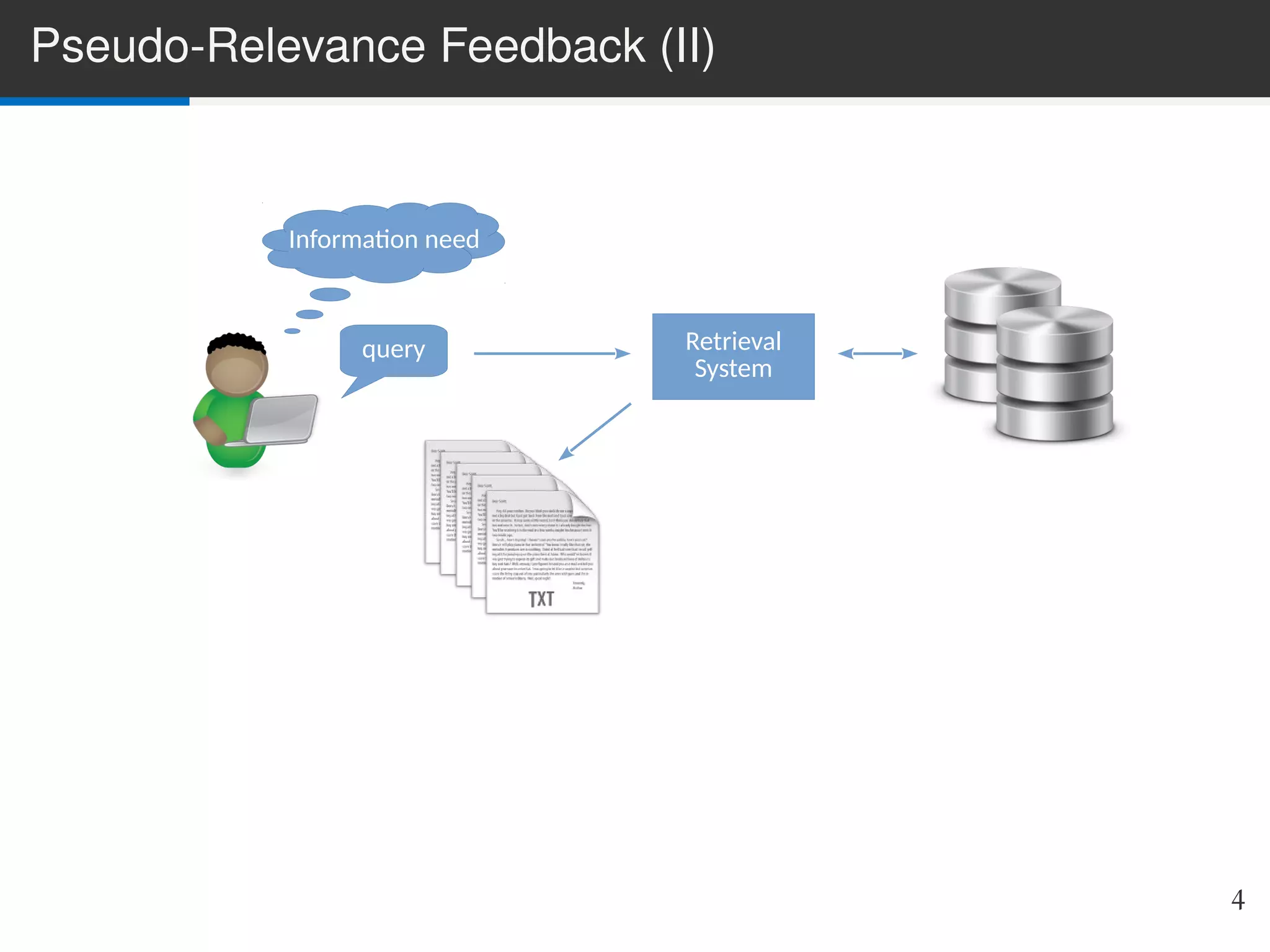
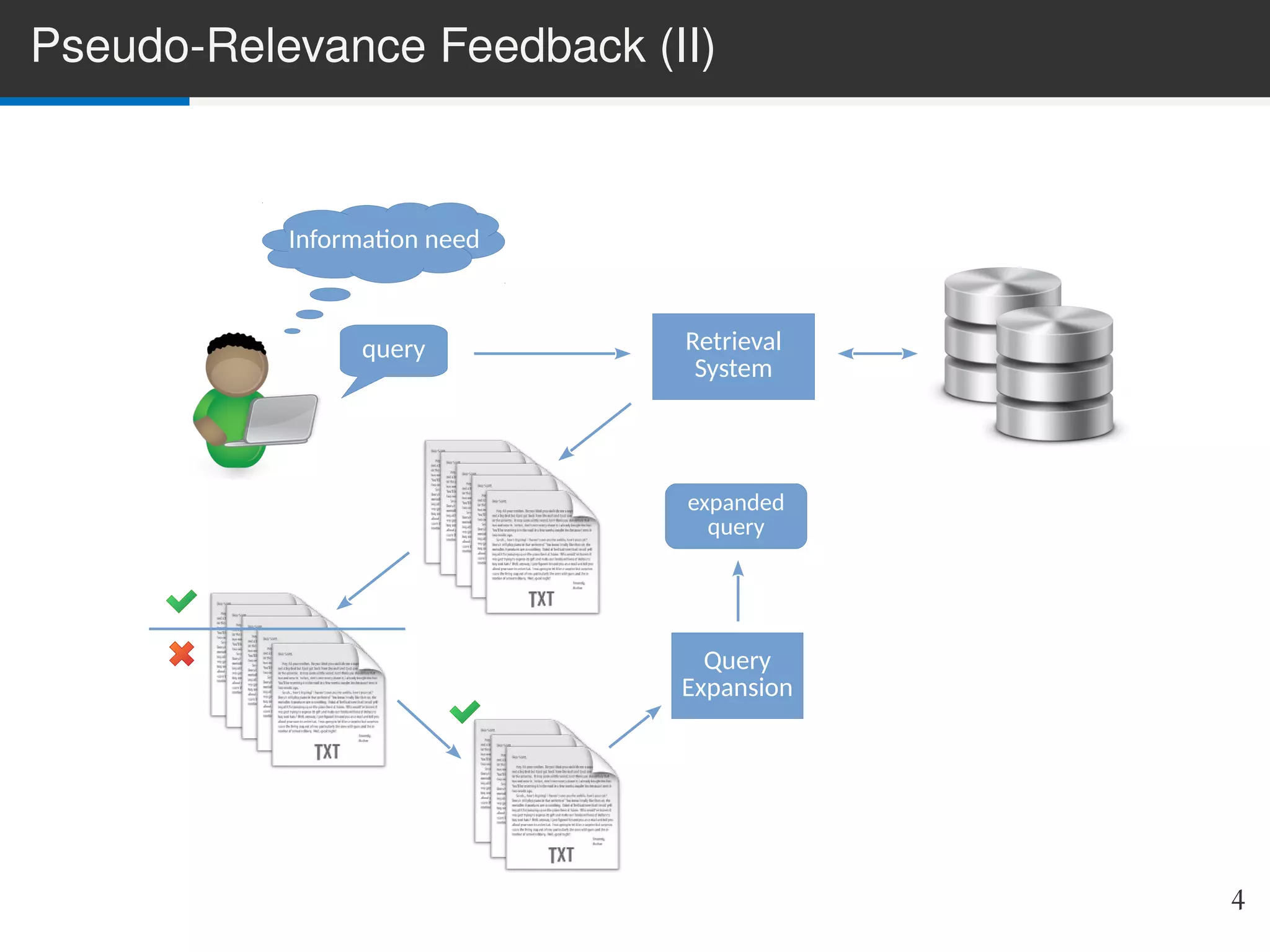
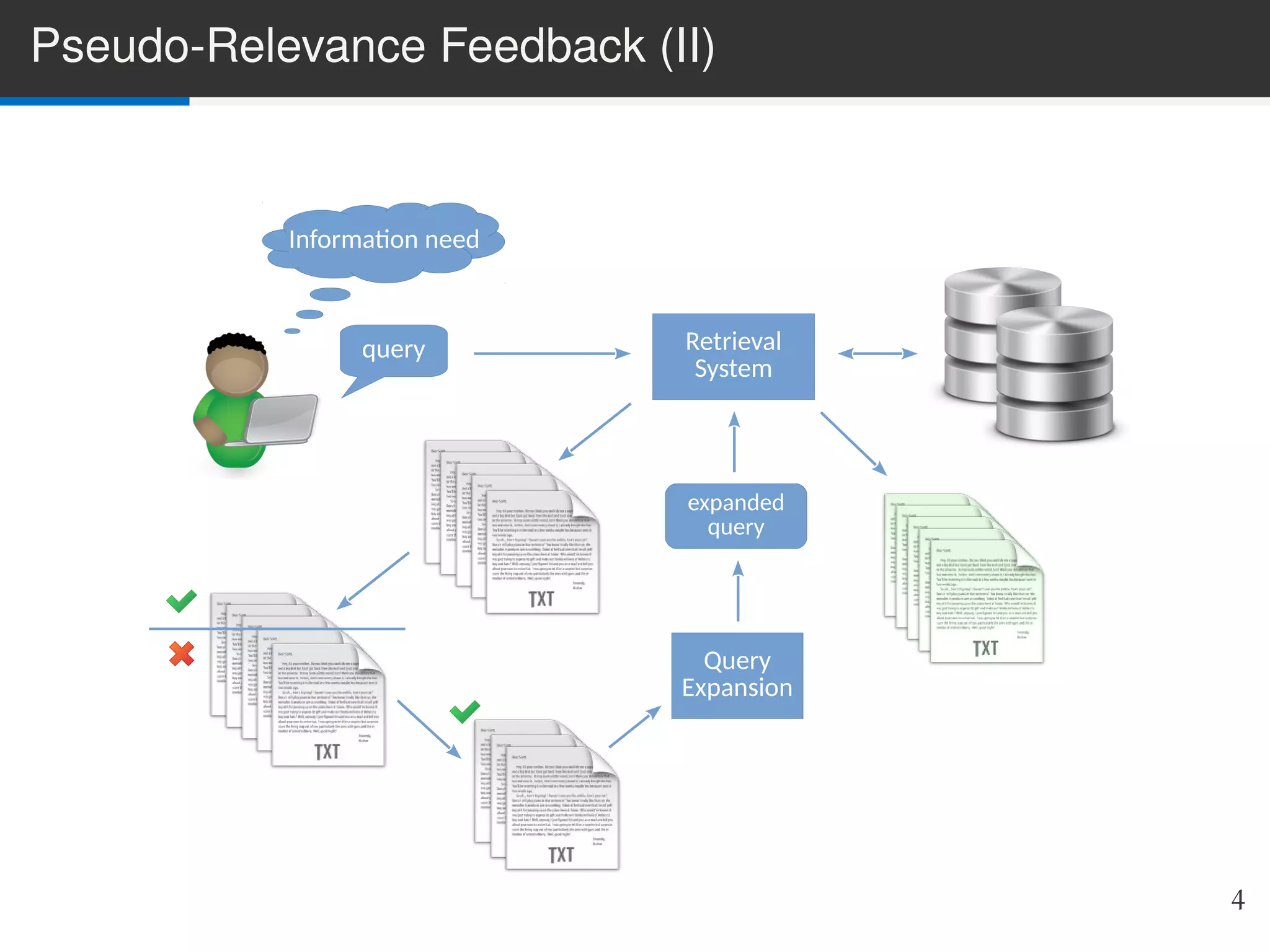
The document presents LIME, a linear method for pseudo-relevance feedback (PRF) that enhances query performance by expanding original queries based on retrieved documents assumed to be relevant. The approach models the PRF problem as a matrix decomposition issue, learning inter-term similarities while being adaptable to various retrieval models. Experimental results demonstrate LIME's superior performance compared to traditional methods, with potential for future enhancements and alternative feature schemes.






















![State-of-the-art Baselines
Retrieval model:
◦ LM: Language Models (µ 1000) [Ponte & Croft, SIGIR ’98]
Based on language modelling:
◦ RM3: Relevance-Based Language Models [Lavrenko &
Croft, SIGIR ’01]
◦ MEDMM: Maximum-Entropy Divergence Minimisation
Models [Lv & Zhai, CIKM ’09]
Based on matrix factorization:
◦ RFMF: Relevance Feedback Matrix Factorisation [Zamani et
al., CIKM ’16]
15](https://image.slidesharecdn.com/limeslides-180411100357/75/LiMe-Linear-Methods-for-Pseudo-Relevance-Feedback-SAC-18-Slides-26-2048.jpg)








![Future work
Alternative feature schemes based on:
retrieval features
query logs
Explore connection with Translation Models which also rely on
inter-term similarities:
learnt from training data [Berger & Lafferty, SIGIR ’99]
based on mutual information [Karimzadehgan & Zhai,
SIGIR ’10]
26](https://image.slidesharecdn.com/limeslides-180411100357/75/LiMe-Linear-Methods-for-Pseudo-Relevance-Feedback-SAC-18-Slides-37-2048.jpg)






















































![Language Models for Collaborative Filtering Neighbourhoods [ECIR '16 Slides]](https://cdn.slidesharecdn.com/ss_thumbnails/slides-2016-lmforneigh-160411083912-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DSC Europe 25] Max Talanov - Non digital NNs.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/wif8tr3gtua74qvtopke-non-digital-nns-251205090438-26b0eea6-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Boris Perkovic - Lost in performance.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/uq5hrp7vsuahqkxzifux-1-251204082258-fd2ee09d-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DSC Europe 25] Jim Sterne - Adopting Generative AI Capabilities Into the Ent...](https://cdn.slidesharecdn.com/ss_thumbnails/sxhpofuorcagxsaulkmt-3-251204082258-7e66bc48-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dragan Vucic - Building the Learning Organization - How AI Tr...](https://cdn.slidesharecdn.com/ss_thumbnails/8brigo2sbu6qur6gxrra-7-251205085715-6ae07d24-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Vid Stimac - Policy Parsimony: Between Oversimplifying and Ov...](https://cdn.slidesharecdn.com/ss_thumbnails/eqlepagzqp2rhg3gbluh-dsc-stimac-251120-251205090438-059e7f54-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Goran Obradovic - The Rise of Sovereign AI: Building the Regi...](https://cdn.slidesharecdn.com/ss_thumbnails/7nw2xxixrxqdxvrb5wca-6-251205085714-ab09a2ac-thumbnail.jpg?width=640&height=640&fit=bounds)
