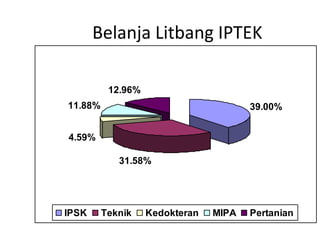
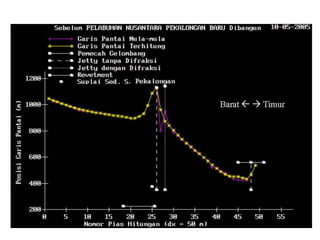
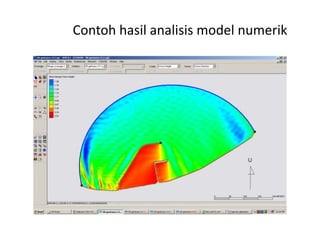
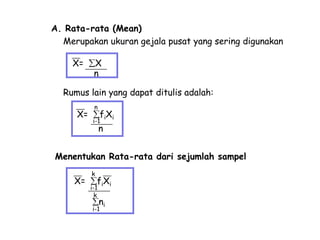
Dokumen ini membahas tentang statistika, termasuk pengertian, jenis, dan peranannya dalam kehidupan sehari-hari serta penelitian. Selain itu, dijelaskan juga mengenai pengukuran, data statistik, serta analisis dengan metode deskriptif dan inferensial. Pengukuran validity, penggolongan penelitian, dan ukuran gejala pusat, termasuk mean, median, dan modus, juga diuraikan secara rinci.

























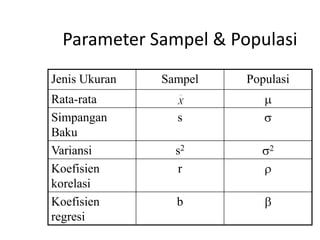


![C. Rata-rata Simpangan
merupakan jumlah harga mutlak skor simpangan dibagi
dengan banyaknya data (n)
x=
n
[Xi-X]
n=1
n
D. Variasi (s2) dan Simpangan Buku (s)
Merupakan dua buah ukuran yang paling sering digunakan
tentang variasi suatu perangkat data
Variasi adalah kuadrat dari simpangan baku, & sebaliknya,
simpangan baku adalah akar.](https://image.slidesharecdn.com/1mat-ter0912-131025182004-phpapp02/85/MATEMATIKA-TERAPAN-MODUS-MEAN-MEDIAN-VARIAN-SIMPANGAN-BAKU-REGRESI-37-320.jpg)