Download as PDF, PPTX




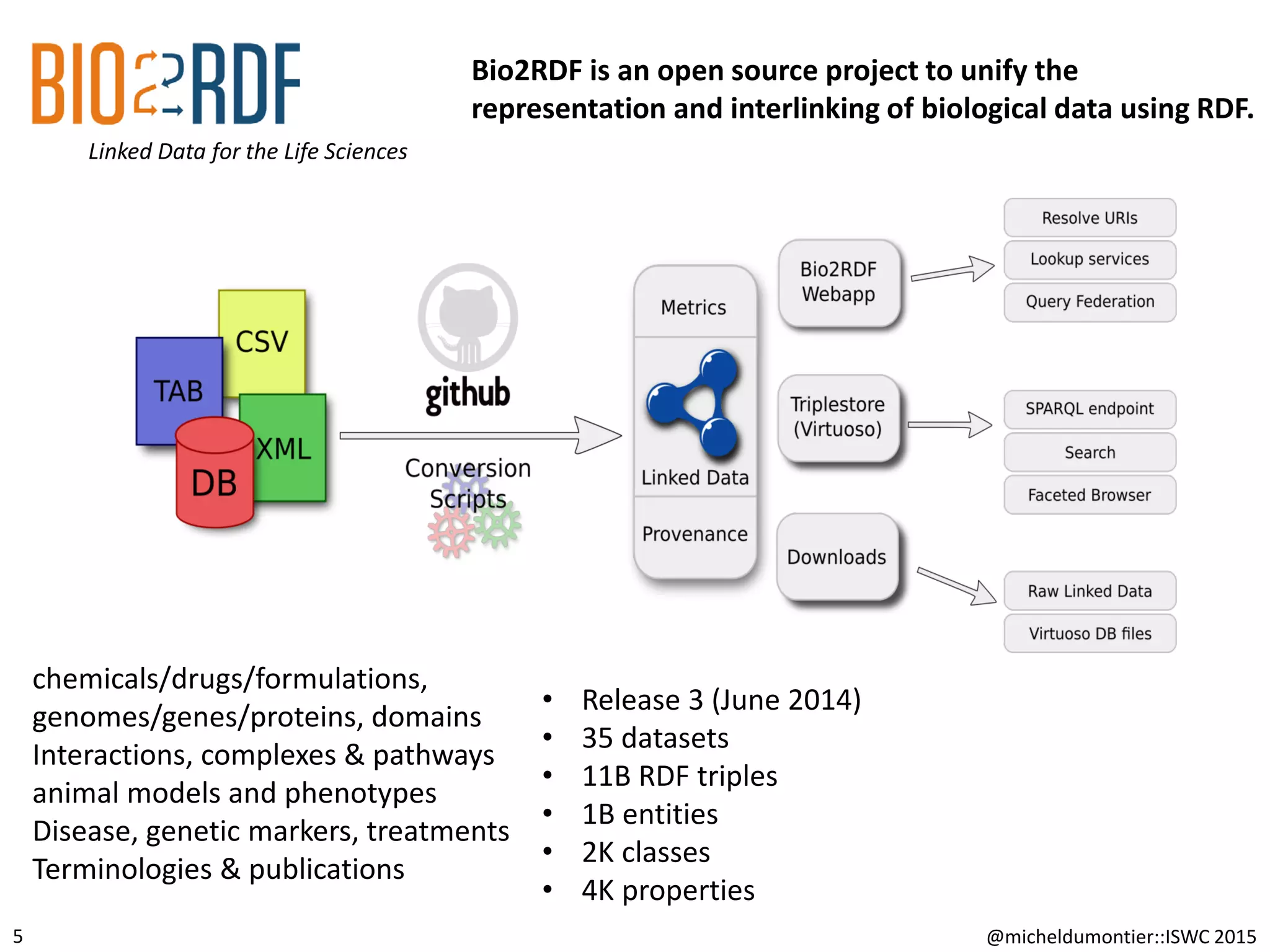
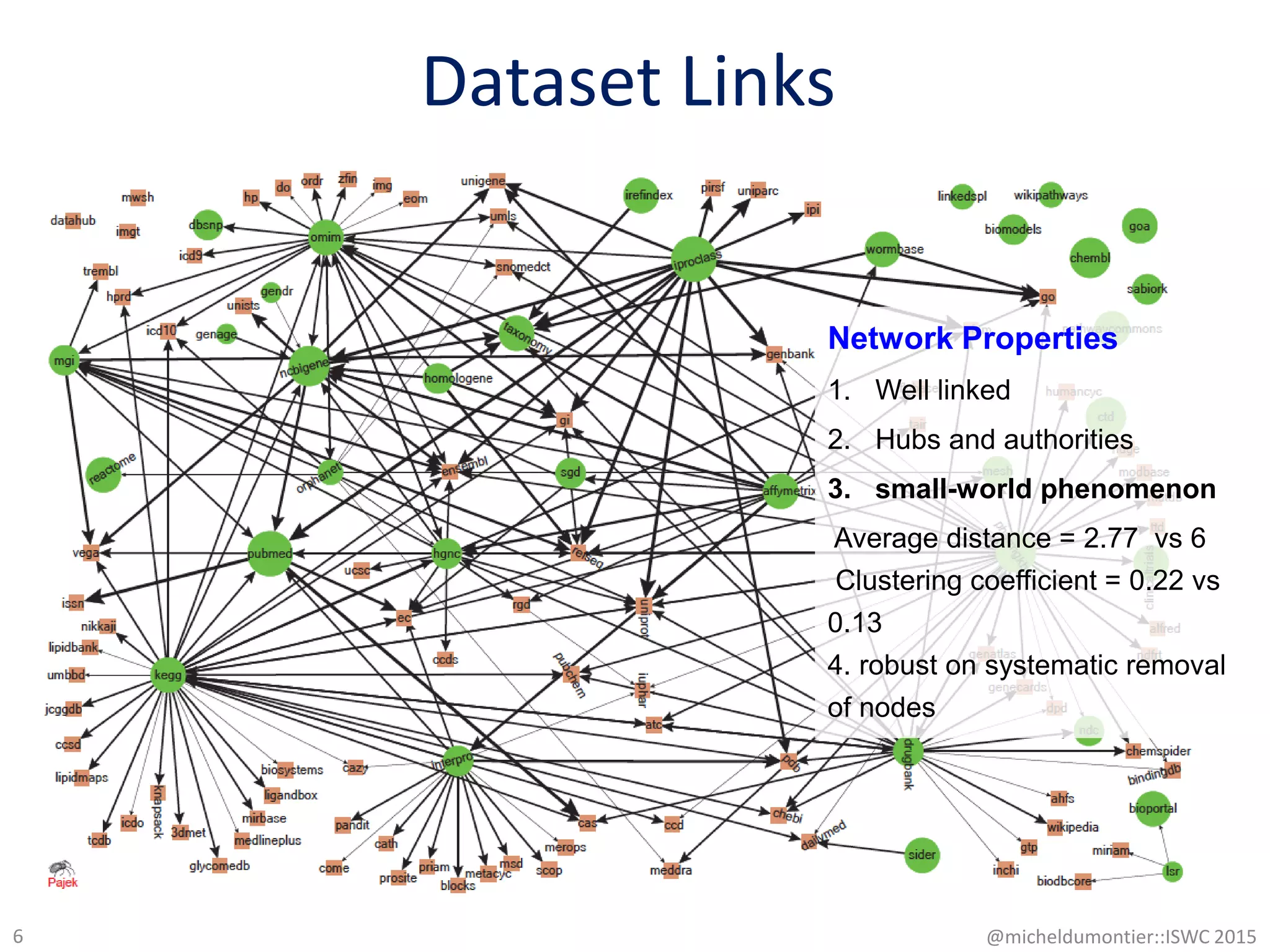
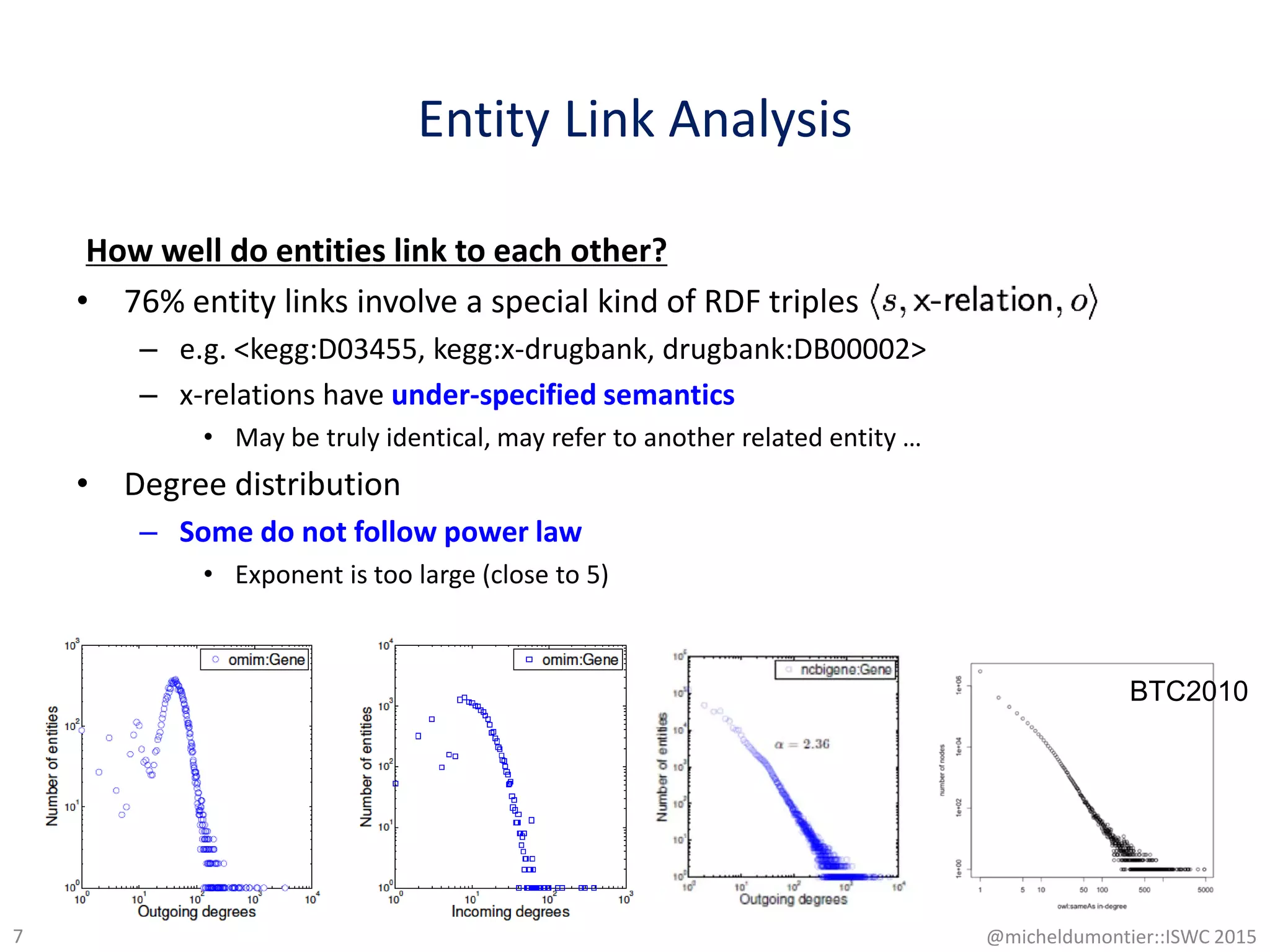








This document discusses link analysis in life sciences, highlighting the structure and quality of interconnected data, particularly through RDF and various linking types. It examines entity links between datasets, noting high rates of reciprocity in some cases, but significant incompleteness in others, and evaluates the accuracy of entity matching methods. Findings indicate that dataset, entity, and term link graphs do not share common characteristics typical of the semantic web, with challenges in maintaining consistent semantics among linked entities.






















































































