Downloaded 72 times









![P3. Make sure all names are URIs
x T
[<x> IsOfType <T>]
different
owners & locations
< analgesic >](https://image.slidesharecdn.com/sssw2015-150708100434-lva1-app6891/75/The-Web-of-Data-do-we-actually-understand-what-we-built-10-2048.jpg)
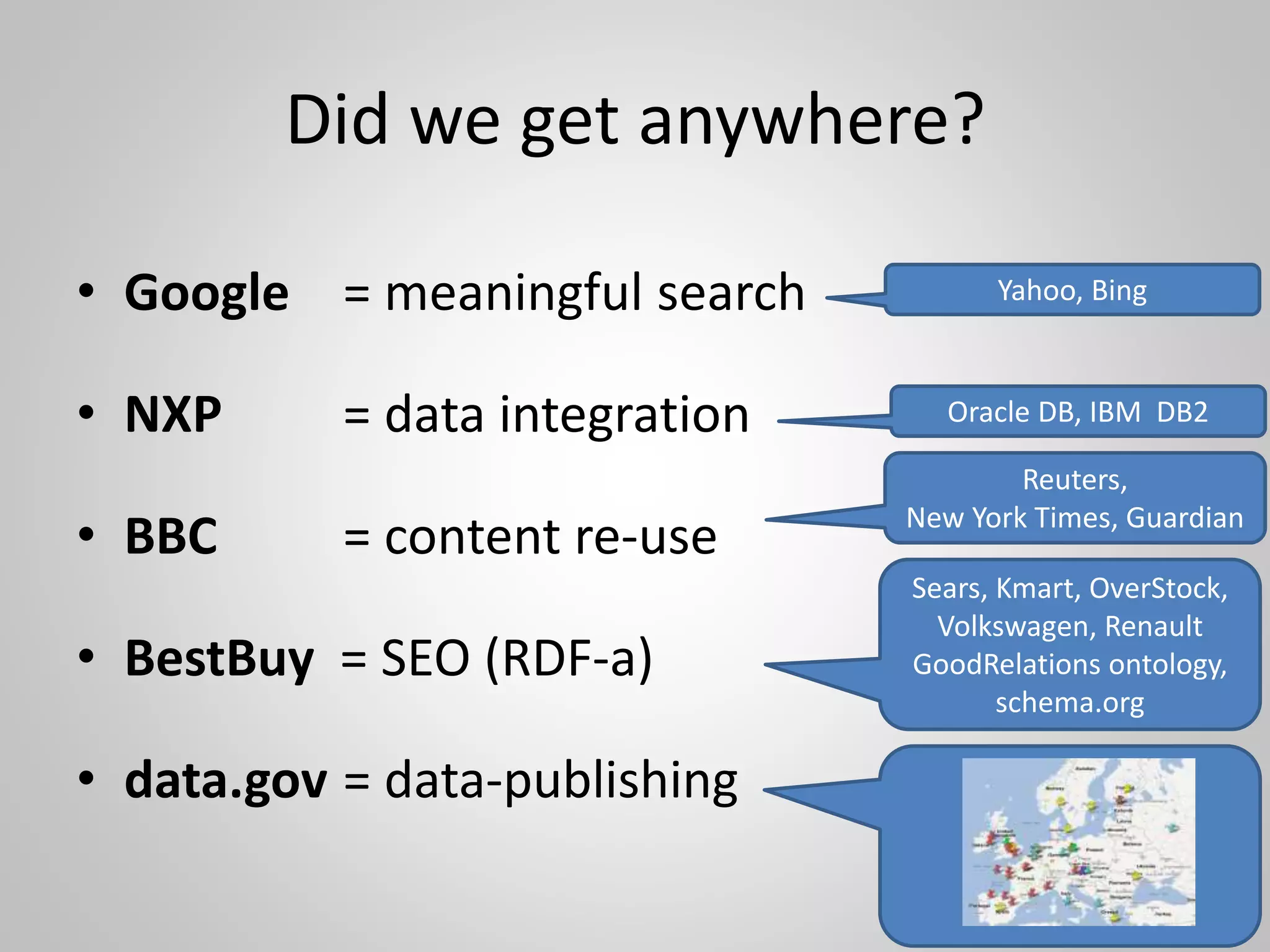


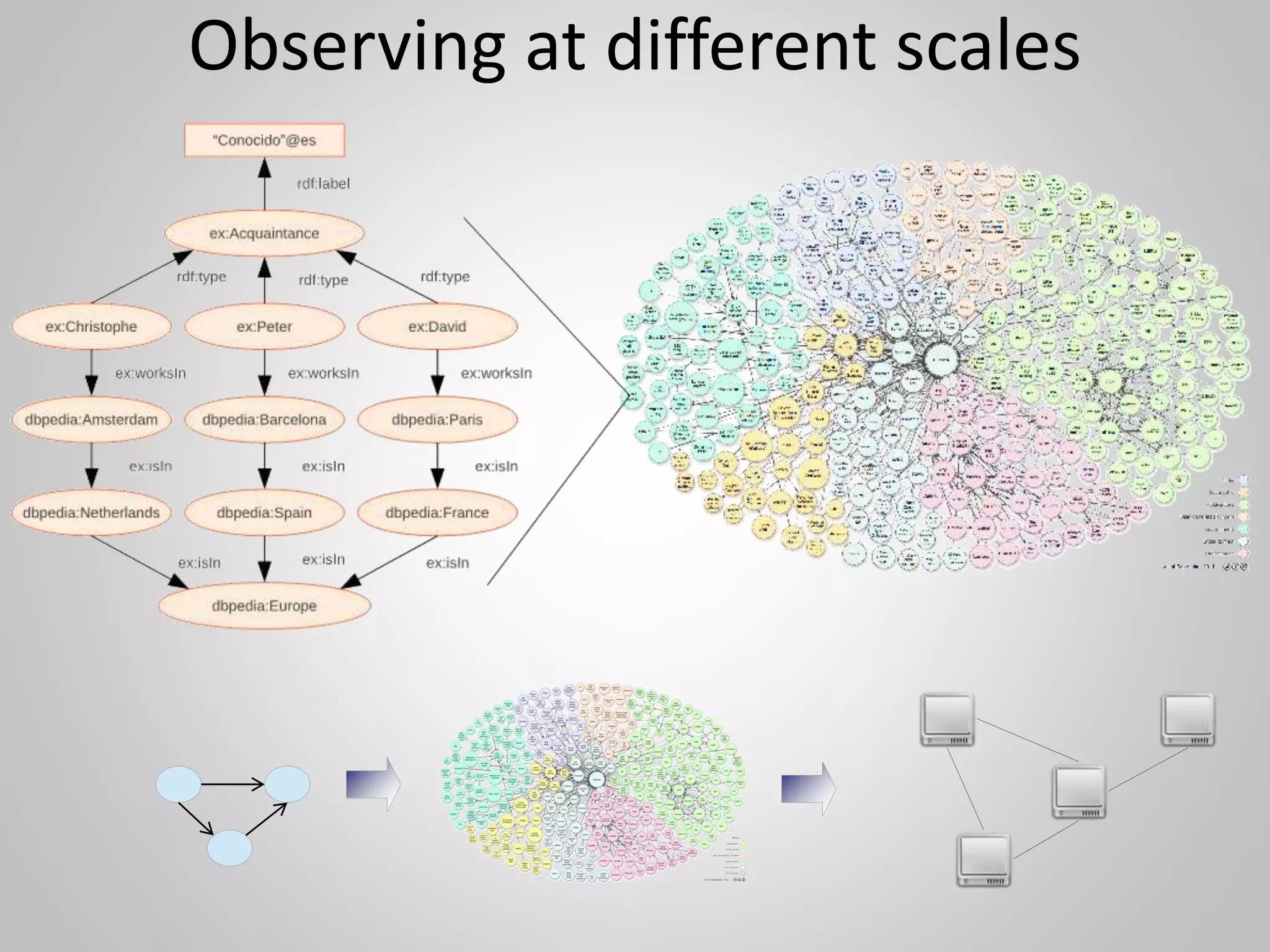
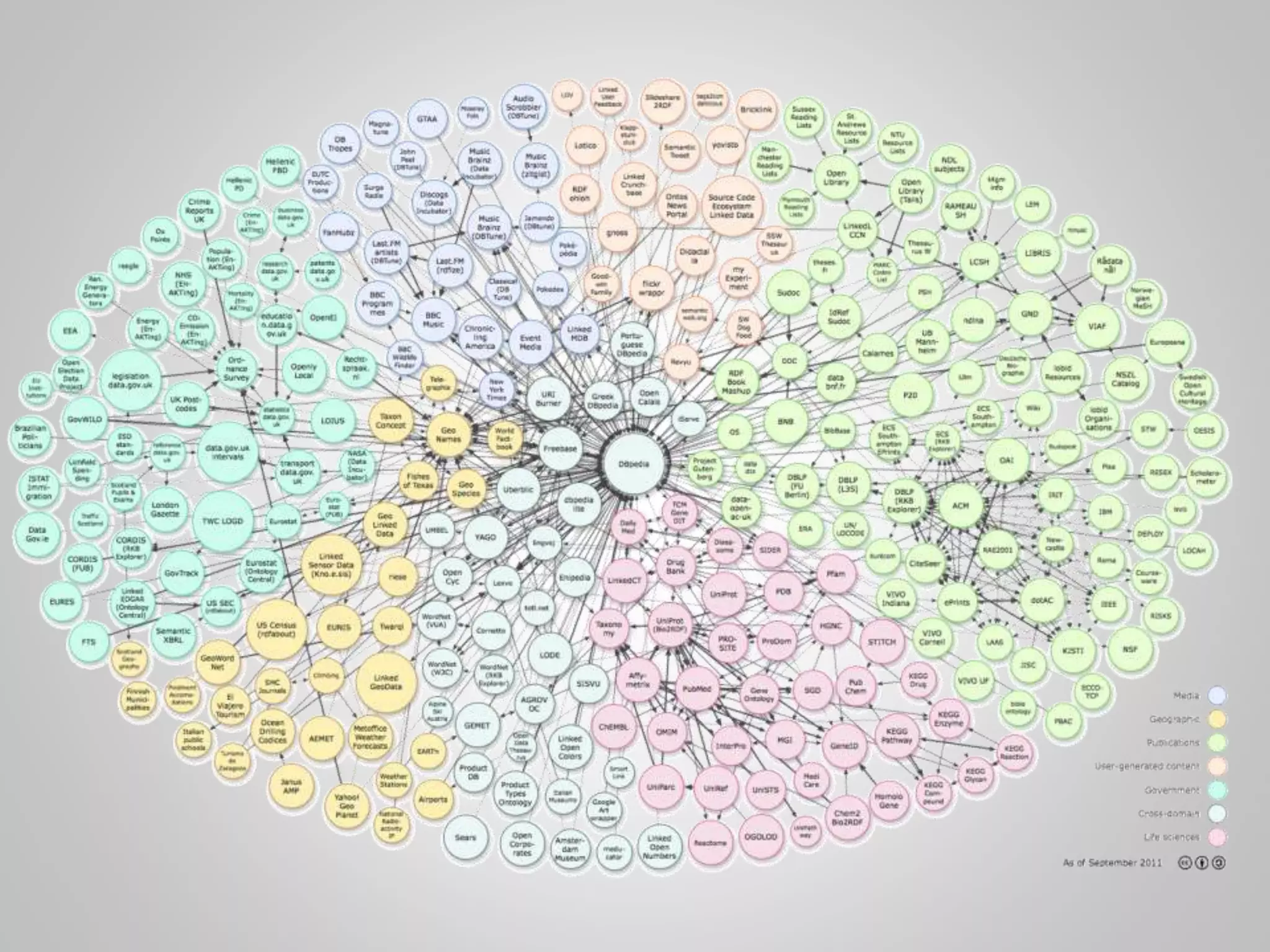
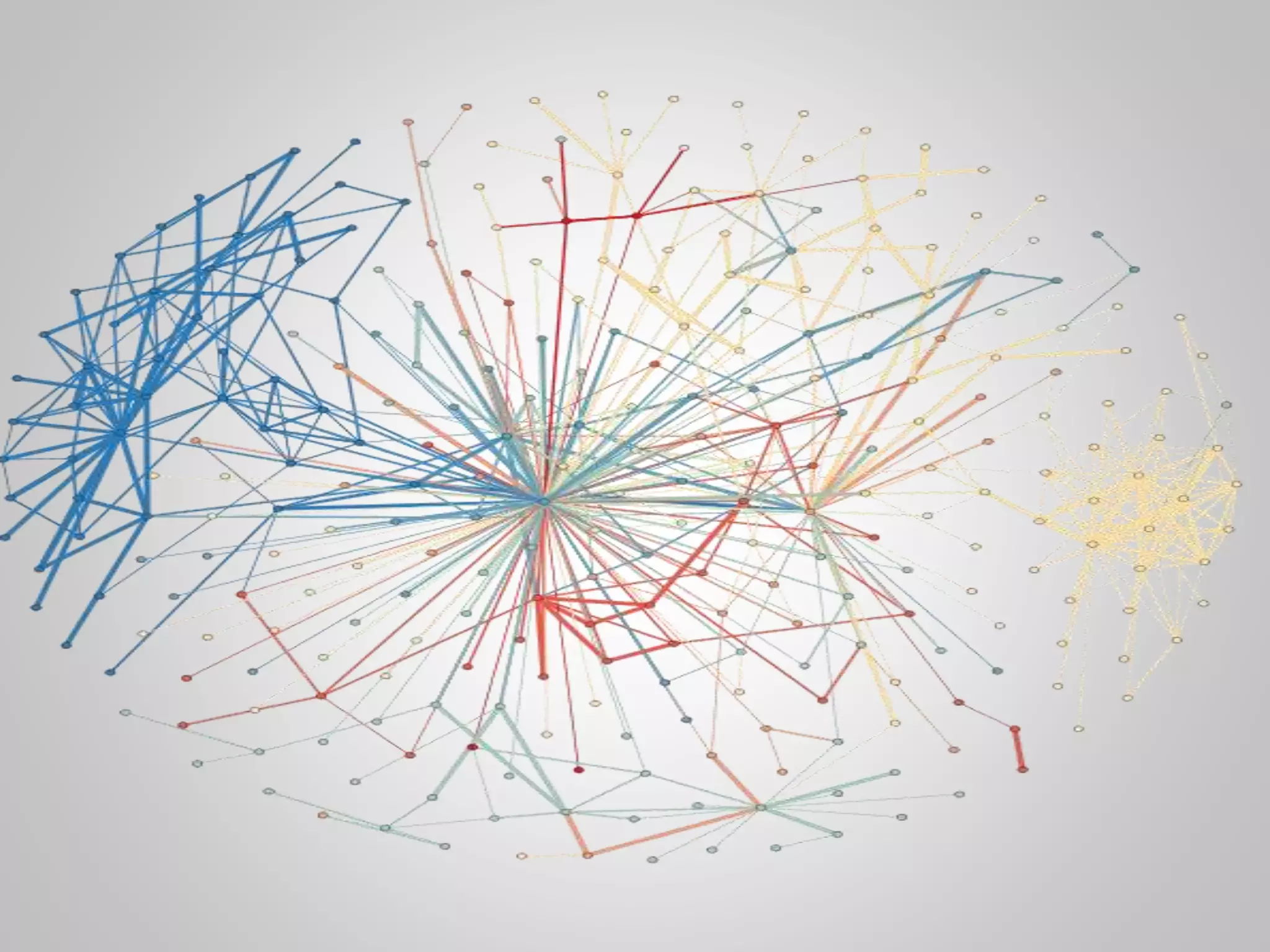
















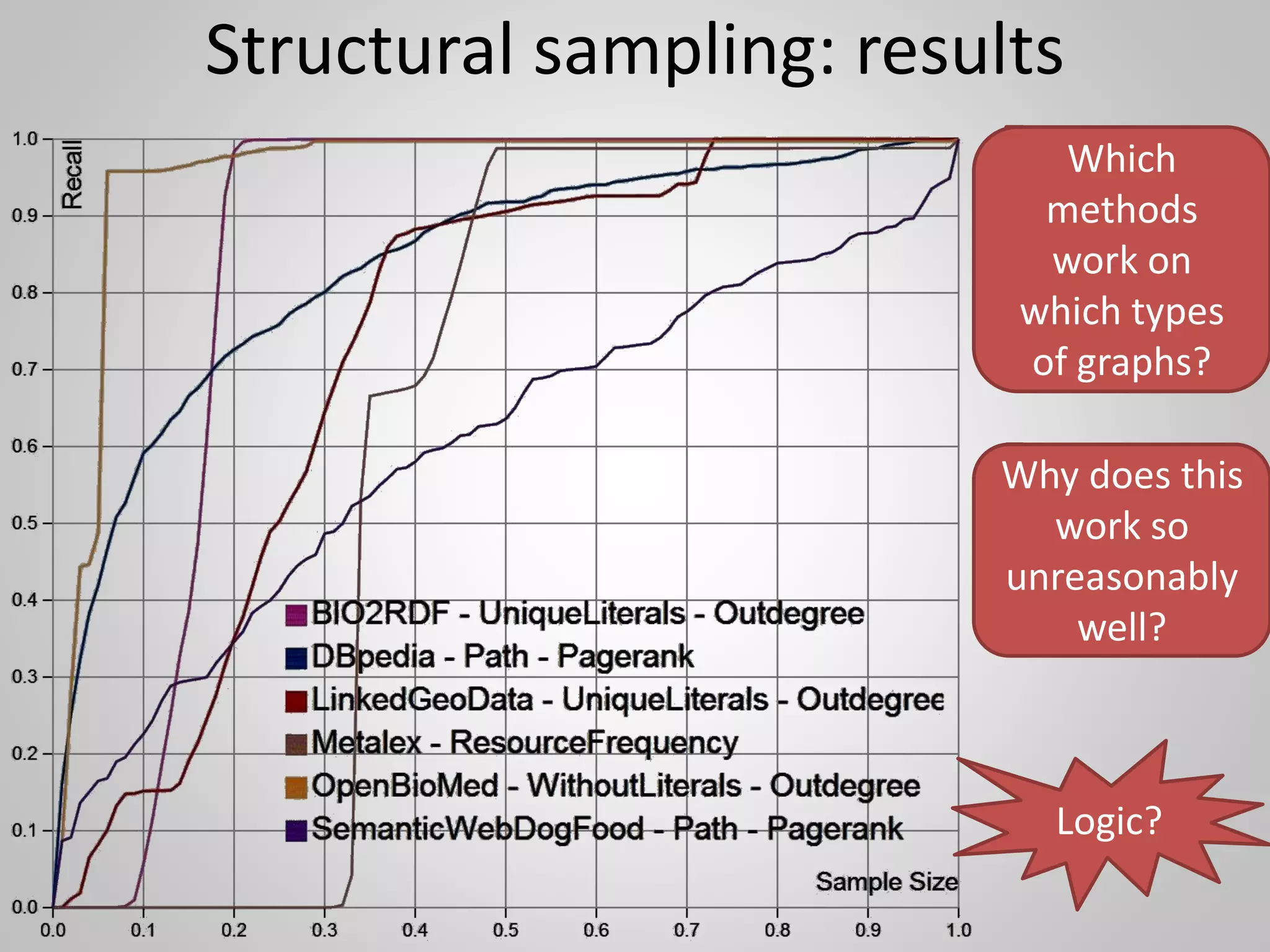






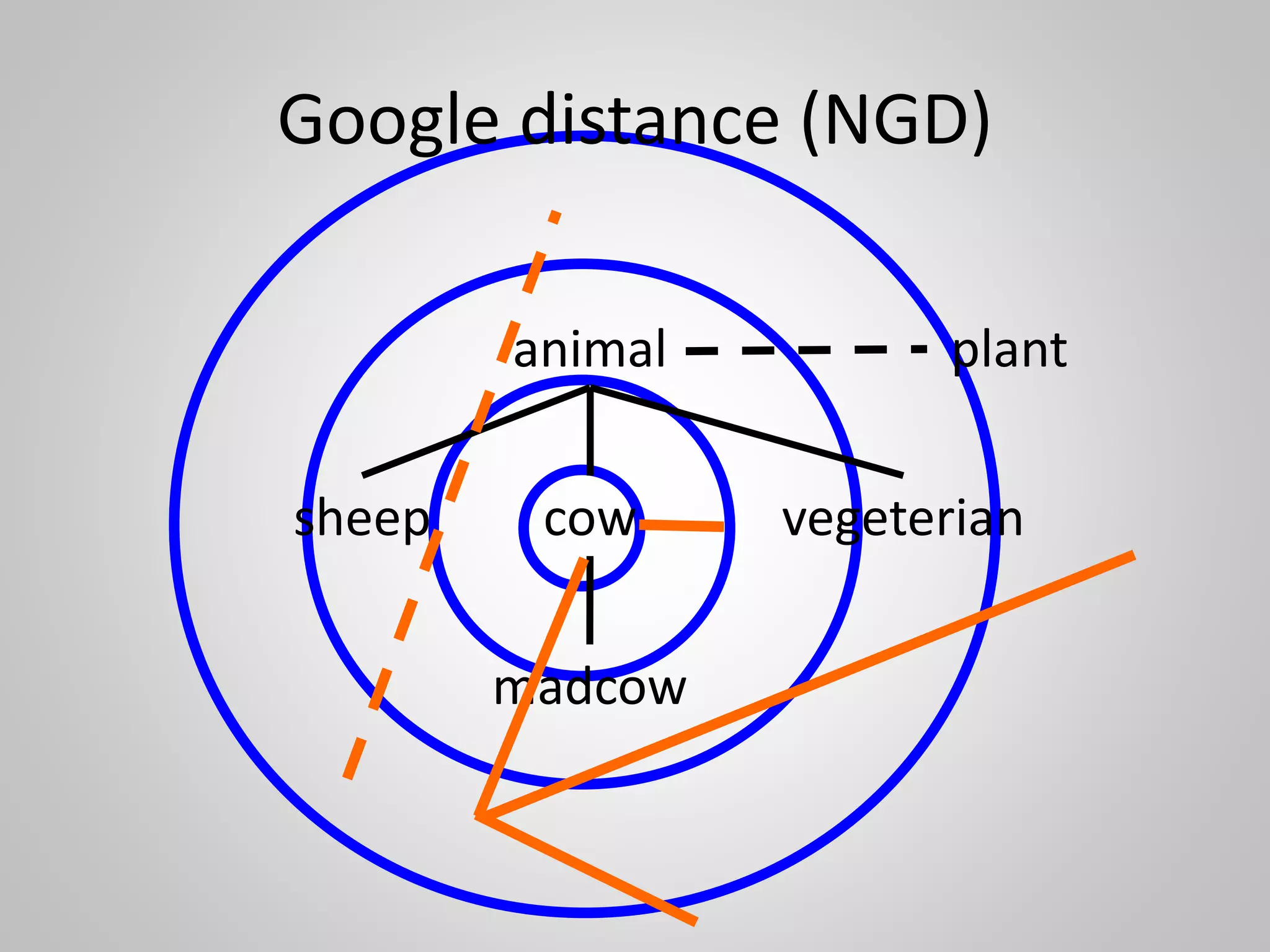








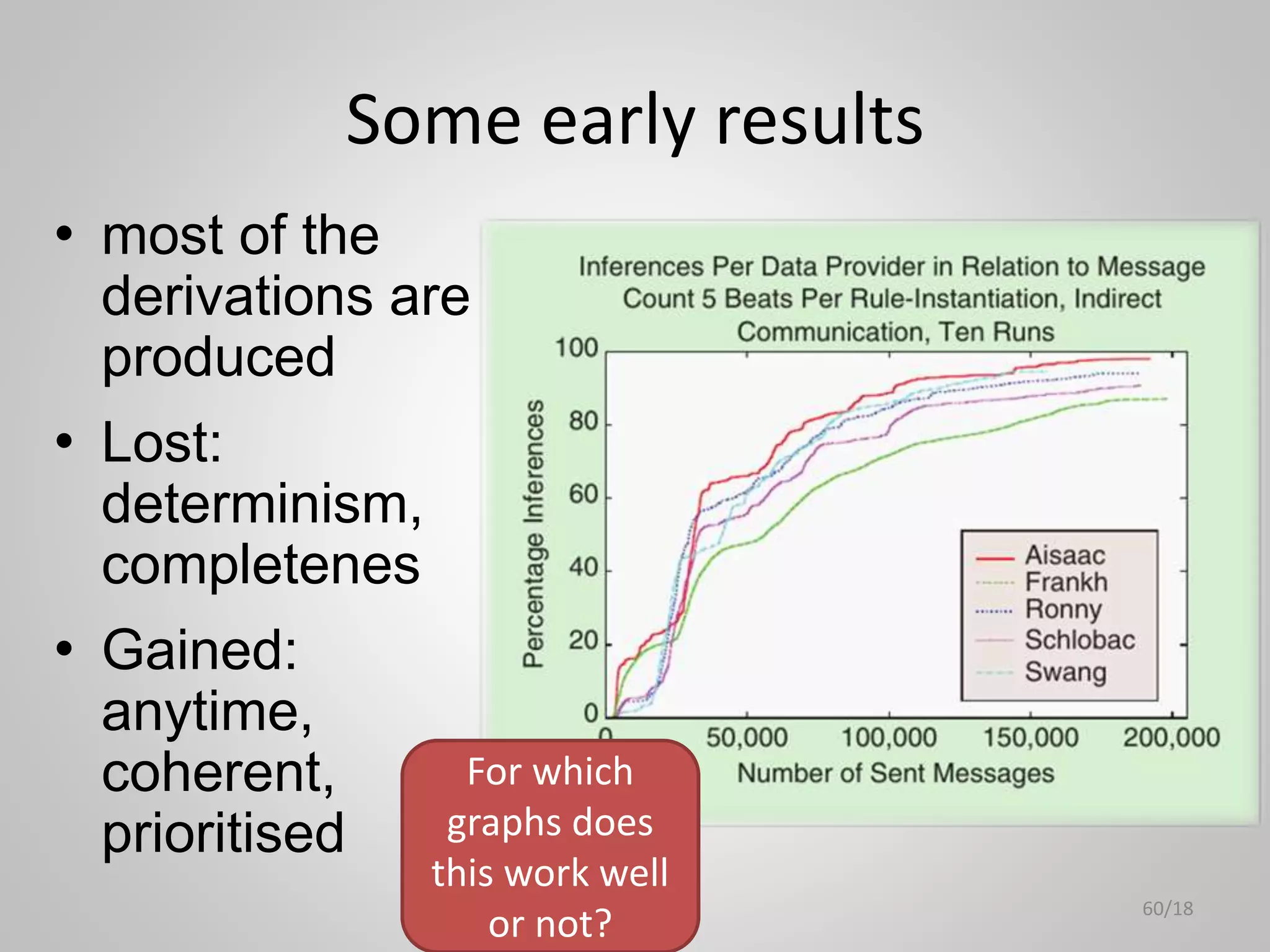










The document discusses the philosophical underpinnings of computer science, emphasizing the importance of questioning the 'why' behind technology rather than merely focusing on 'how' to implement it. It critiques the current state of the semantic web and proposes a structured approach for understanding data through methodologies such as graph theory and centrality measures. The author calls for researchers to not only build technology but to also seek a deeper understanding of the systems they create.























































































