Show and Tell:
A Neural Image Caption Generator
참고자료
1. “Show and Tell: A Neural Image Caption Generator”, O.Vinyals, A.Toshev,
S.Bengio, D.Erhan
2. CV勉強会@関東「CVPR2015読み会」発表資料, 皆川卓也
3. Lecture Note “Recurrent Neural Networks”, CS231n, Andrej Karpathy
2016. 7.
김홍배
한국항공우주연구원
2.
개요
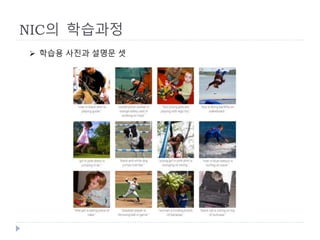
1장의 스틸사진으로부터 설명문(Caption)을 생성
자동번역등에 사용되는 Recurrent Neural Networks (RNN)에 Deep
Convolutional Neural Networks에서 생성한 이미지의 특징벡터를
입력
Neural Image Caption (NIC)
종래방법을 크게 상회하는 정확도
3.
Convolutional Neural Networks(CNN)
CNN이 「학습데이터로부터 이미지 인식에 효과적인 특징들을
자동으로 학습하는 네트워크」 라는 것을 이해하고 있어야 함
GoogLeNet을 개량한 아래 논문을 사용
S.Ioffe and C.Szegedy, “Batch Normalization: Accelerating Deep
Network Training by Reducing Internal Covariate Shift”, arXiv
2015
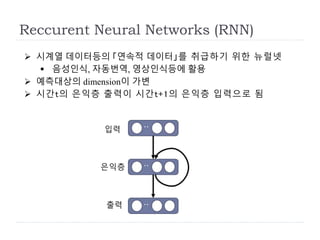
Reccurent Neural Networks(RNN)
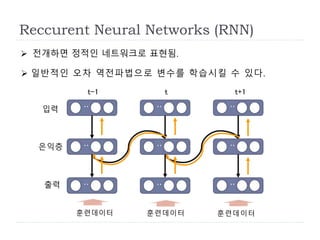
전개하면 정적인 네트워크로 표현됨.
・・・・・・
・・・・・・
・・・・・・
t-1 t t+1
출력
은익층
입력
훈련데이터 훈련데이터 훈련데이터
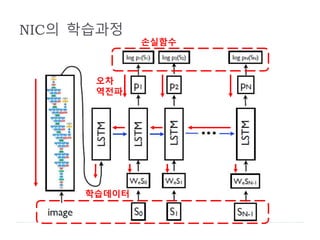
일반적인 오차 역전파법으로 변수를 학습시킬 수 있다.
6.
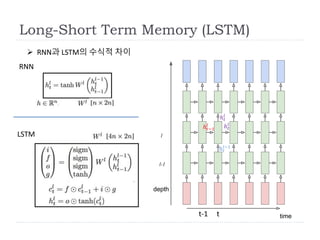
Long-Short Term Memory(LSTM)
RNN은 계열이 길어지면 계층이 깊어지므로 전파된 오차구배가
발산 또는 소멸됨.
Gradient Vanishing or Explosion
각 데이터의 입출력 및 과거 데이터의 사용/미사용을 제어함으로써,
긴 계열을 취급가능.
Long-Short Term Memory (LSTM)
f
x
i g
x
+
tanh
o
x
f
x
i g
x
+
tanh
o
x
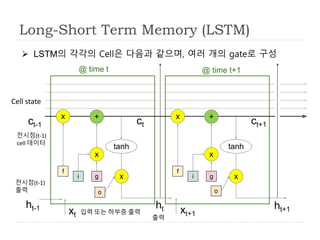
@time t
ht-1
xt xt+1
ht ht+1
ct-1
Cell state
ct ct+1
Long-Short Term Memory (LSTM)
@ time t+1
LSTM의 각각의 Cell은 다음과 같으며, 여러 개의 gate로 구성
입력 또는 하부층 출력
전시점(t-1)
cell 데이터
전시점(t-1)
출력
출력
9.
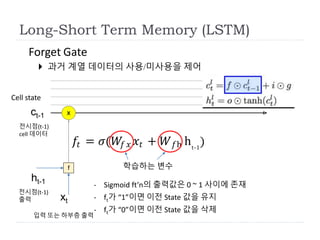
f
Forget Gate
과거계열 데이터의 사용/미사용을 제어
𝑓𝑡 = 𝜎(𝑊𝑓 𝑥 𝑥𝑡 + 𝑊 𝑓h ht-1
)
x
Long-Short Term Memory (LSTM)
ct-1
ht-1
xt
- Sigmoid ft’n의 출력값은 0 ~ 1 사이에 존재
- ft가 “1”이면 이전 State 값을 유지
- ft가 “0”이면 이전 State 값을 삭제
Cell state
학습하는 변수
입력 또는 하부층 출력
전시점(t-1)
cell 데이터
전시점(t-1)
출력
10.
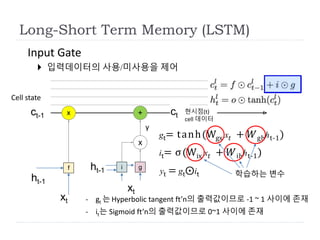
Input Gate
입력데이터의사용/미사용을 제어
Long-Short Term Memory (LSTM)
i g
x
f
gt= tanh(Wgx x𝑡 + 𝑊ghht-1)
xct-1
ht-1
xt - gt 는 Hyperbolic tangent ft’n의 출력값이므로 -1 ~ 1 사이에 존재
- it는 Sigmoid ft’n의 출력값이므로 0~1 사이에 존재
Cell state
+
it= σ(Wix x𝑡 + 𝑊ihht-1)
yt = gt⨀it
y
학습하는 변수
ht-1
xt
ct
현시점(t)
cell 데이터
11.
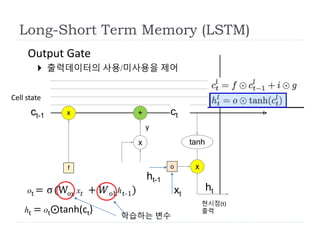
Output Gate
출력데이터의사용/미사용을 제어
Long-Short Term Memory (LSTM)
x
f
ot = σ(Wox x𝑡 + 𝑊ohht-1)
xct-1
Cell state
+
ht = ot⨀tanh(ct)
y
학습하는 변수
tanh
o x
ht
ht-1
xt
ct
현시점(t)
출력
12.
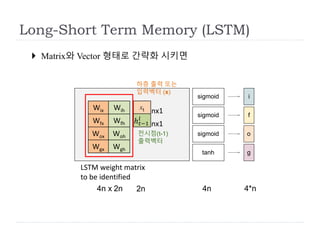
Long-Short Term Memory(LSTM)
i
f
o
g
sigmoid
sigmoid
tanh
sigmoid
4n x 2n 4n 4*n
nx1
nx1
Wix Wih
Wfx Wfh
Wox Woh
Wgx Wgh
xt
ℎ 𝑡−1
𝑙
2n
Matrix와 Vector 형태로 간략화 시키면
LSTM weight matrix
to be identified
하층 출력 또는
입력벡터 (x)
전시점(t-1)
출력벡터
13.
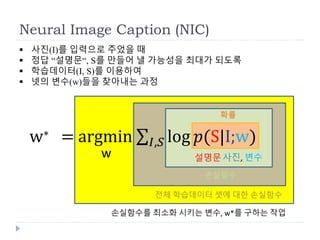
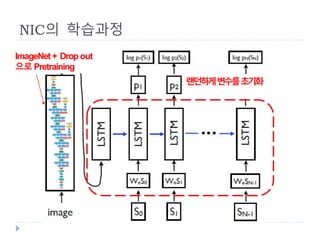
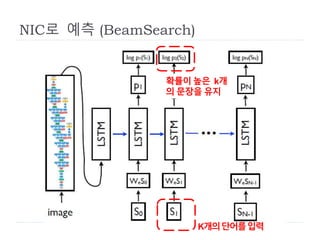
Neural Image Caption(NIC)
사진(I)를 입력으로 주었을 때
정답 “설명문“, S를 만들어 낼 가능성을 최대가 되도록
학습데이터(I, S)를 이용하여
넷의 변수(w)들을 찾아내는 과정
설명문
w∗ = argmin 𝐼,𝑆 log (S|I;w)
w 사진, 변수
확률
손실함수
전체 학습데이터 셋에 대한 손실함수
손실함수를 최소화 시키는 변수, w*를 구하는 작업
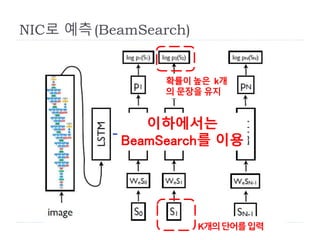
14.
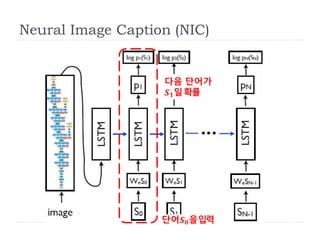
Neural Image Caption(NIC)
사진으로부터 설명문 생성
𝑝 𝑆 𝐼; 𝑤 =
𝑡=0
𝑁
𝑝 𝑆𝑡 𝐼, 𝑆0, 𝑆1,···, 𝑆𝑡−1; 𝑤
단어수
각 단어는 그전 단어열의 영향을 받는다.
𝑆 ={𝑆0, 𝑆1, ⋯}
단어, 따라서 설명문 S는 길이가 변하는 계열데이터
15.
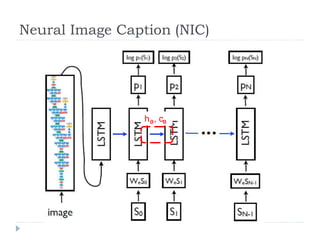
Neural Image Caption(NIC)
사진으로부터 설명문 생성
𝑝 𝑆 𝐼; 𝑤 =
𝑡=0
𝑁
𝑝 𝑆𝑡 𝐼, 𝑆0, 𝑆1,···, 𝑆𝑡−1; 𝑤
학습 데이터 셋(I,S)로 부터 훈련을 통해 찾아내는 변수
16.
ht-1
xt
단어 @ t
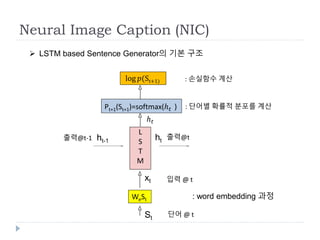
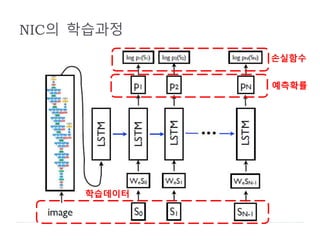
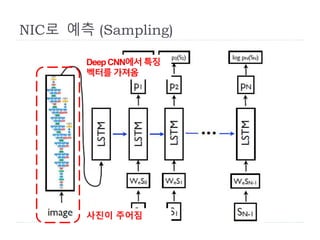
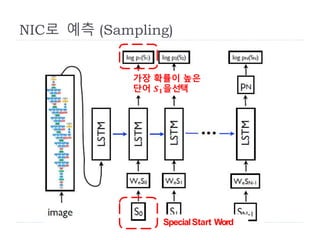
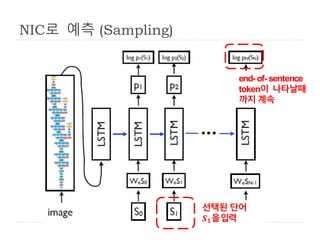
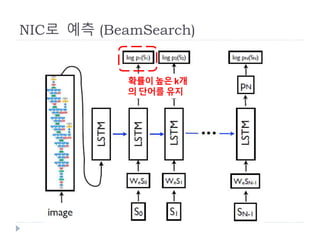
NeuralImage Caption (NIC)
St
L
S
T
M
WeSt
입력 @ t
출력@t
Pt+1(St+1)=softmax(ℎ 𝑡 )
LSTM based Sentence Generator의 기본 구조
ℎ 𝑡
: 단어별 확률적 분포를 계산
ht
log (St+1) : 손실함수 계산
: word embedding 과정
출력@t-1
17.
17
Neural Image Caption(NIC)
Word Embedding
일반적으로 “one hot“ vector형태로 단어를 나타내는데,
단어들로 구성된 Dictionary의 크기가 바뀌기 쉬움
이경우 LSTM의 모델링등에 어려움이 있음
이에 따라 가변의 “one hot“ vector형태를 고정된 길이의
Vector형태로 변형시키는 과정이 필요
dog
0010000000
cat
one hot vector
representation
0000001000
Word embedding vector
representation
dog
0.10.30.20.10.20.3
cat
we
0.20.10.20.20.10.1
xtSt
18.
18
Neural Image Caption(NIC)
손실함수
For 𝑦_𝑖 = 1 𝑐𝑎𝑠𝑒 J(w)=-log𝑦𝑖
𝑦𝑖
1
J(w)
As 𝑦𝑖 approaches to 1,
J(w) becomes 0
J(w)=-∑𝑦_𝑖•log𝑦𝑖
y : 분류기에서 추정한 확률값
y_ : 정답
Cross entropy로 정의함






















































![[기초개념] Recurrent Neural Network (RNN) 소개](https://cdn.slidesharecdn.com/ss_thumbnails/agistpurnndkim190430-190430140949-thumbnail.jpg?width=640&height=640&fit=bounds)






![[study] Long Text Generation via Adversarial Training with Leaked Information](https://cdn.slidesharecdn.com/ss_thumbnails/180716leakedgan-190321060331-thumbnail.jpg?width=640&height=640&fit=bounds)

![[224] backend 개발자의 neural machine translation 개발기 김상경](https://cdn.slidesharecdn.com/ss_thumbnails/224backendneuralmachinetranslation-161025025107-thumbnail.jpg?width=640&height=640&fit=bounds)

![[한국어] Neural Architecture Search with Reinforcement Learning](https://cdn.slidesharecdn.com/ss_thumbnails/nas-170612232020-thumbnail.jpg?width=640&height=640&fit=bounds)

















