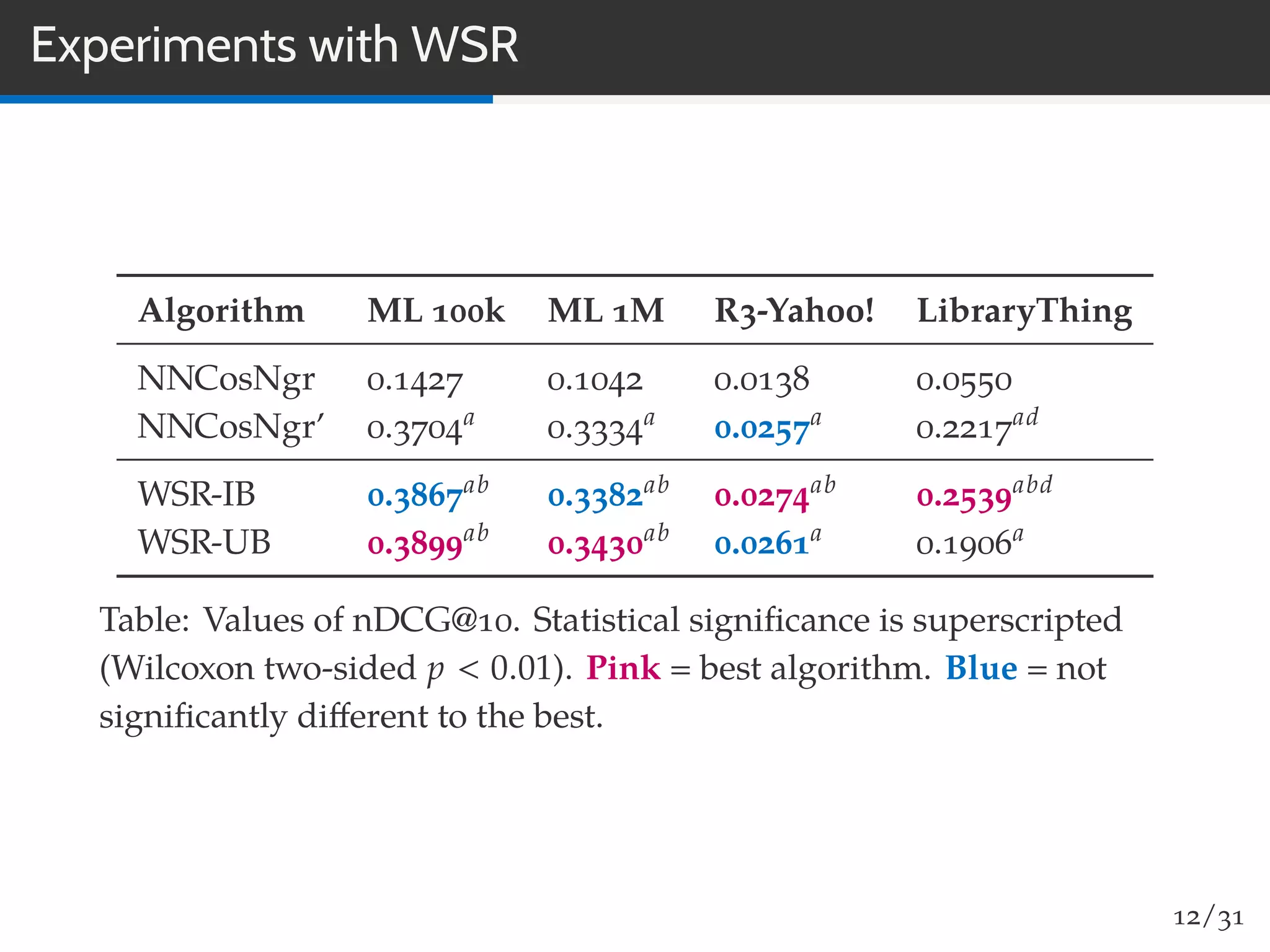
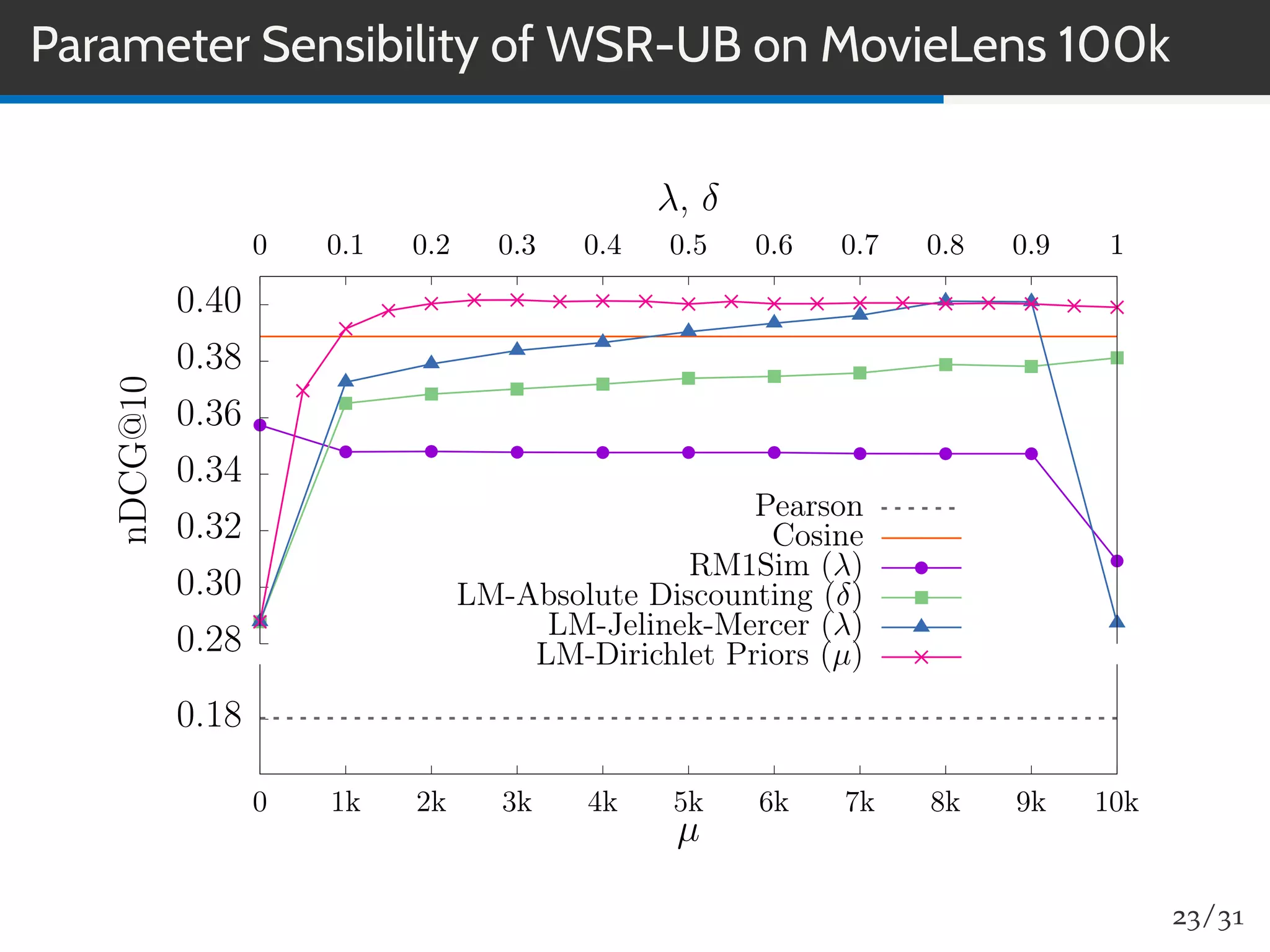
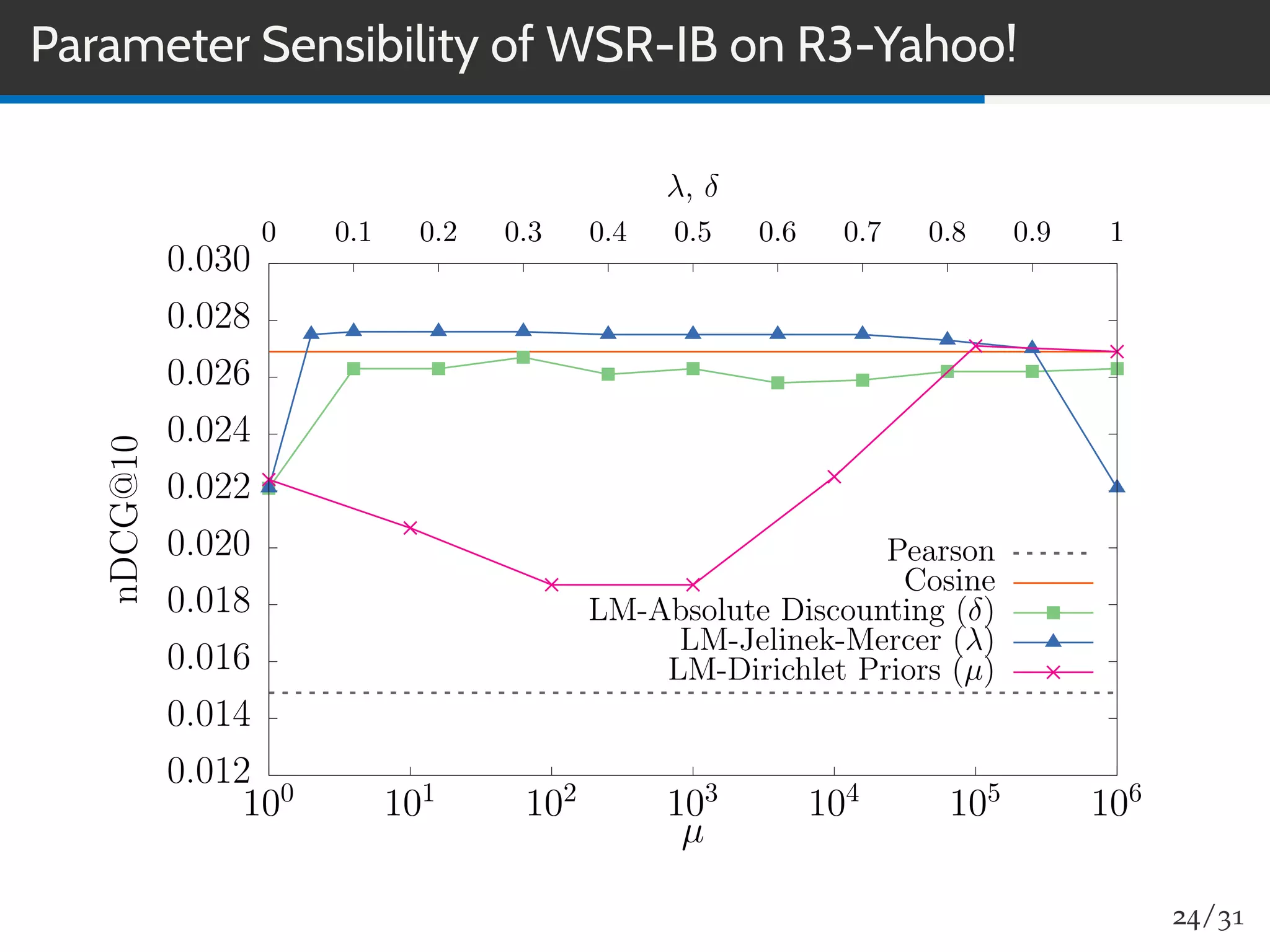
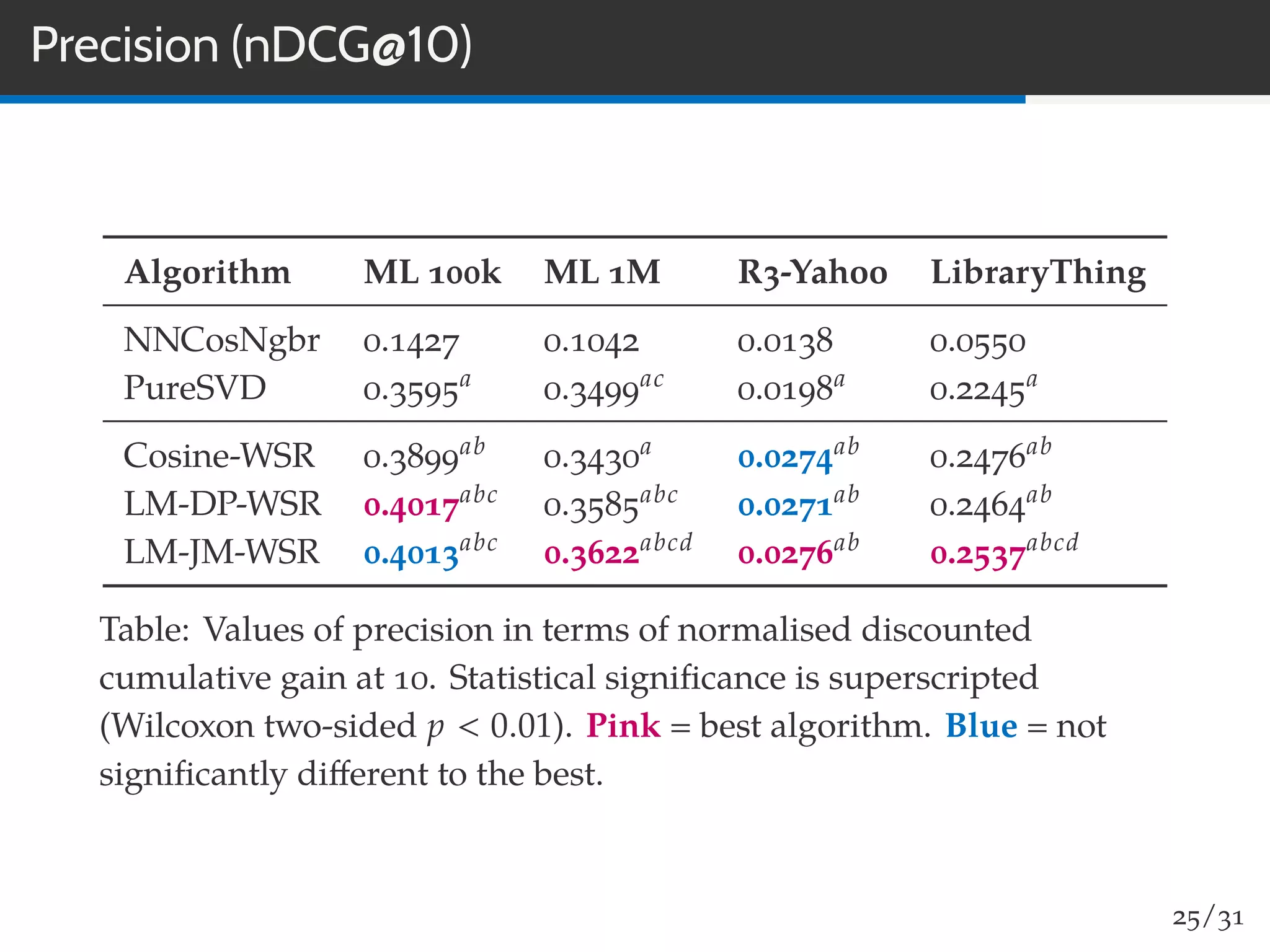
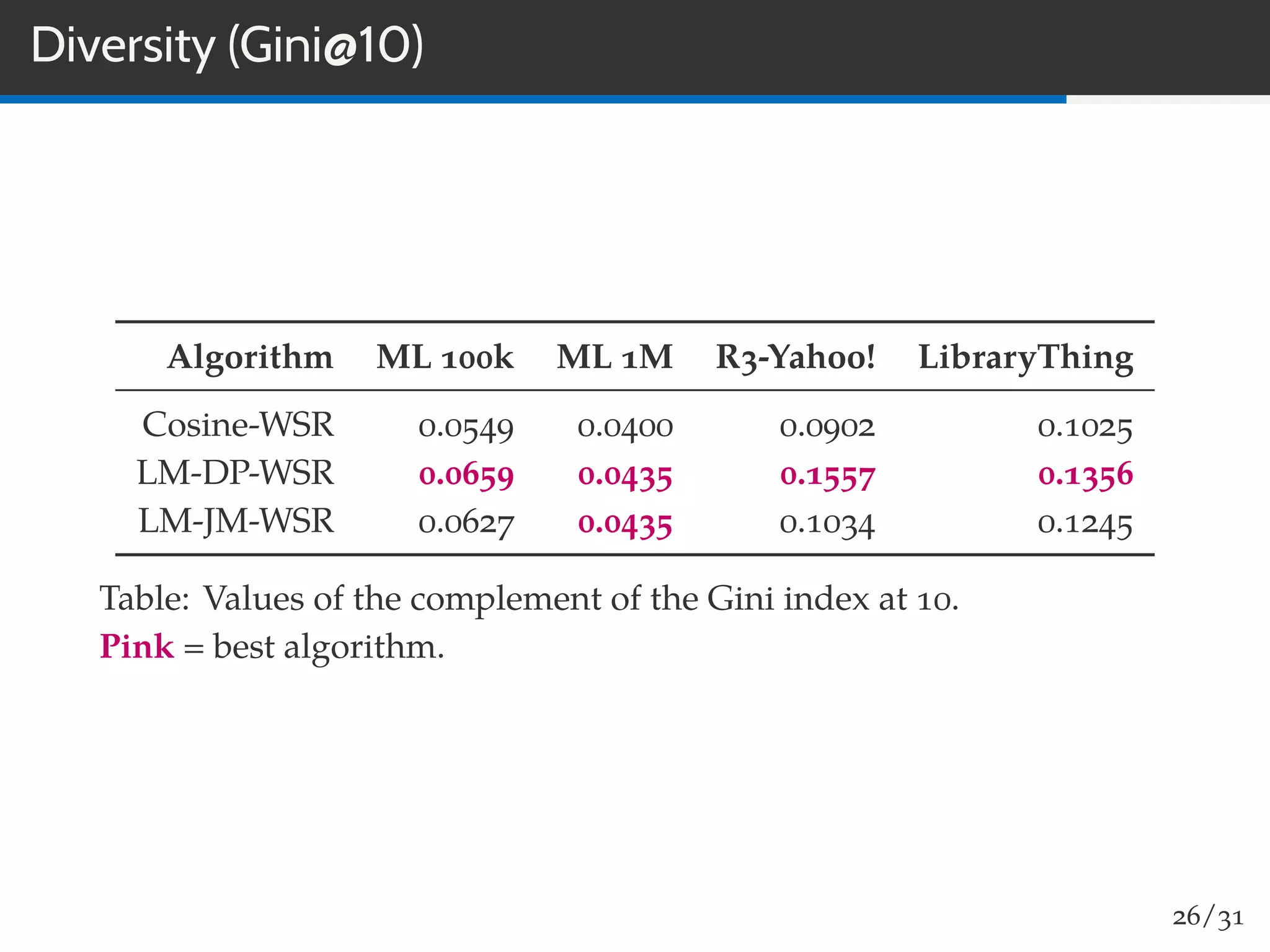
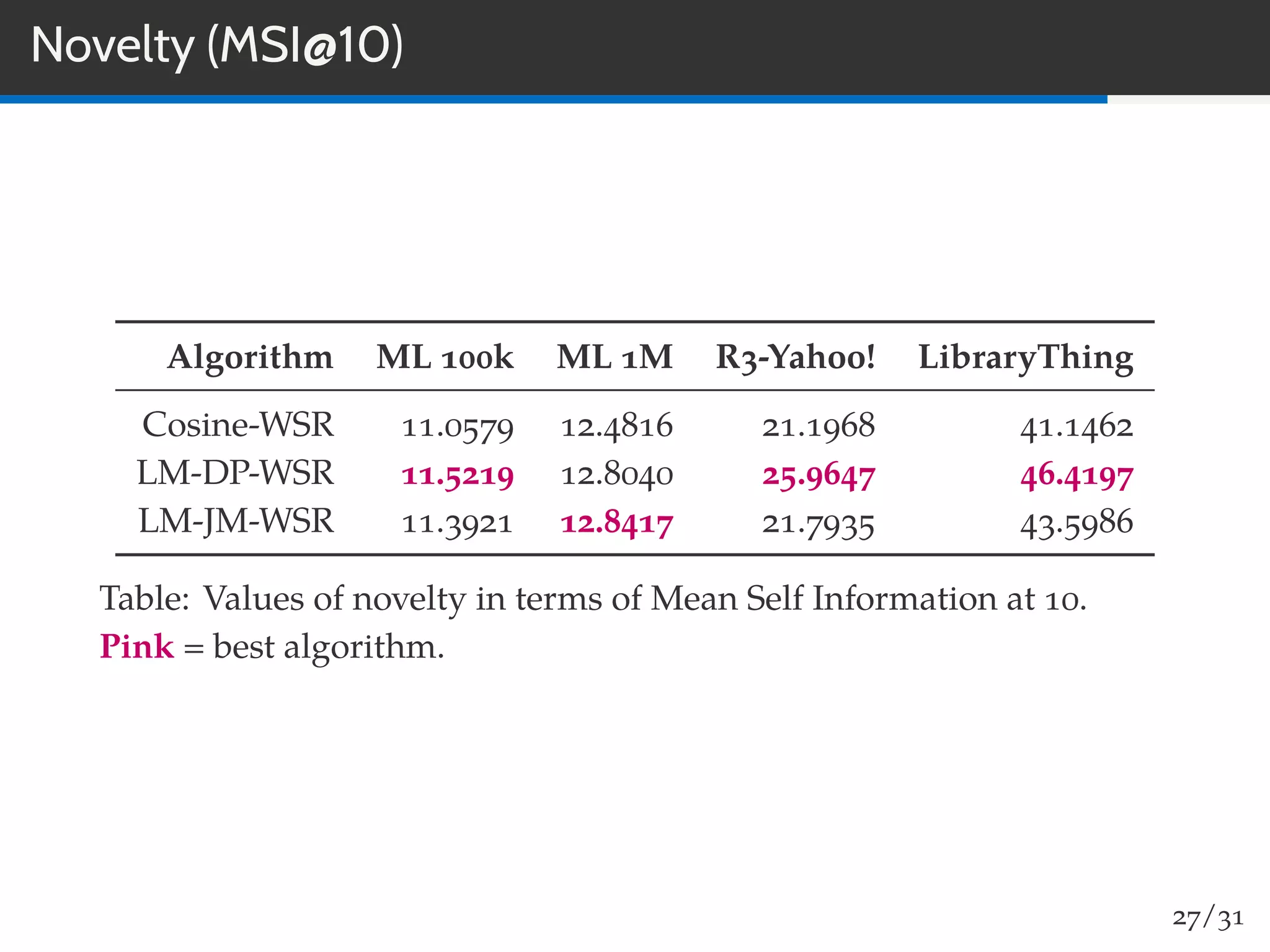
The document discusses a novel approach to collaborative filtering using language models to improve recommendation systems. It emphasizes the importance of pairwise similarities, particularly using cosine similarity, to enhance performance and presents experiments demonstrating the effectiveness of this method compared to traditional algorithms. The findings indicate higher accuracy in recommendations, along with improved novelty and diversity, alongside potential future directions for research and application.
















































![[系列活動] 人工智慧與機器學習在推薦系統上的應用](https://cdn.slidesharecdn.com/ss_thumbnails/merged-161217165734-thumbnail.jpg?width=640&height=640&fit=bounds)


























![LiMe: Linear Methods for Pseudo-Relevance Feedback [SAC '18 Slides]](https://cdn.slidesharecdn.com/ss_thumbnails/limeslides-180411100357-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DSC Europe 25] Dragana Ilic - AI for Big Data in Astronomy.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/8palya86qaatvjhva1ms-2-dragana-ilic-ai-ilic-251208151906-652b819c-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Max Talanov - Non digital NNs.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/wif8tr3gtua74qvtopke-non-digital-nns-251205090438-26b0eea6-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Andy Cotgreave - Nothing is new in analytics.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/mba4vzcurvoh5lfrd5zw-6-251205194645-341bbbbe-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DSC Europe 25] Boris Perkovic - Lost in performance.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/uq5hrp7vsuahqkxzifux-1-251204082258-fd2ee09d-thumbnail.jpg?width=640&height=640&fit=bounds)

