Downloaded 41 times















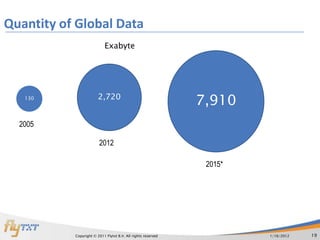




The document discusses big data and the open source big data stack. It defines big data as large datasets that are difficult to store, manage and analyze. Everyday, 2.5 trillion bytes of data are created, with 90% created in the last two years. The open source big data stack includes tools like Hadoop, HBase, Hive and Pig that can handle large datasets through distributed computing across multiple servers. The stack provides flexibility, reliability, auditability and fast deployment at low cost compared to proprietary solutions.







































![Deriving economic value for CSPs with Big Data [read-only]](https://cdn.slidesharecdn.com/ss_thumbnails/derivingeconomicvalueforcspswithbigdata-final11sep2013read-only-130911045922-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)





















































