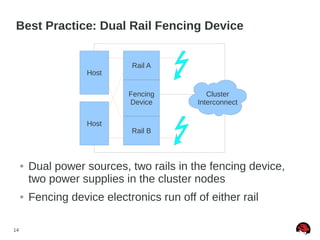
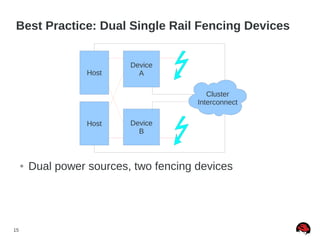
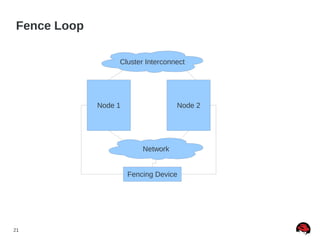
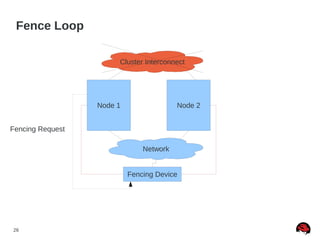
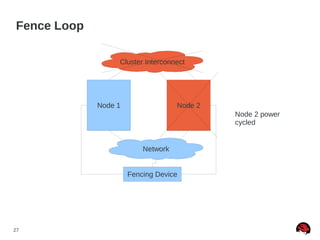
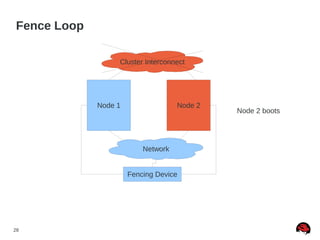
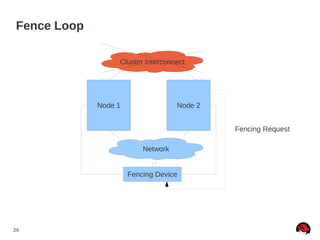
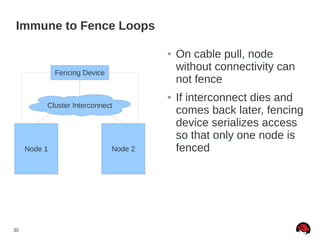
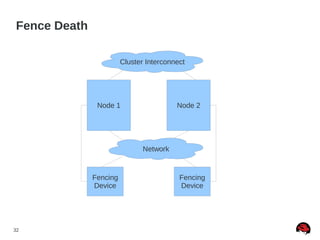
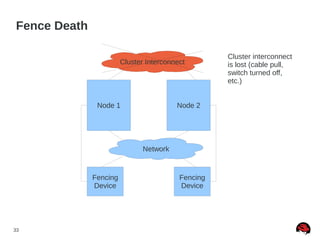
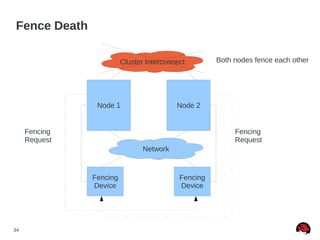
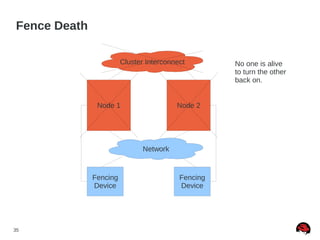
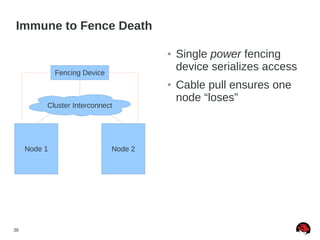
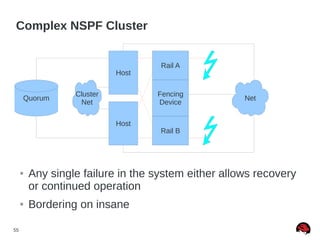
This document discusses best practices and common pitfalls for Red Hat clustering. It covers topics like I/O fencing, 2-node clusters, quorum disks, multipath considerations, and the clustered file system GFS2. The key recommendations are to choose simple configurations when possible, test all failure scenarios, and ensure all storage paths are fenced for SAN configurations. Complex configurations increase failure risk, so the document emphasizes testing and avoiding unnecessary complexity.























![42
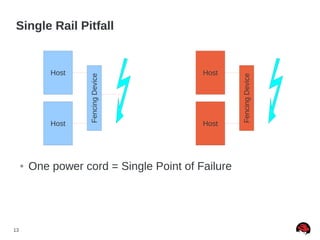
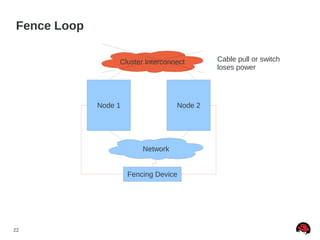
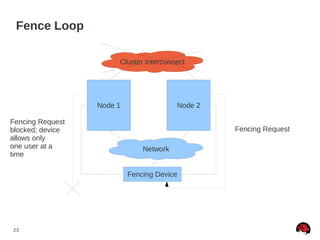
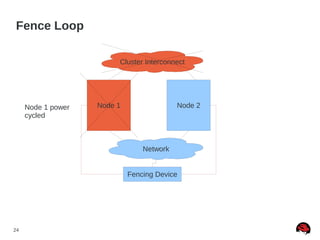
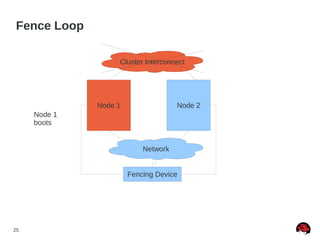
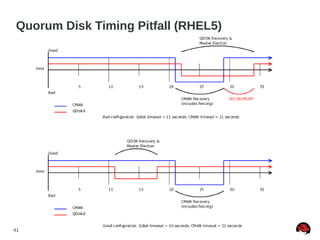
Quorum Disk Made “Simple” (RHEL5)
● Quorum disk failure recovery should be a bit less than
half of CMAN's failure time
● This allows for the quorum disk arbitration node to fail
over before CMAN times out
● Quorum disk failure recovery should be approximately
30% longer than a multipath failover. Example [1]:
● x = multipath failover
● x * 1.3 = quorum disk failover
● x * 2.7 = CMAN failover
[1] http://kbase.redhat.com/faq/docs/DOC-2882](https://image.slidesharecdn.com/clusterpitfallsrecommand-140328042609-phpapp02/85/Cluster-pitfalls-recommand-42-320.jpg)











































































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)