Download as PDF, PPTX



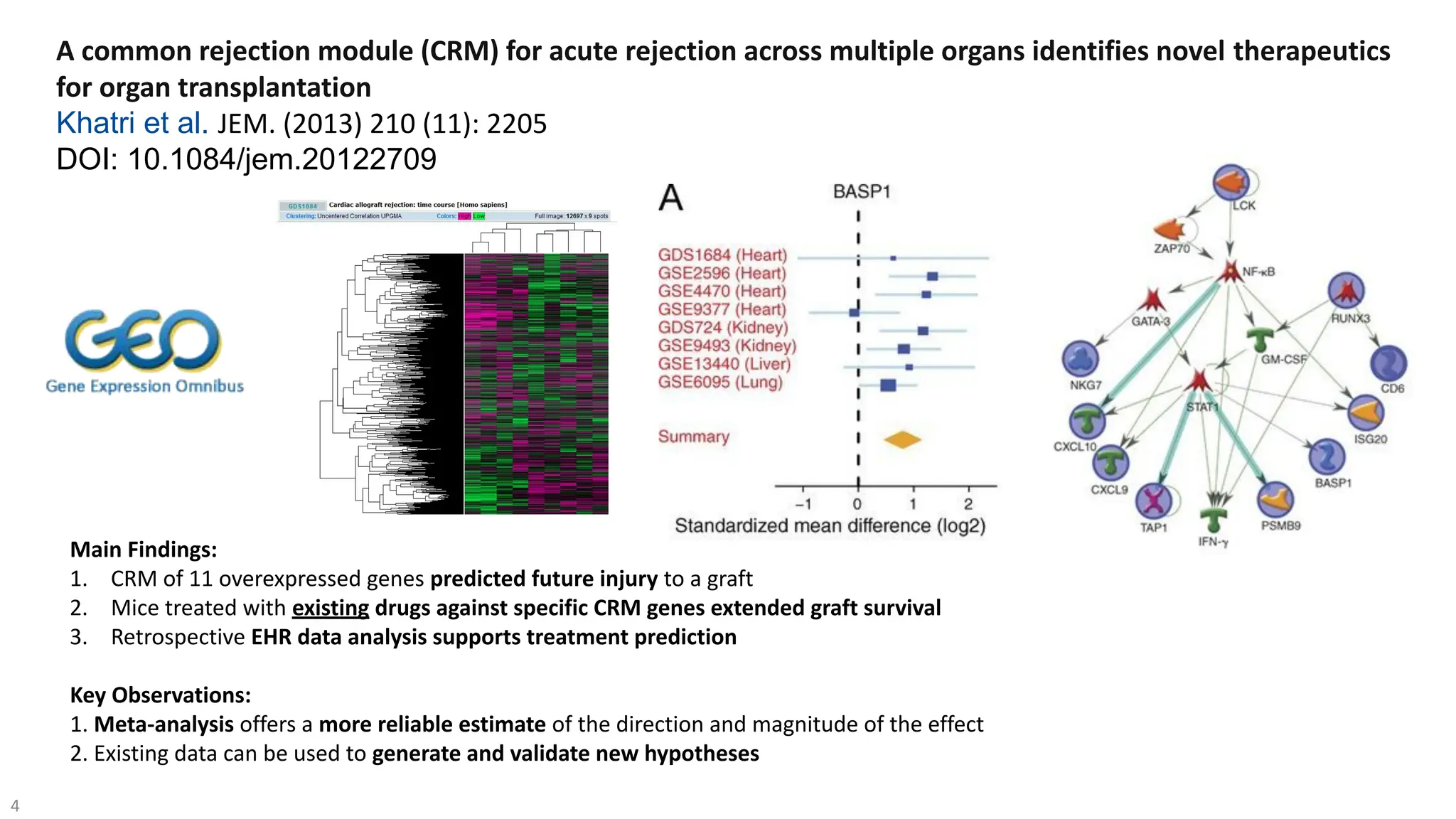

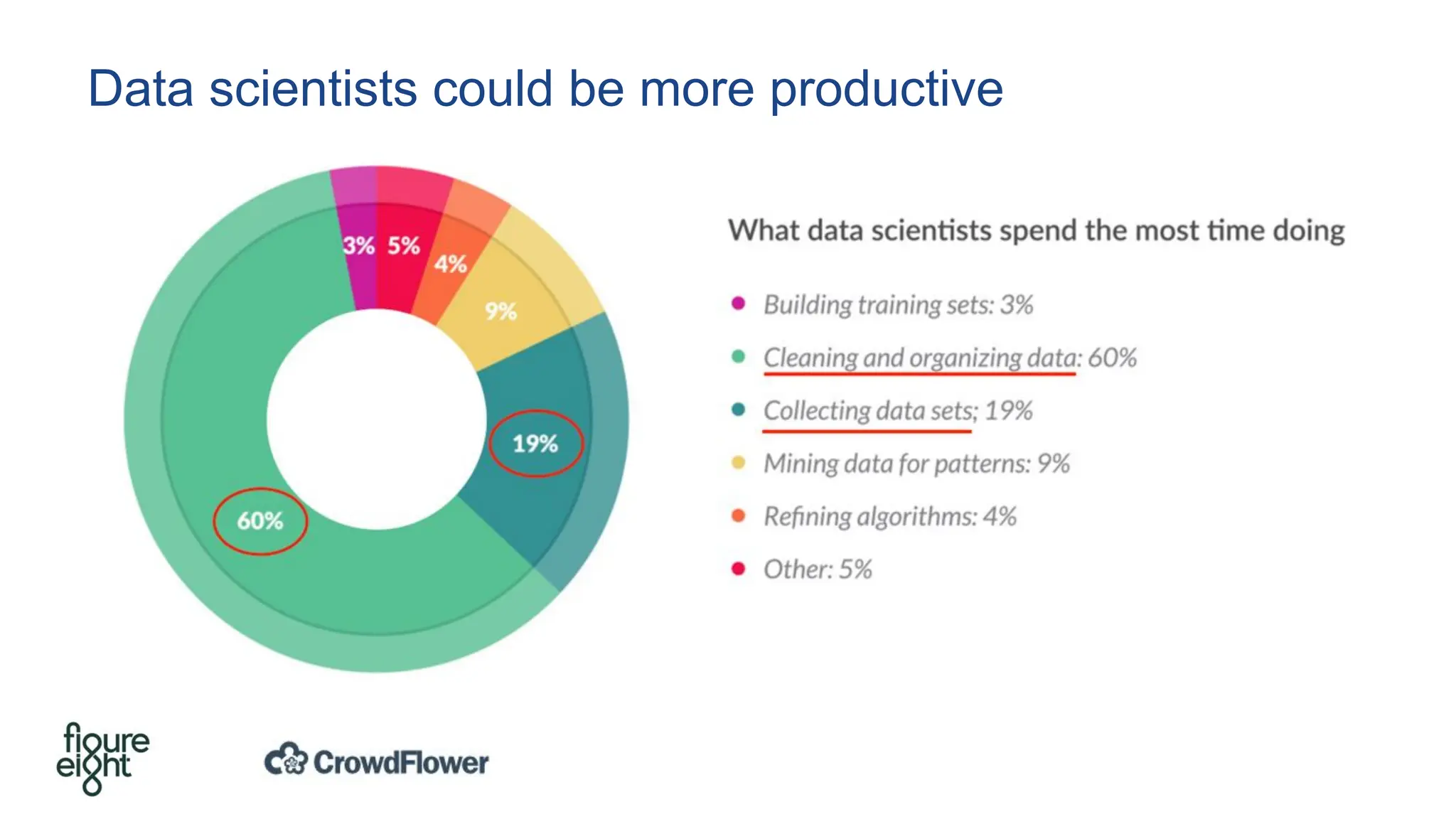

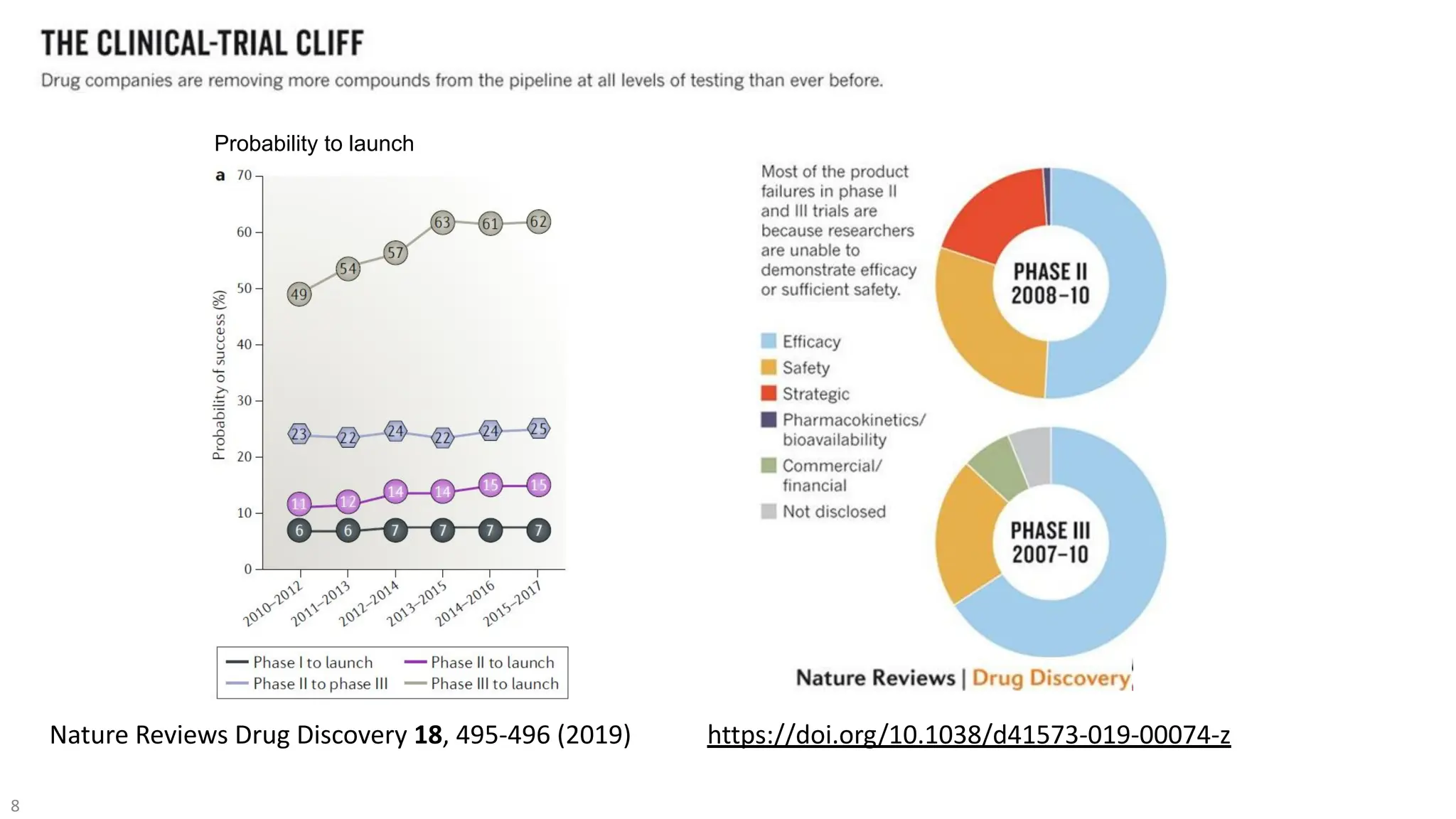
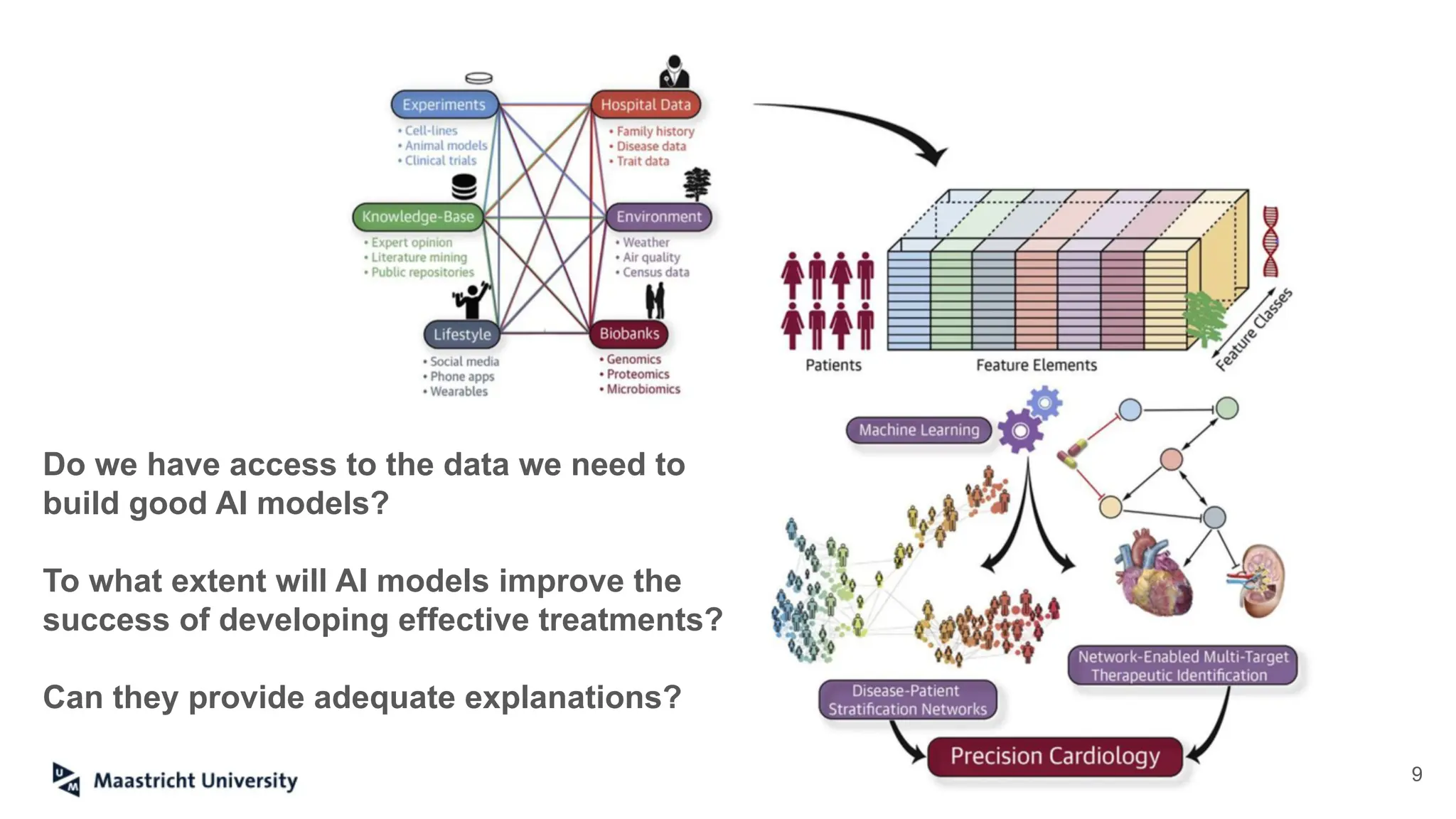



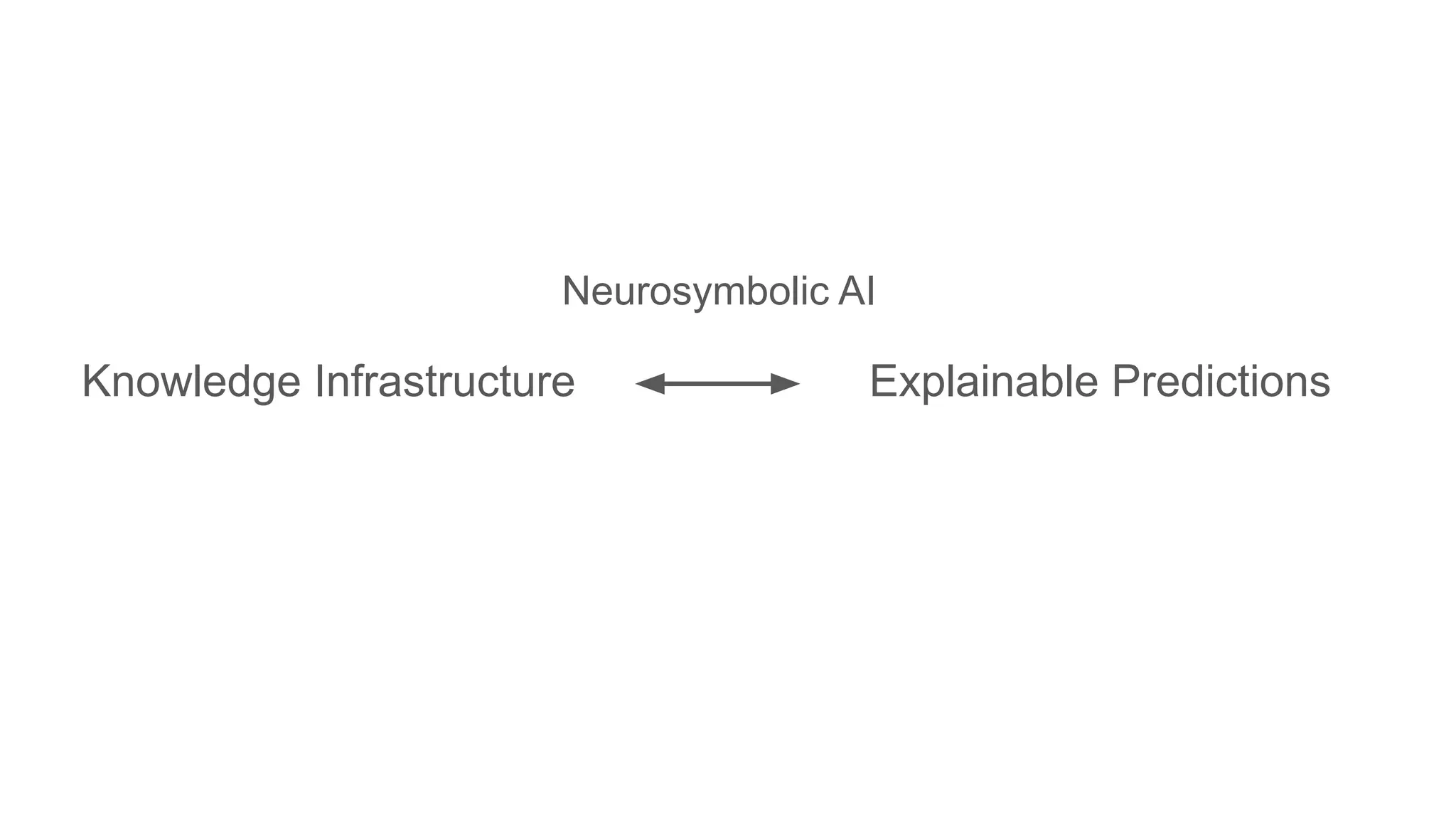

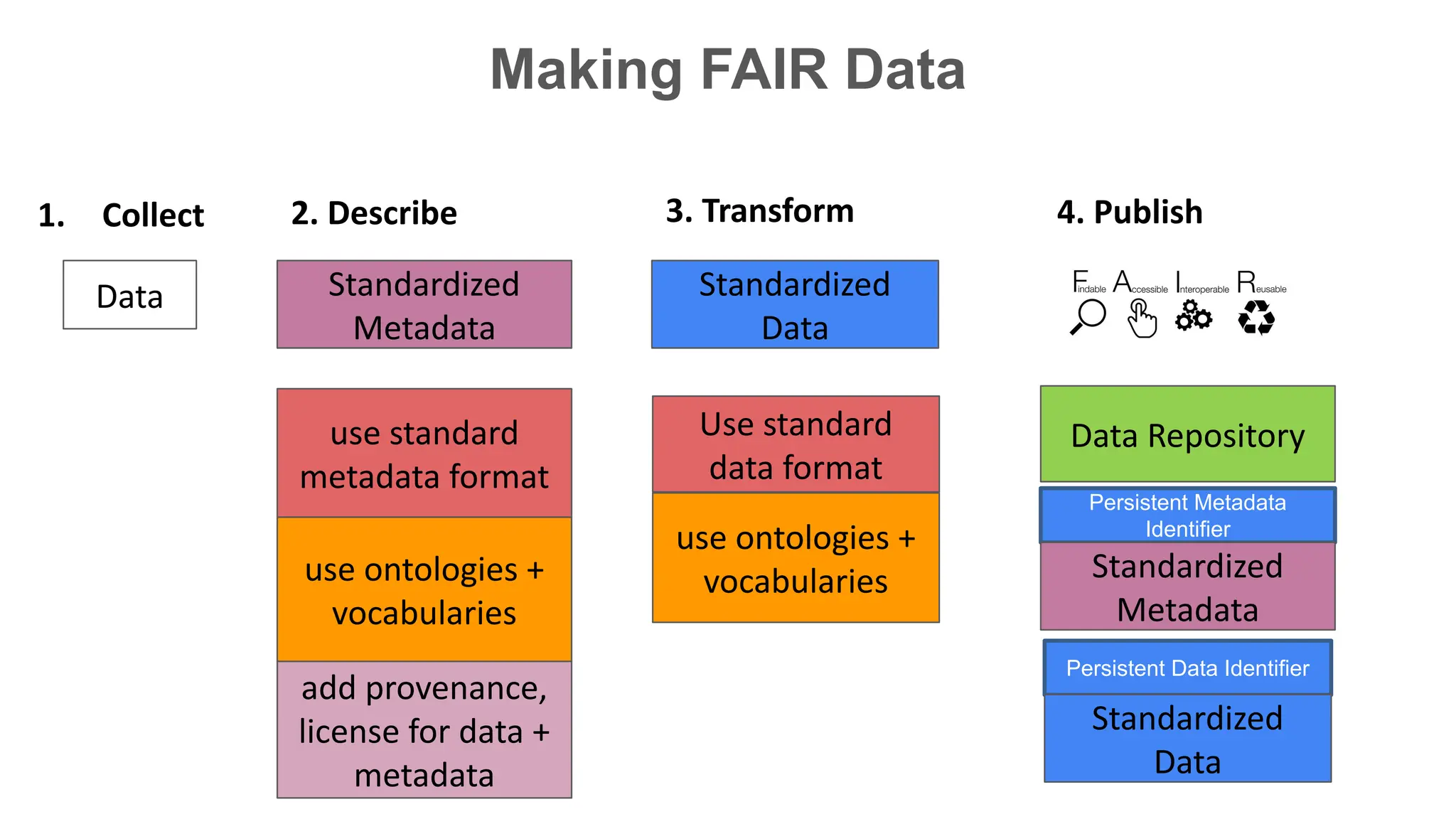

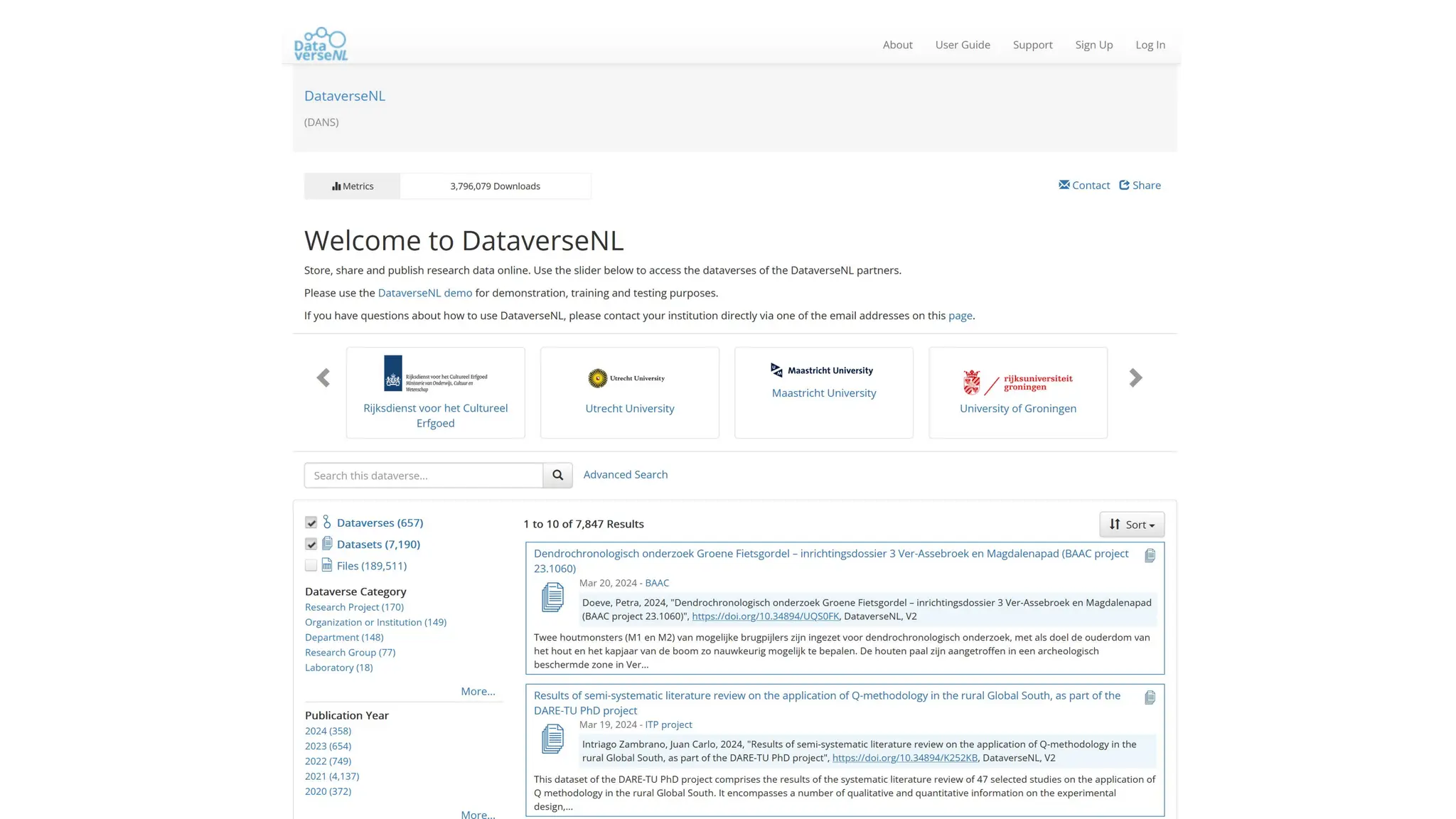
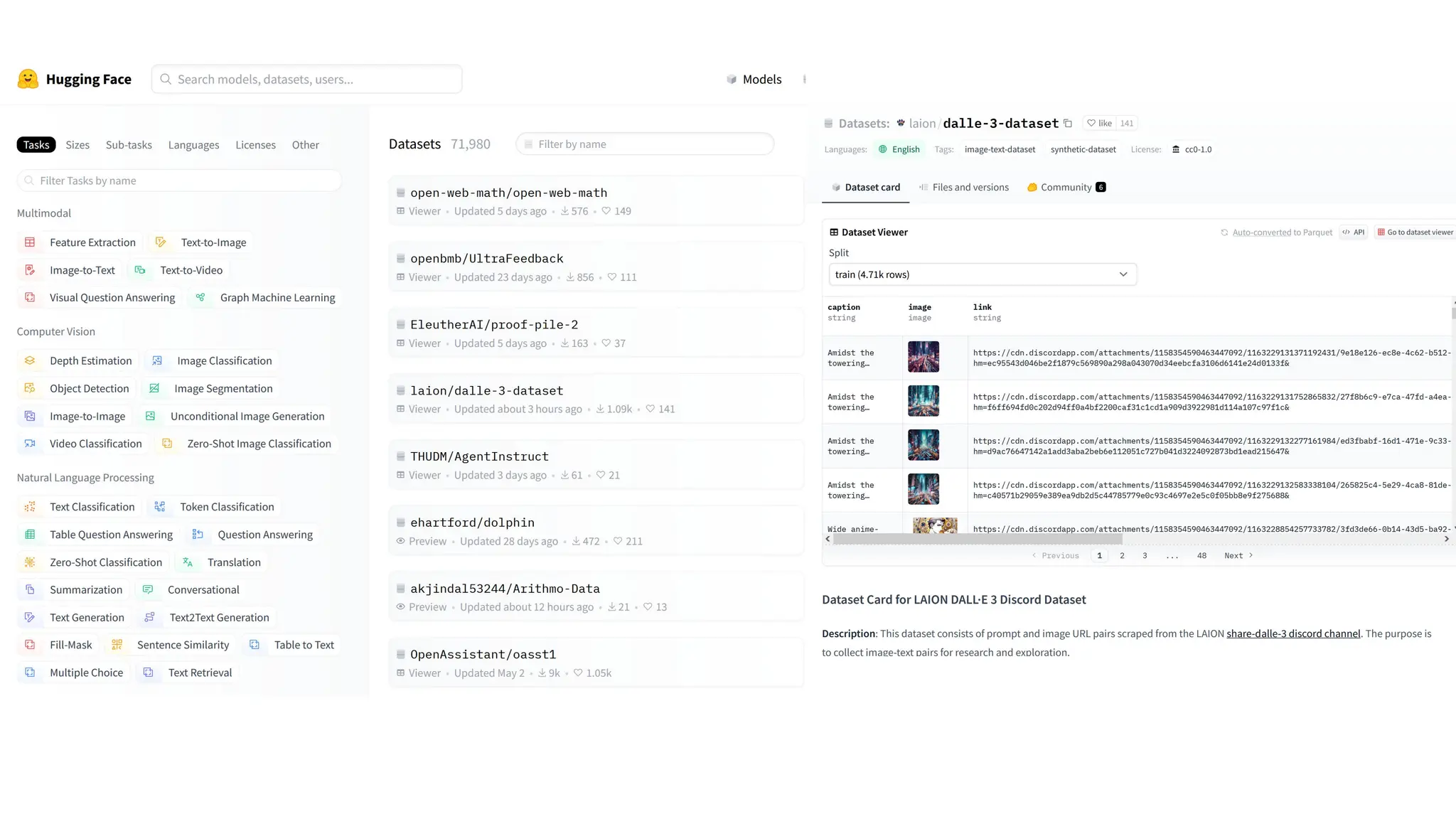
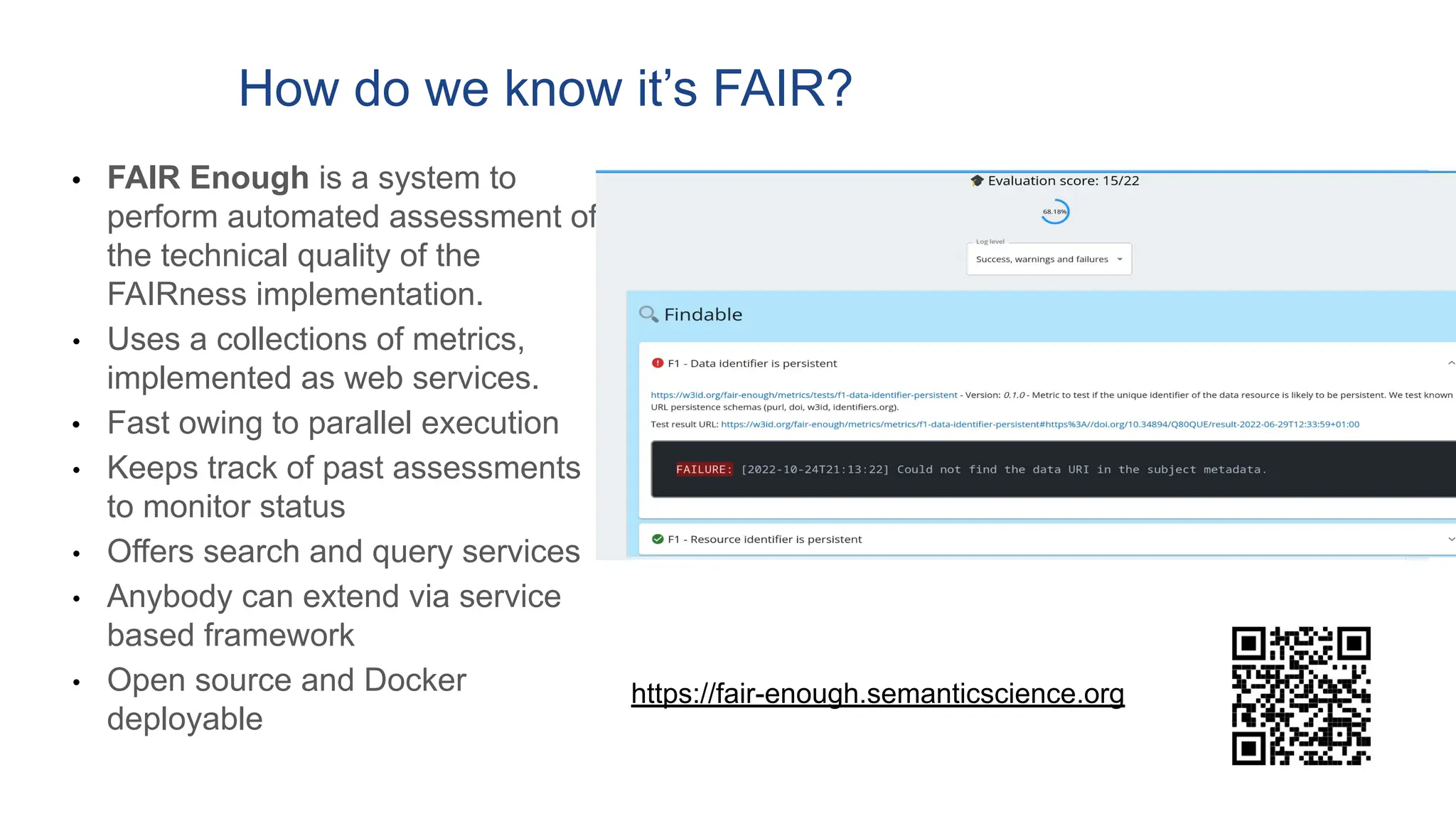

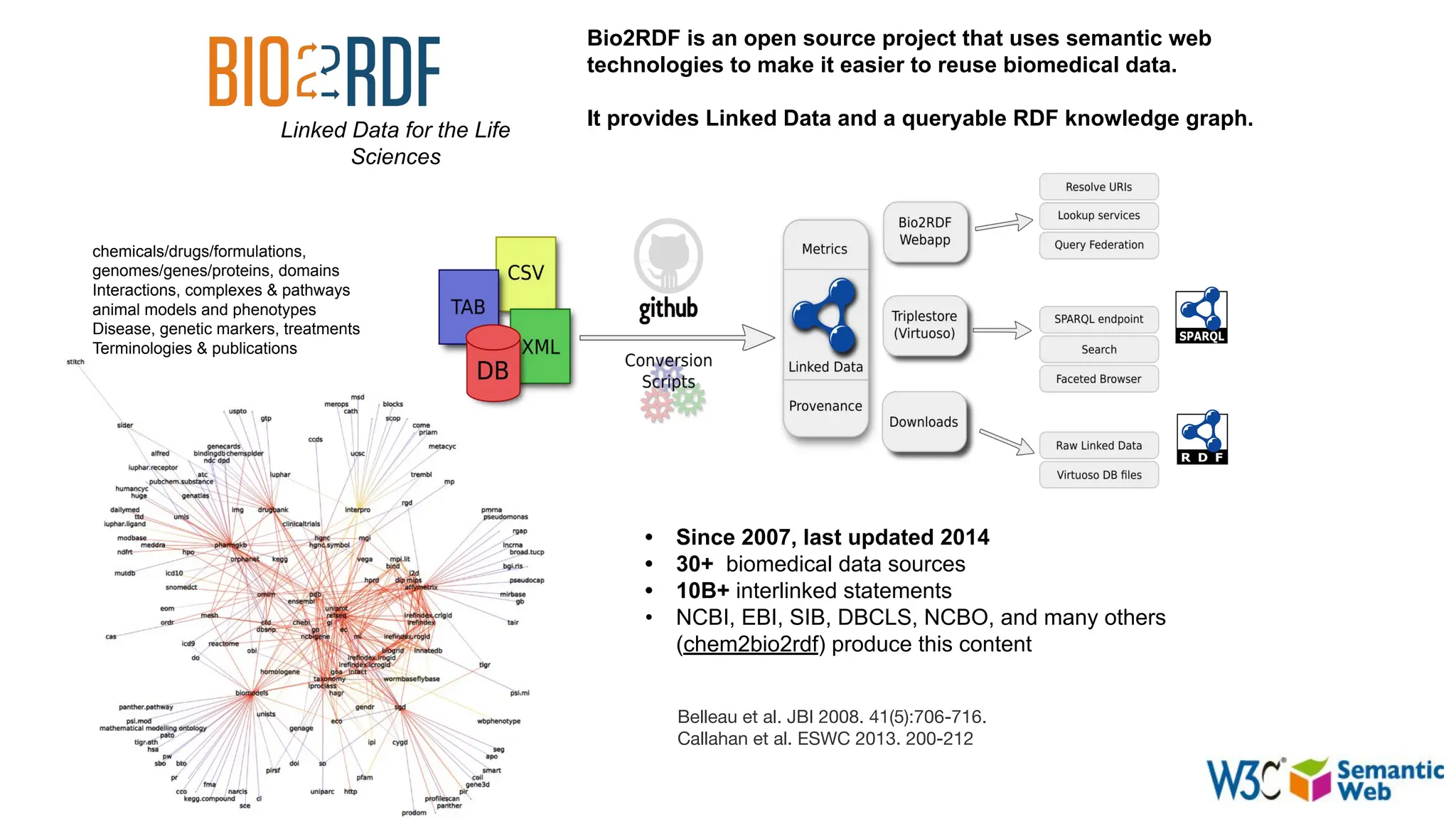
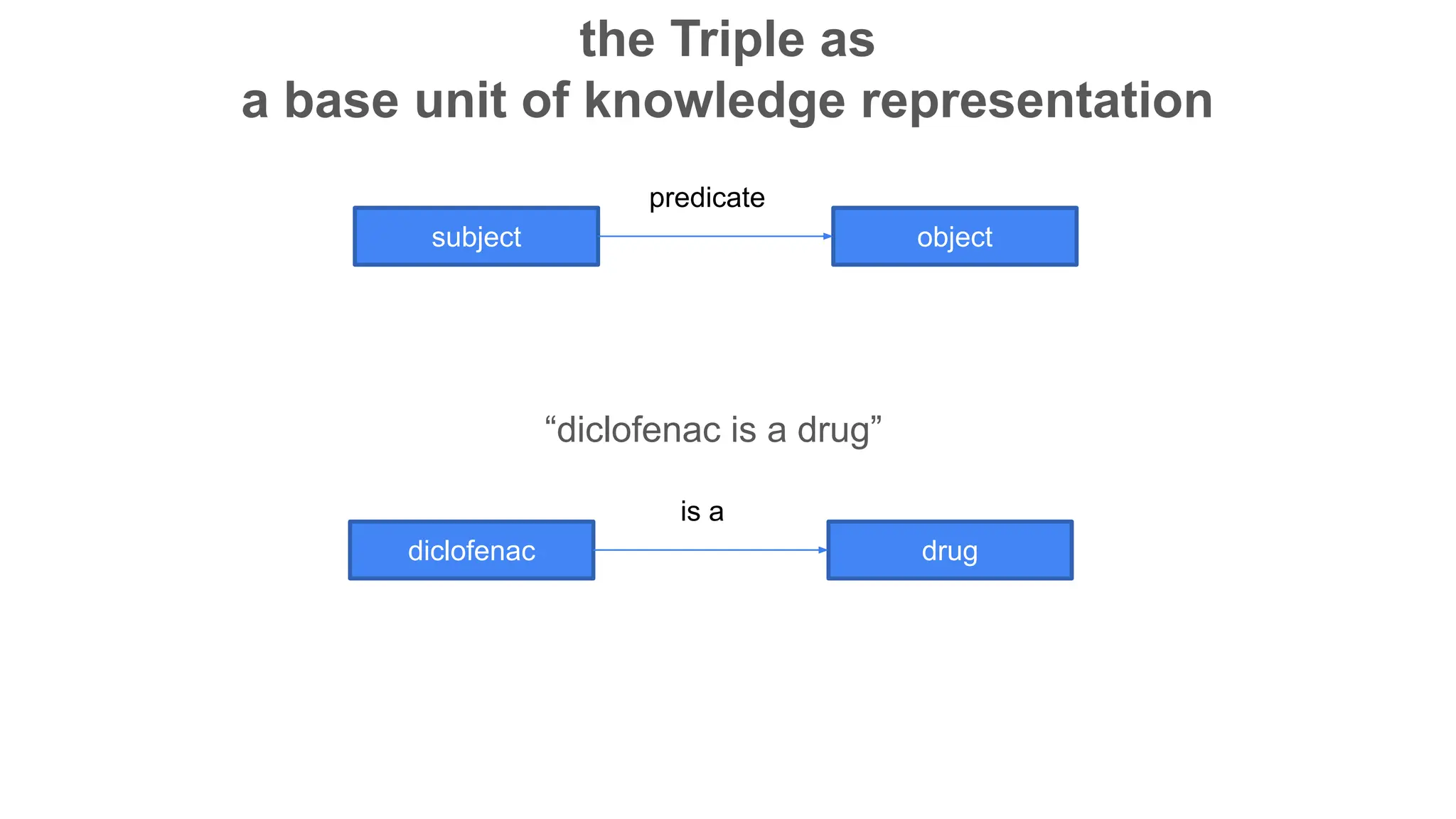
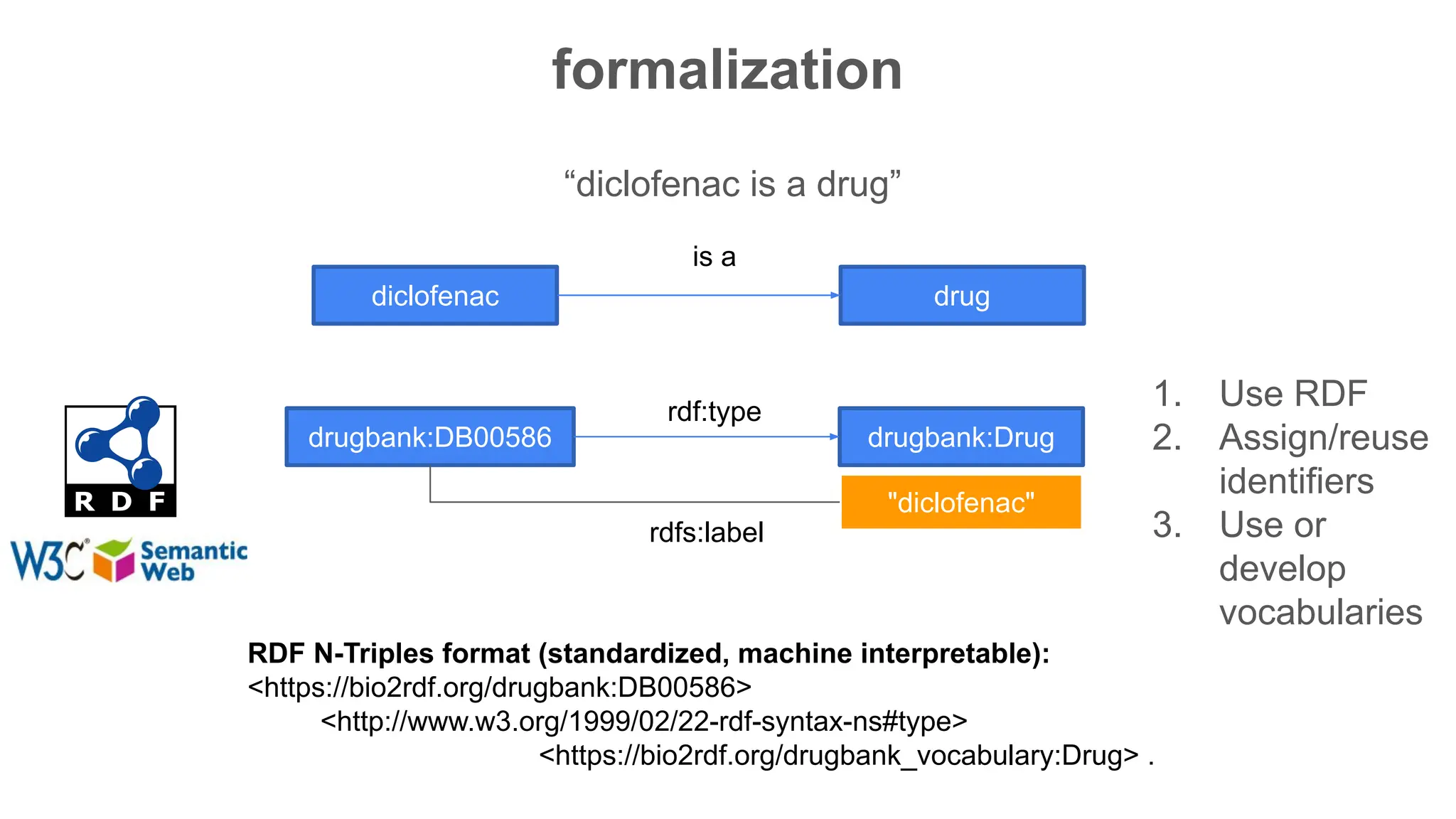
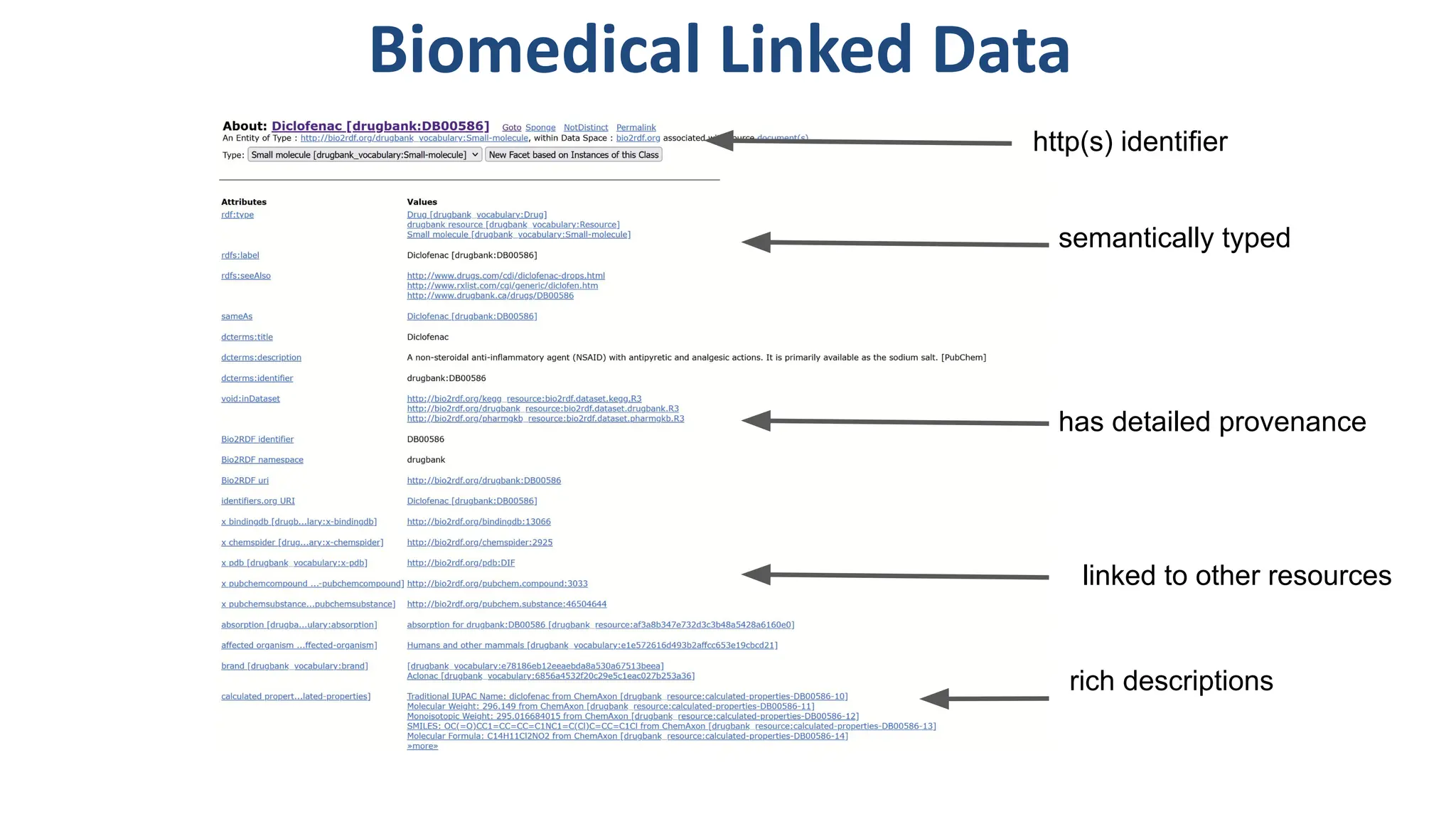
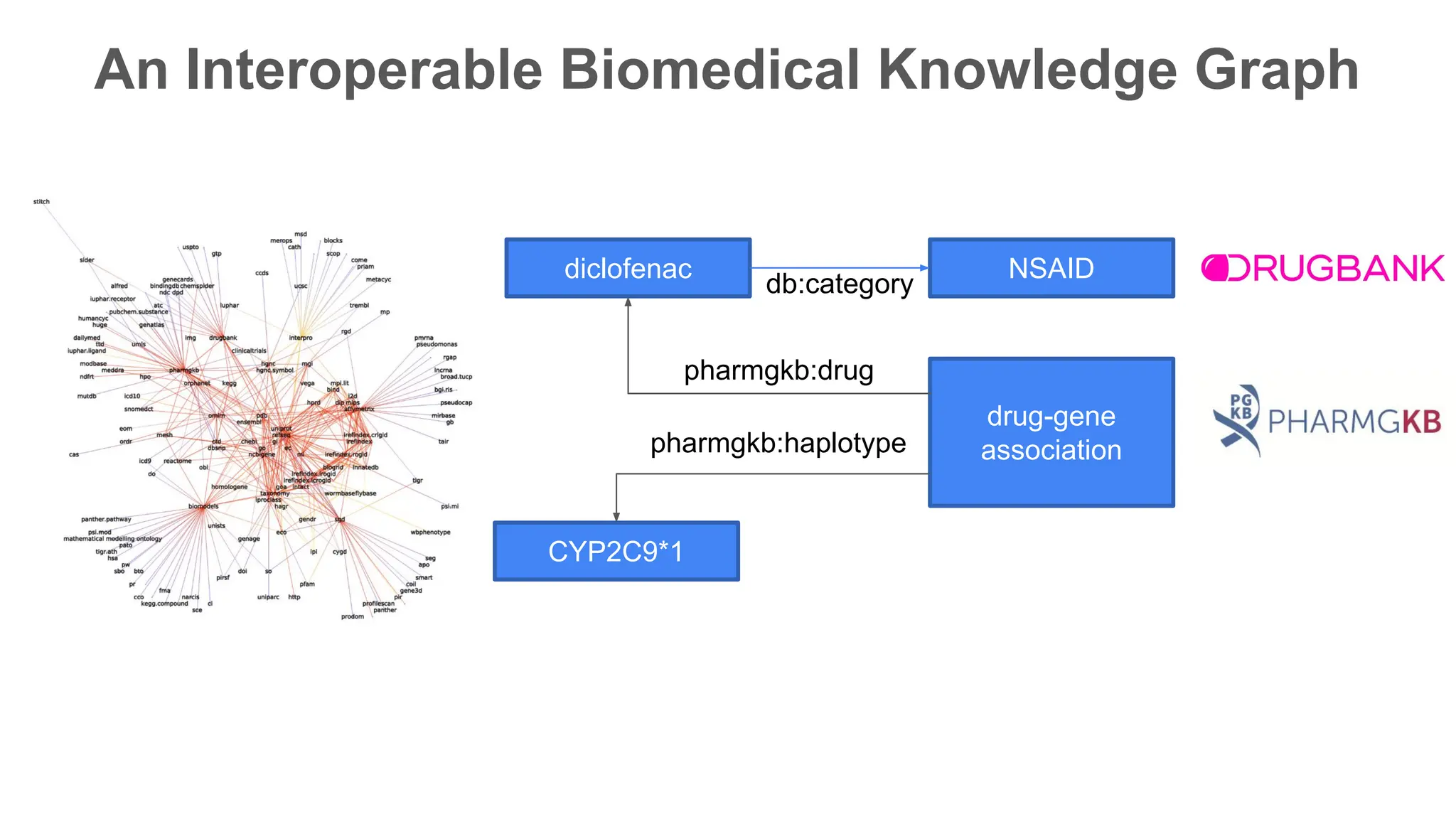
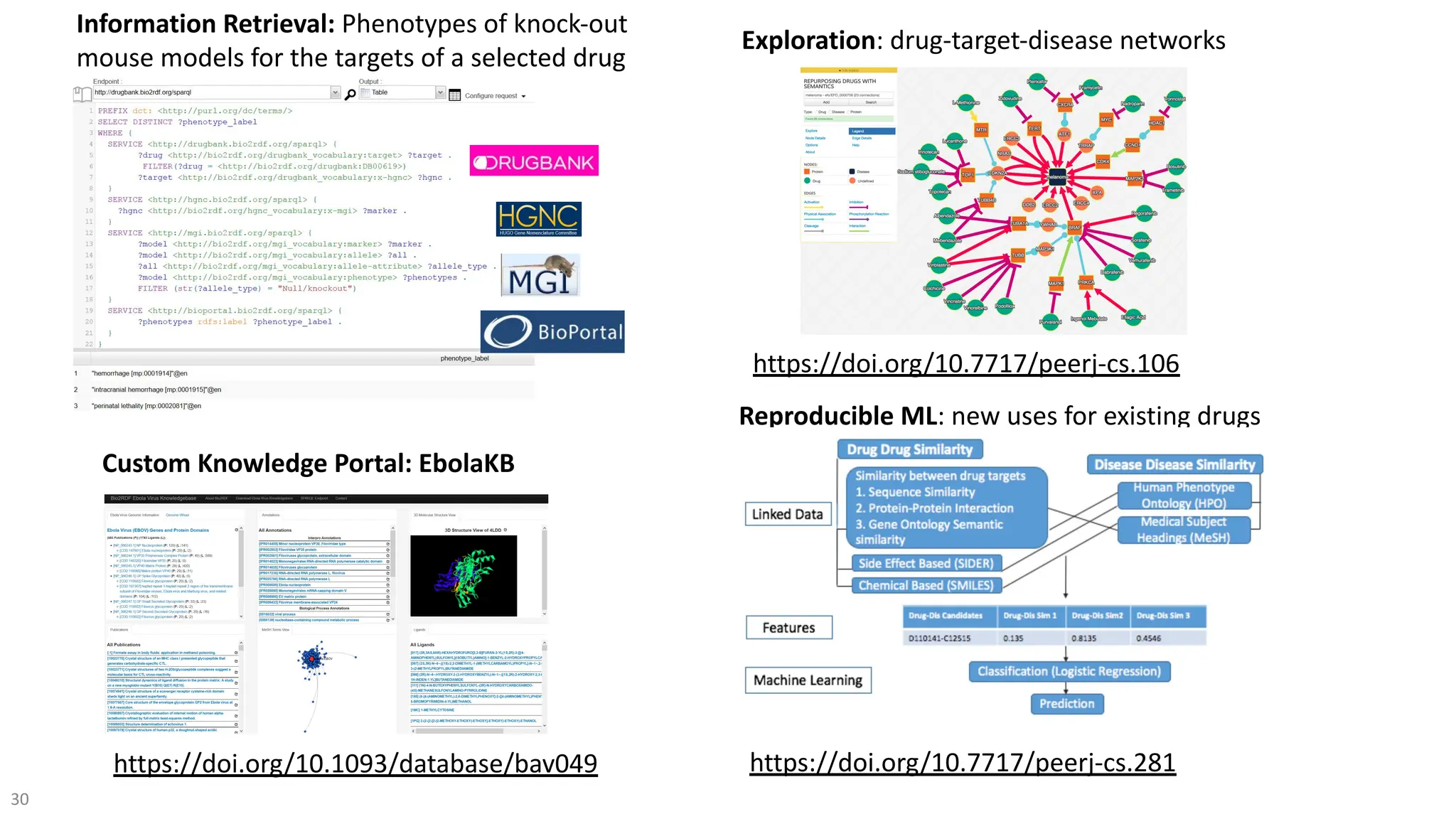
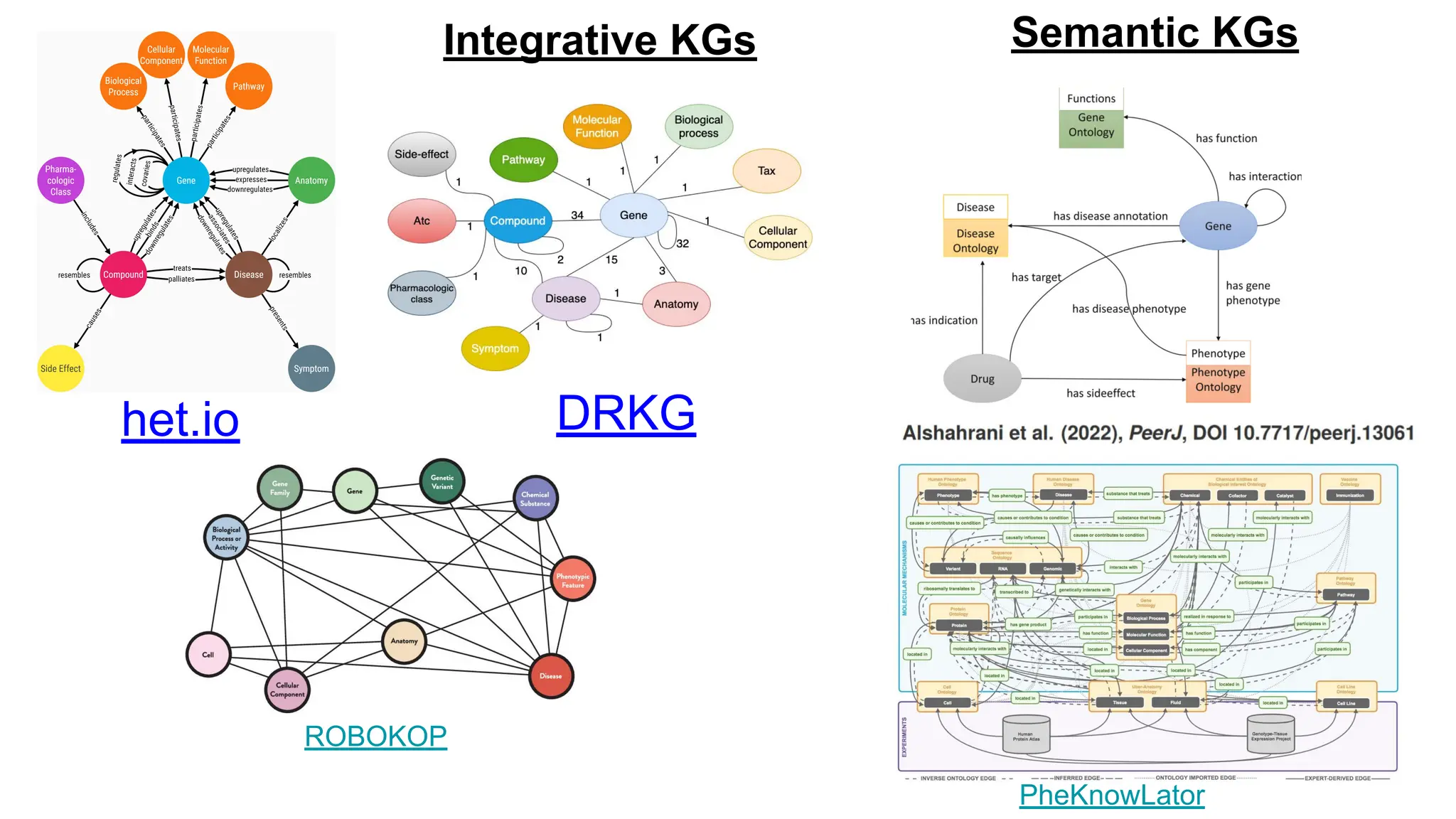
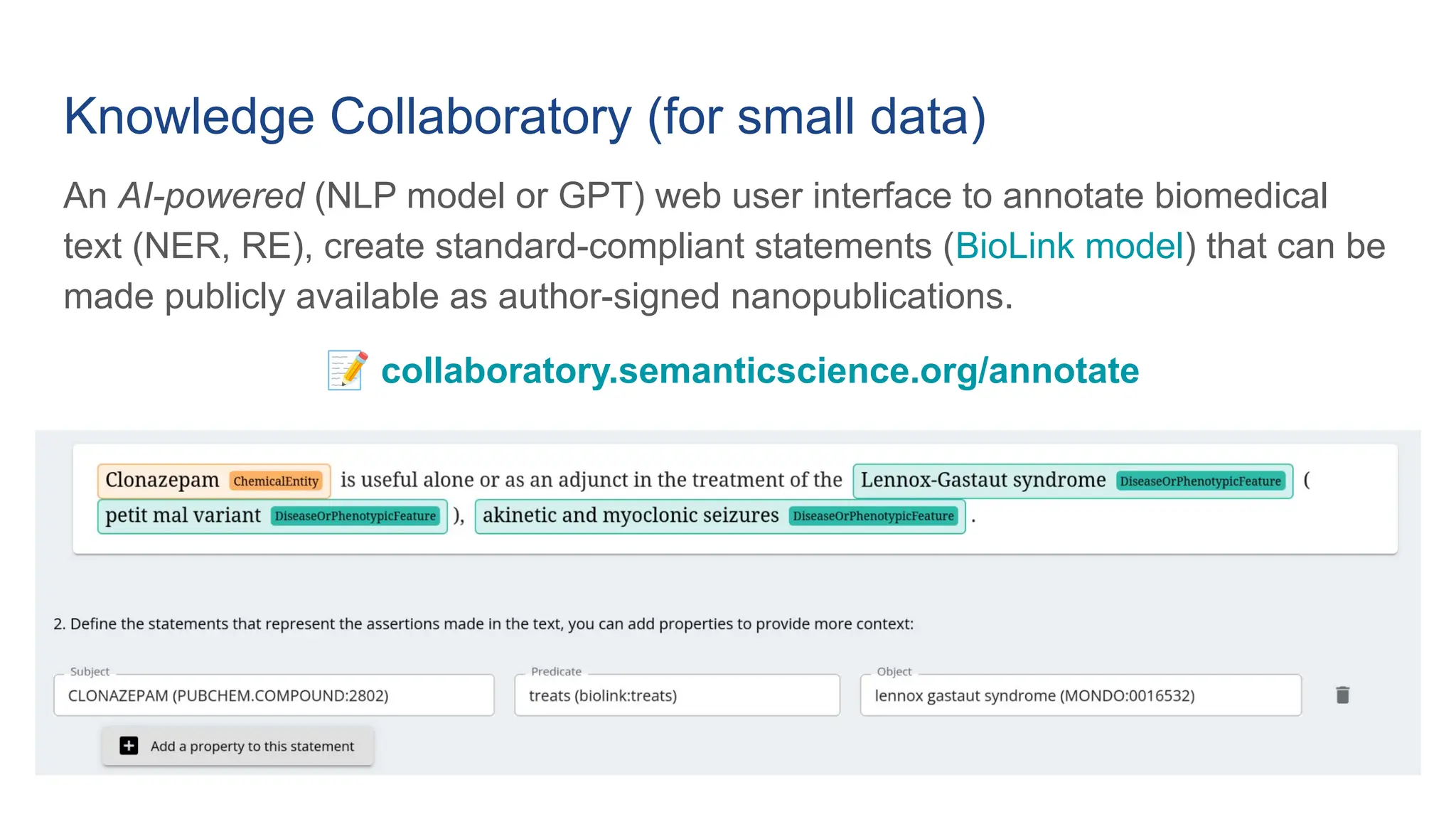
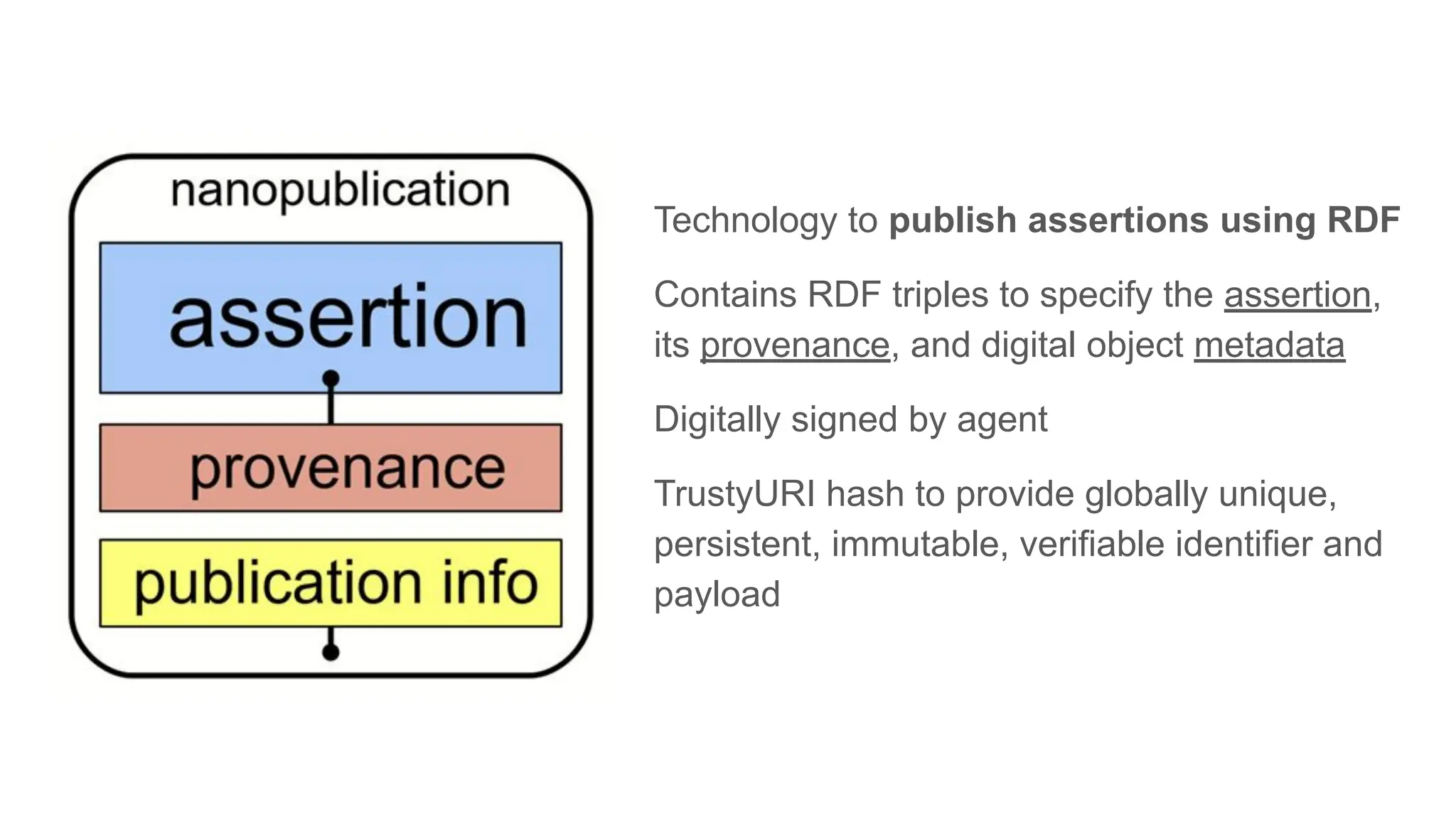
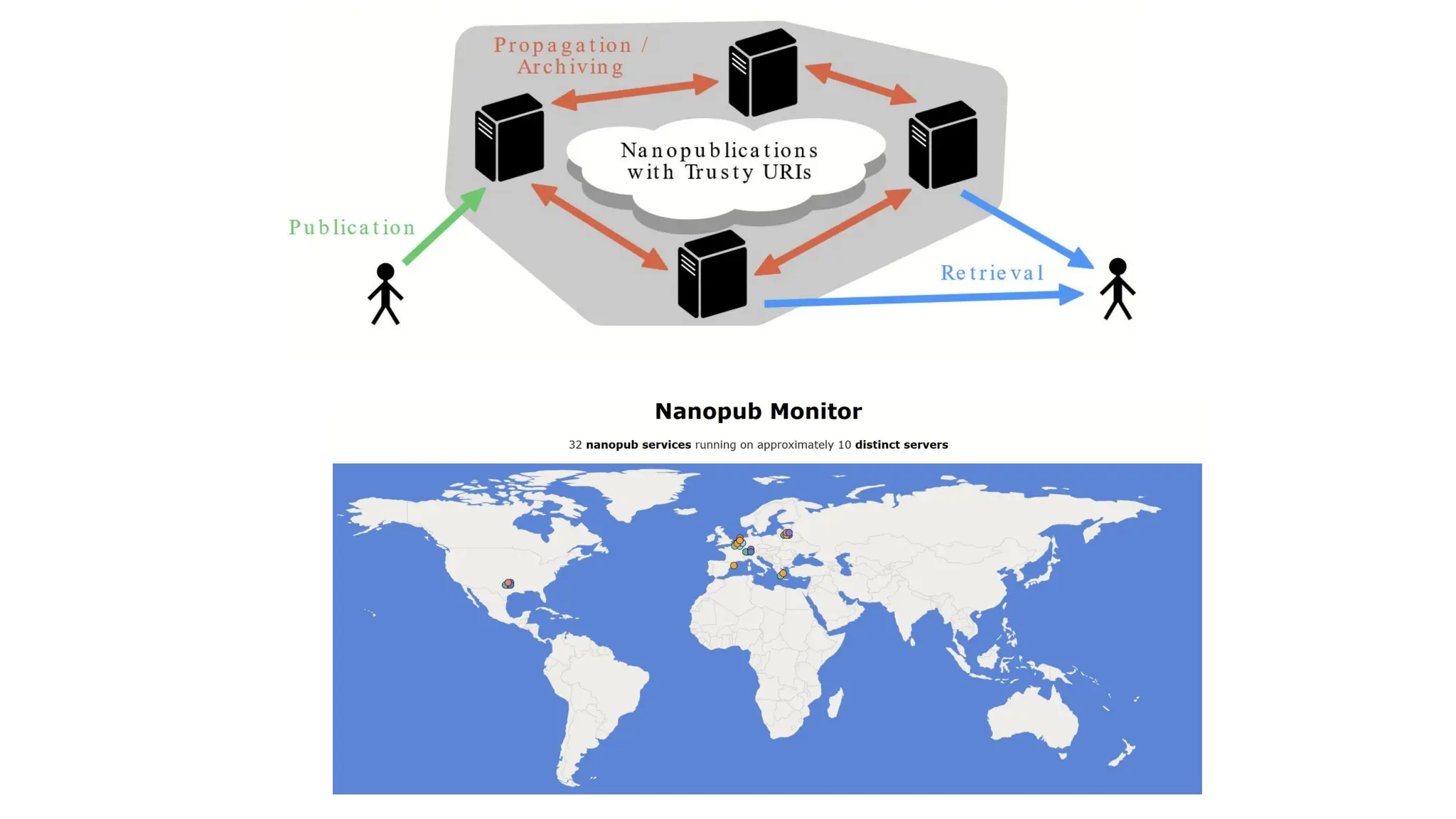





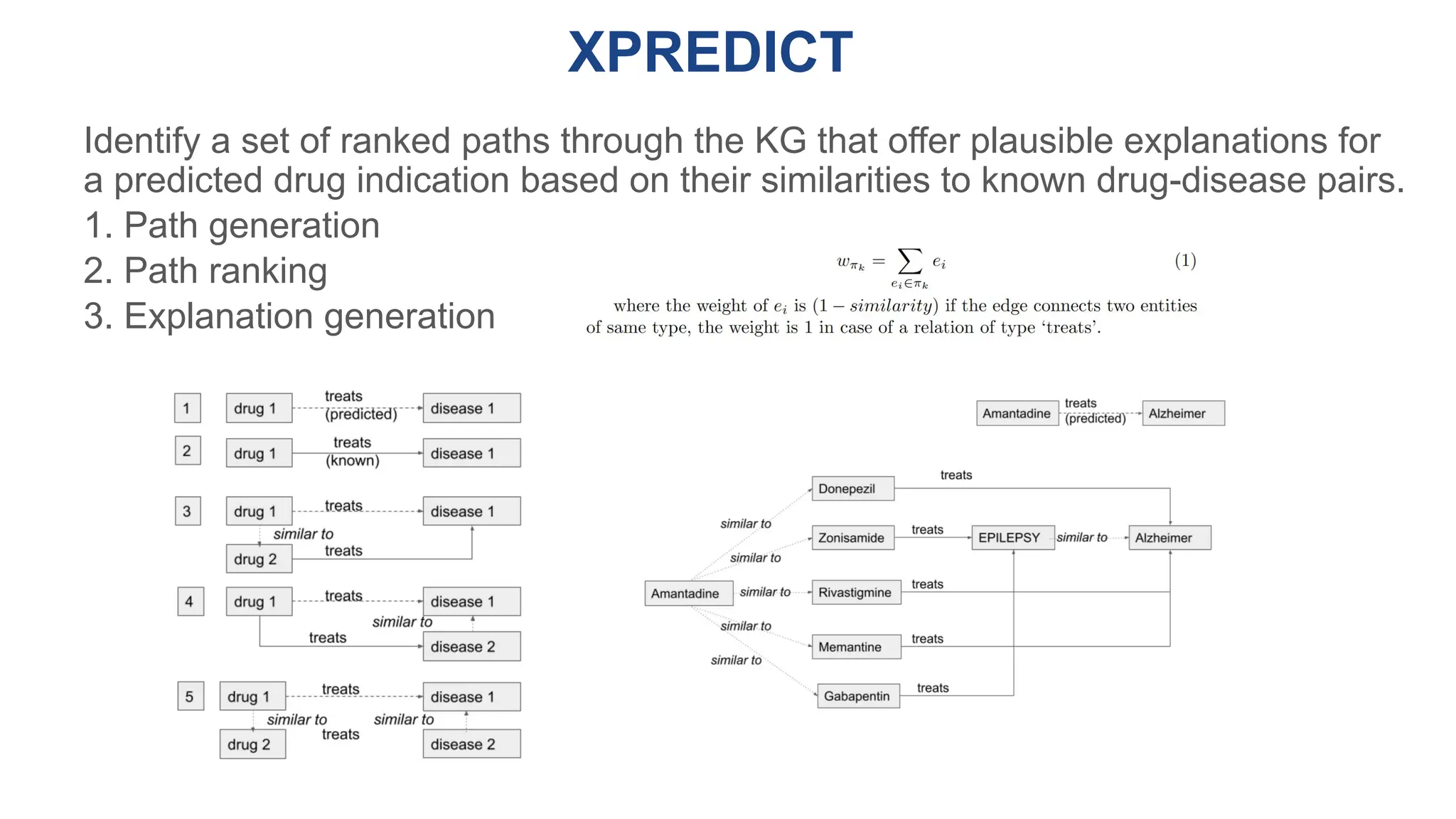
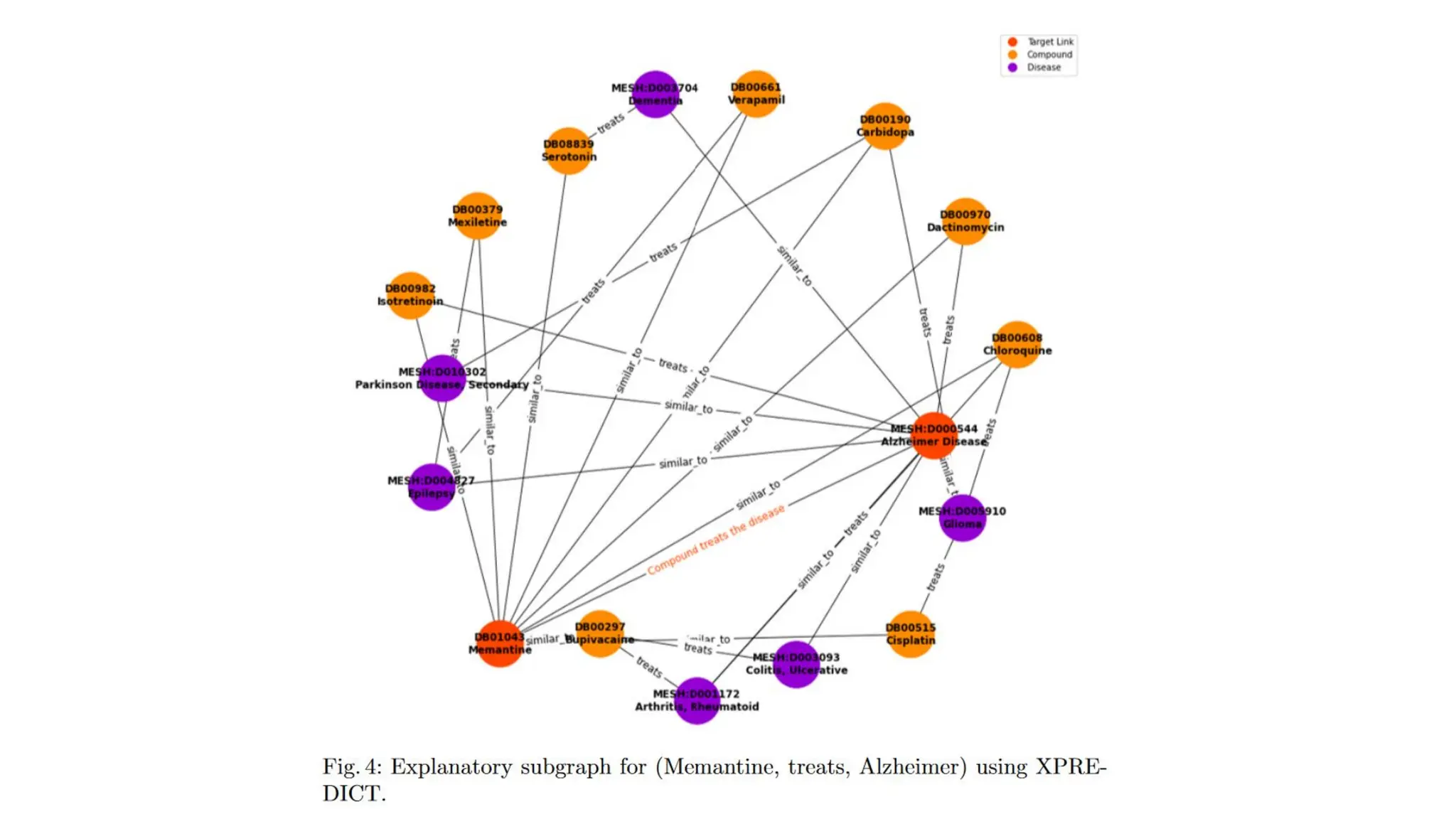

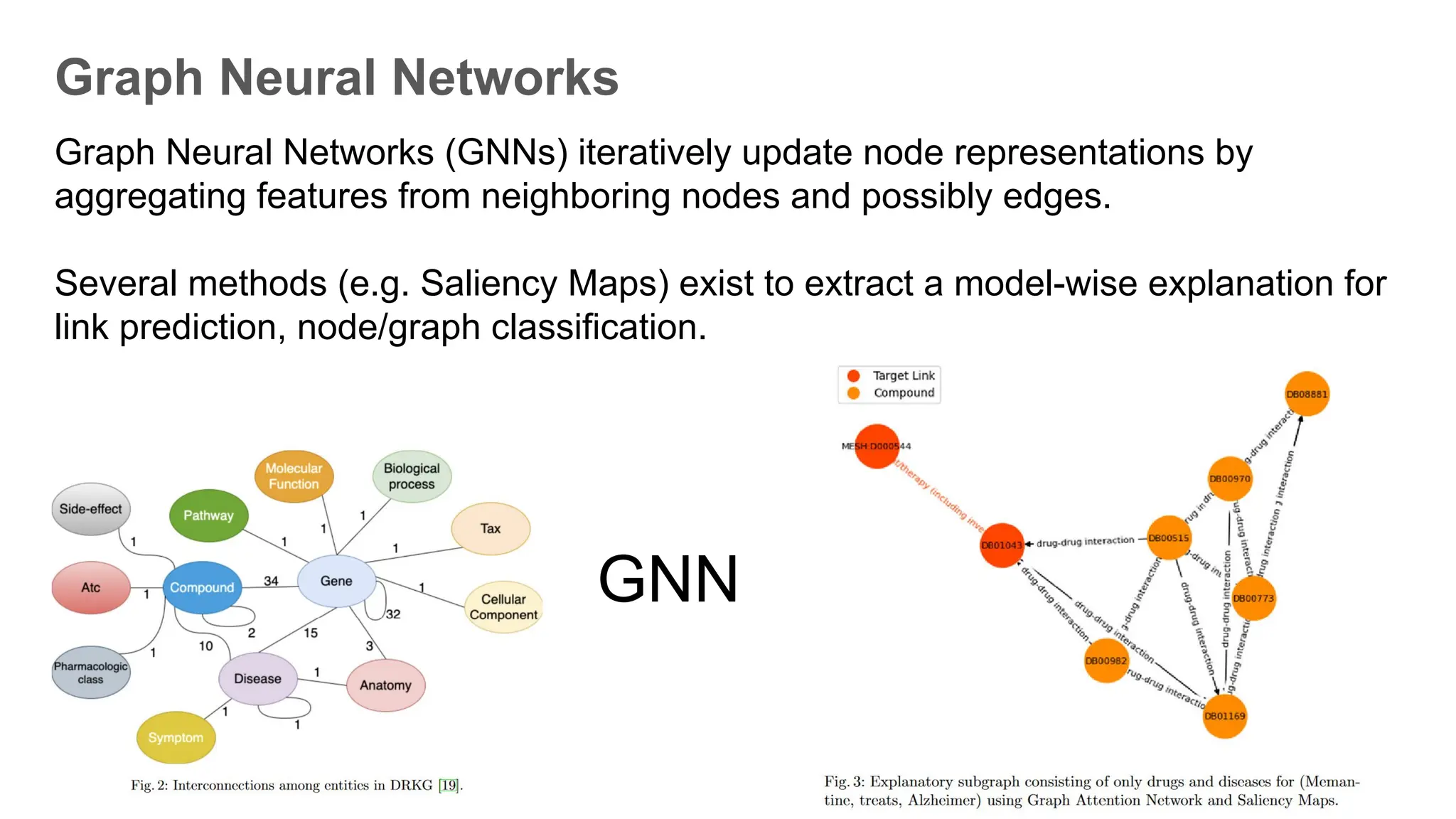



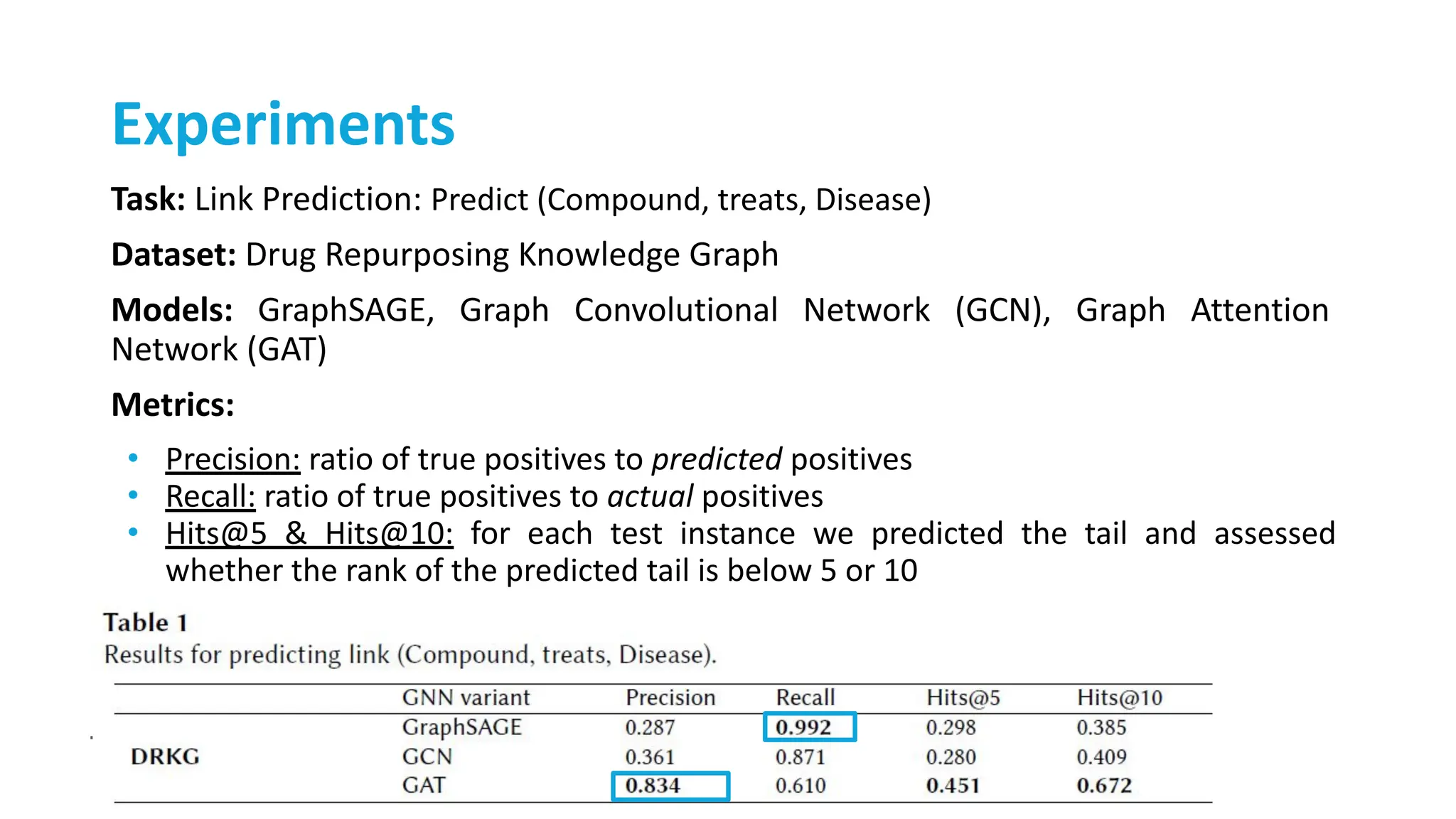
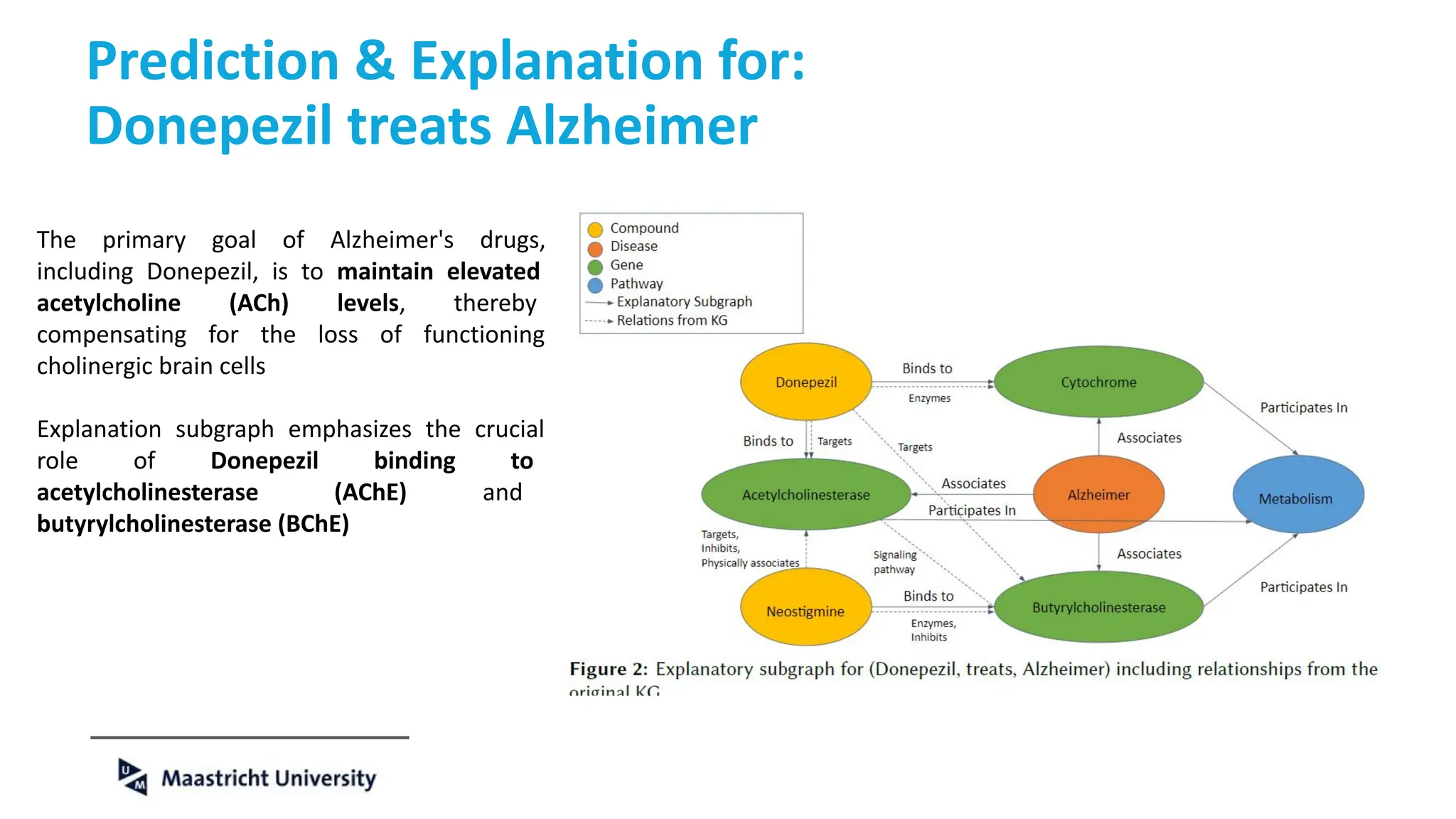



The document discusses the importance of fair and AI-ready knowledge graphs for explainable predictions in biomedicine, emphasizing the need for better data utilization and collaboration between human and machine. It addresses challenges in data accessibility, quality, and model limitations while highlighting the potential of neurosymbolic AI for creating robust, reproducible, and interpretable predictions. The document concludes that while semantic biomedical knowledge graphs have advanced, further work is needed to improve the explainability of AI-driven predictions.



































































