Download to read offline







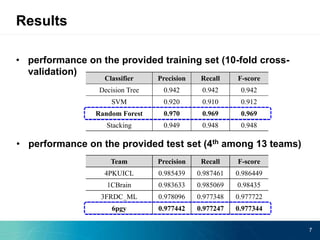


The document describes an ensemble approach for entity type prediction over linked data. It used random forest classification with features including entity properties, semantic similarities to labels, and named entities from abstracts. It performed well on both the training set with 10-fold cross validation and the test set, achieving the 4th highest F-score out of 13 participating teams in the Data Challenge.




















































































