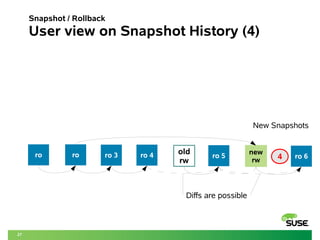
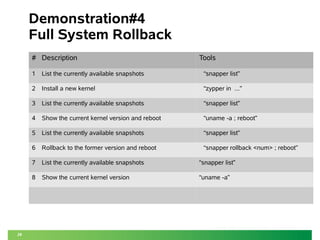
This document discusses using Btrfs and Snapper to enable full system rollbacks in Linux. It describes how snapshots are automatically created to capture the state of the system before changes. Using Snapper, administrators can rollback the entire system to a previous snapshot to undo changes or revert to a known good state. The document provides examples of rolling back packages, kernels and system configuration changes while ensuring system integrity and compliance.








![10
Introducing “Snapper” – CLI example
Snapper headers:
– Type : [ Pre | Post | Single ]
– # : Nr of snapshot
– Pre # : if type is “Post” the matching Pre nr.
– Date : timestamp
– Cleanup : cleanup algorithm for this snapshot
– Description : A fitting description of the snapshot (free
text)
– Userdata : key=value pairs to record all sorts of useful
information about the snapshot in an easily
parsable format](https://image.slidesharecdn.com/linuxconeurope2014fullsystemrollbackbtrfssnapper0-141022115607-conversion-gate01/85/Linux-con-europe_2014_f-10-320.jpg)