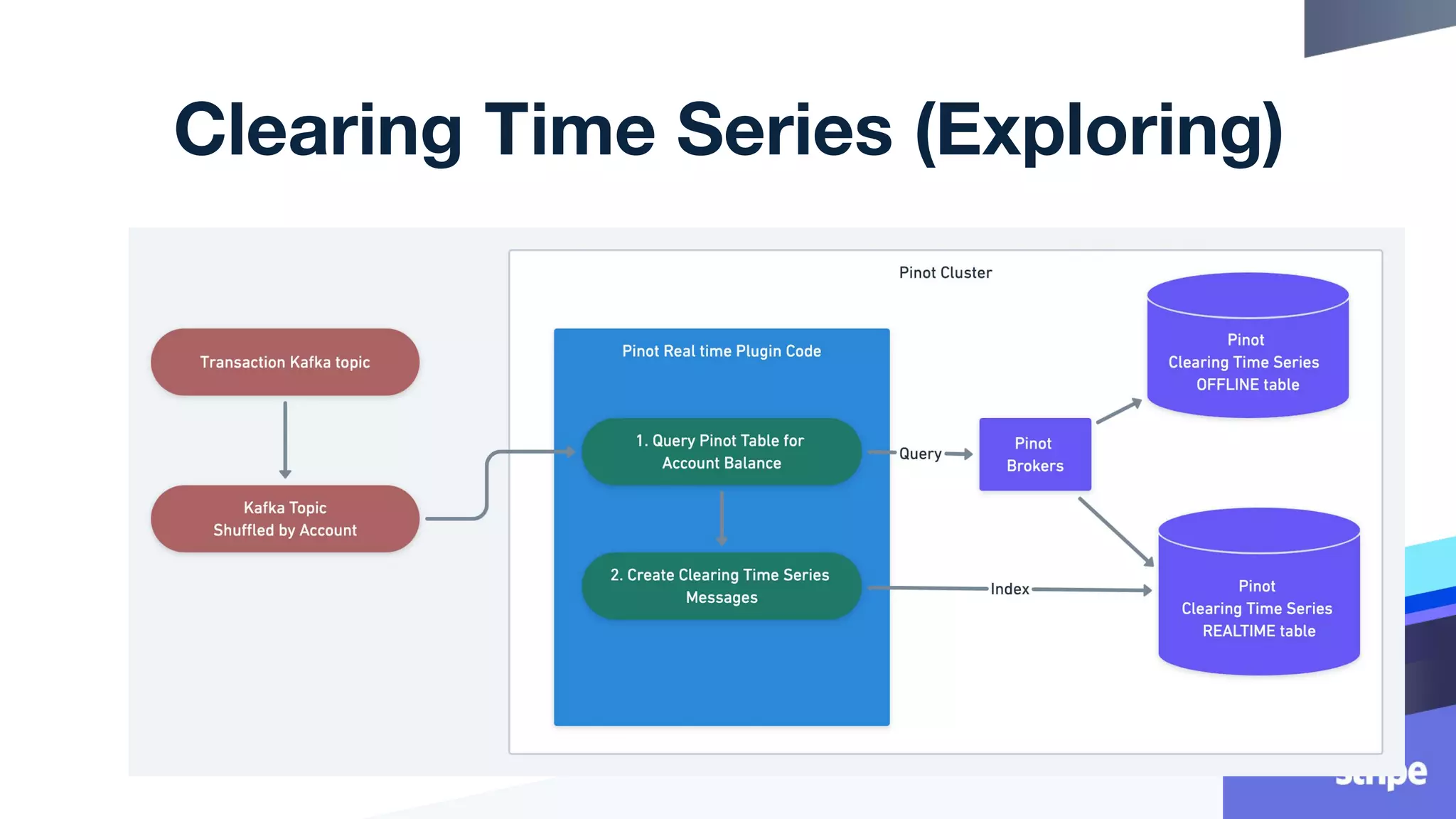
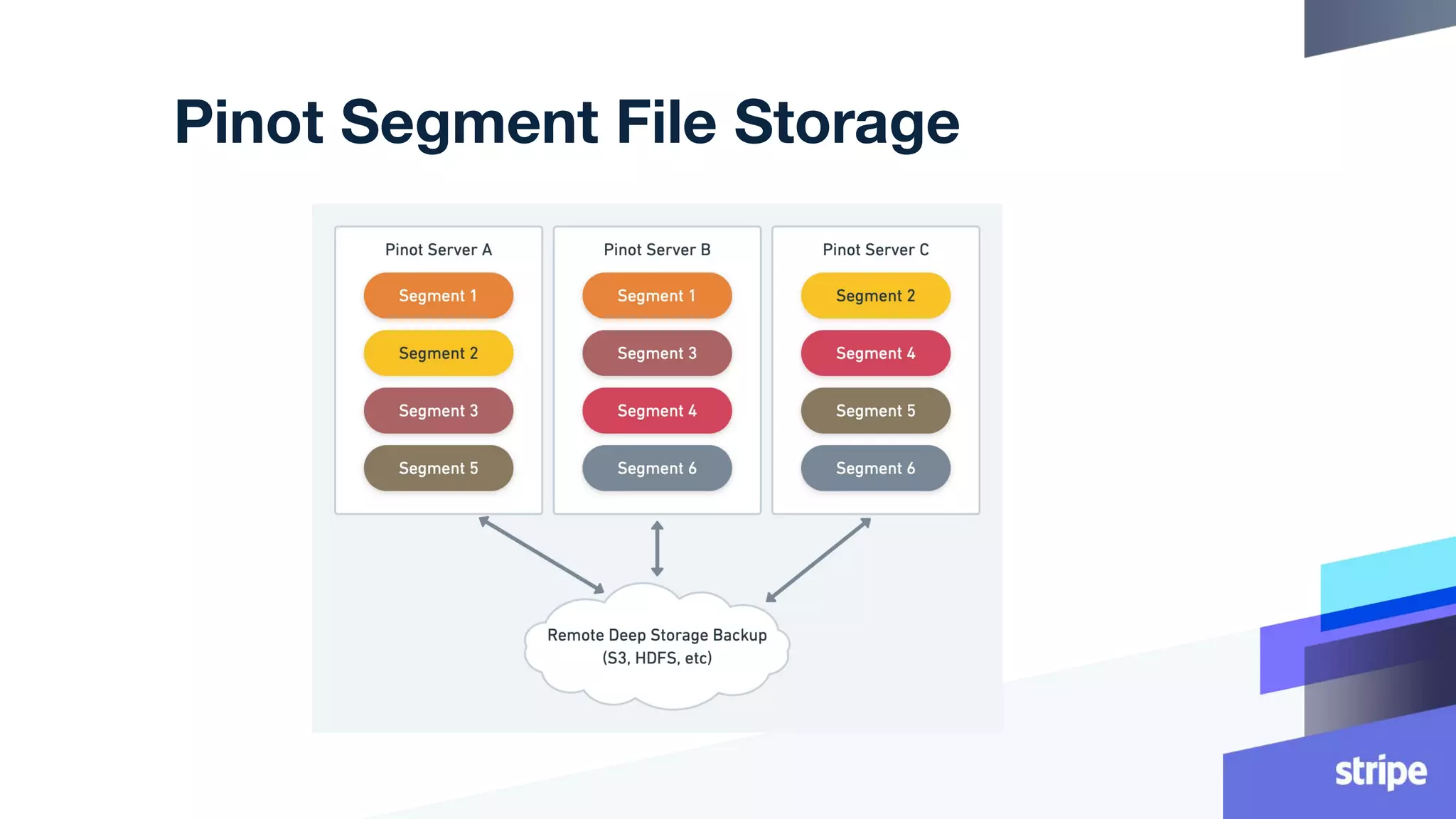

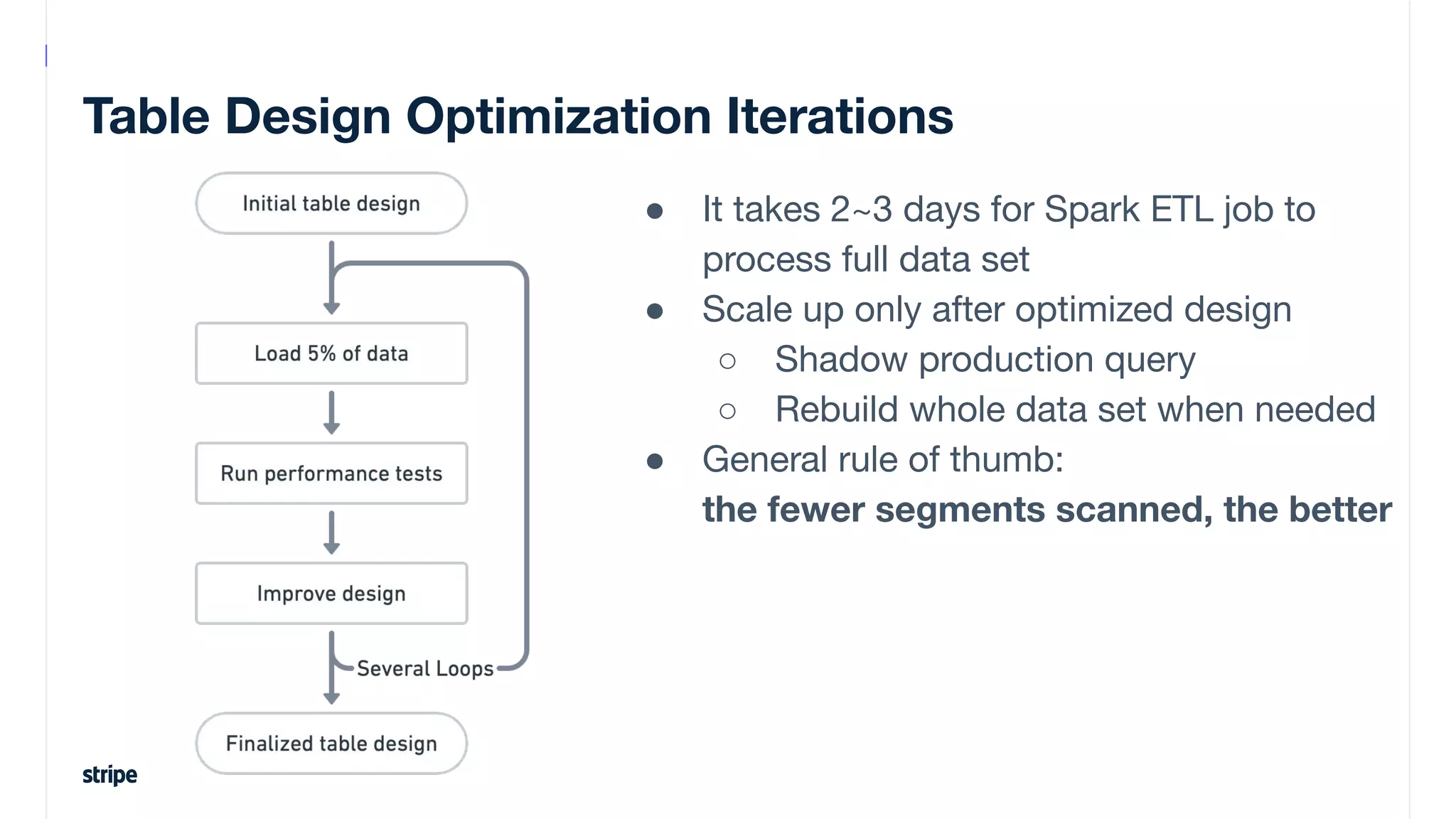


This document discusses the utilization of Apache Pinot and Apache Kafka to manage petabyte-scale financial data at Stripe, addressing challenges related to data scale, freshness, and query latency. It emphasizes the introduction of a unified system that enables real-time financial activity tracking through advanced query optimization techniques and technologies. The conclusion outlines future plans to further enhance efficiency and reduce costs in data handling while continuing to support crucial financial precision requirements.









































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)











