Download as PDF, PPTX



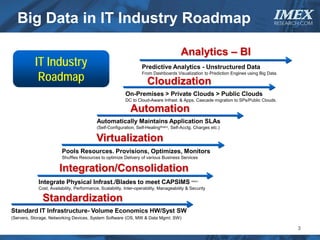
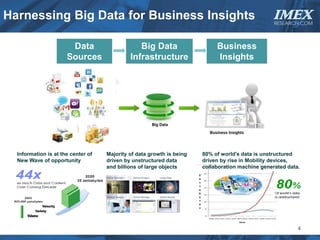

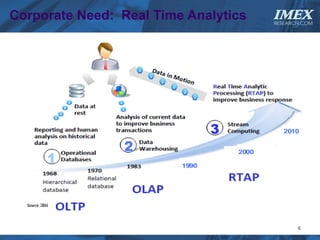



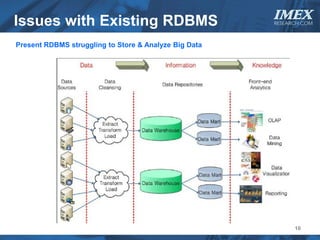
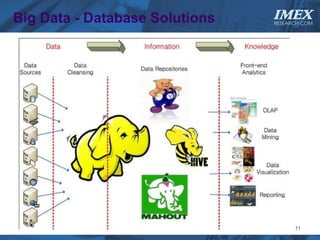

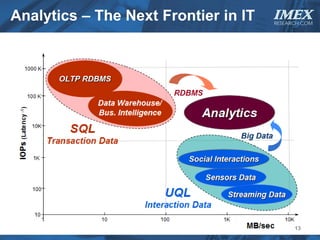
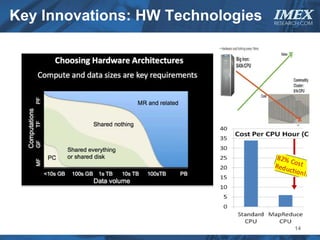
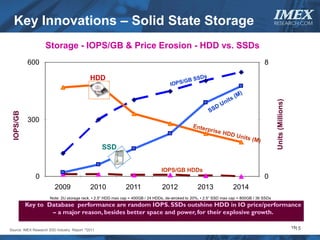
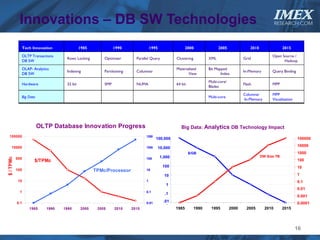

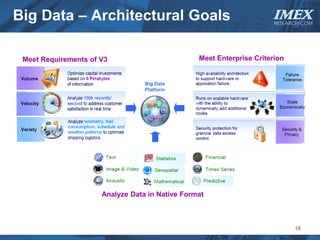




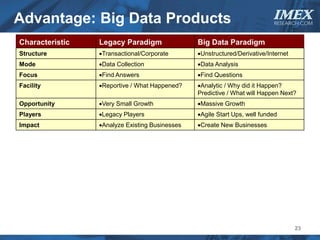
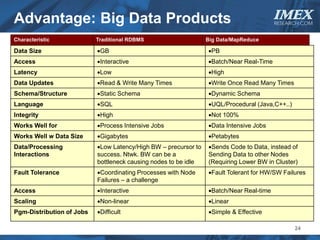
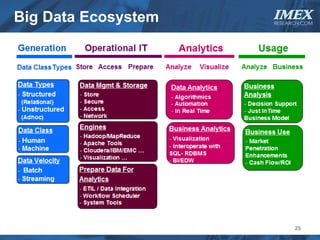
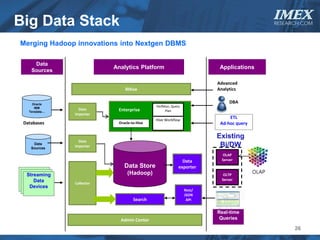
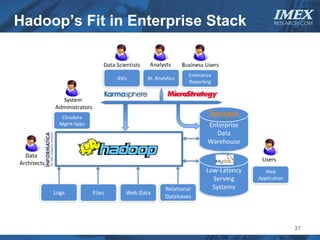
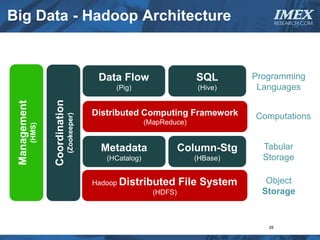
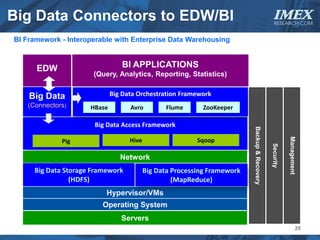
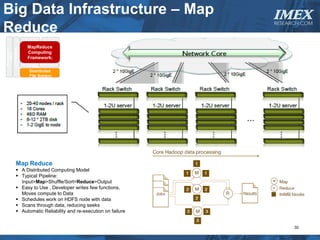
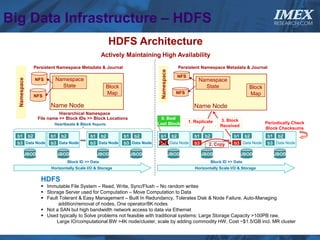
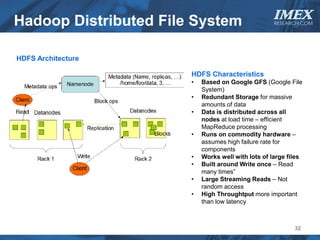
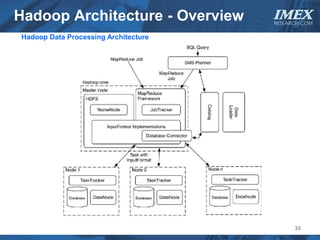

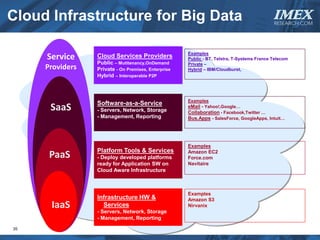
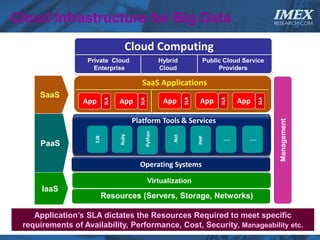
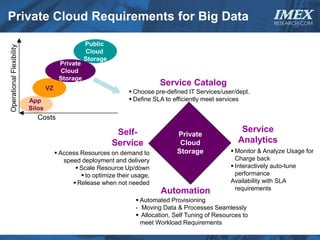
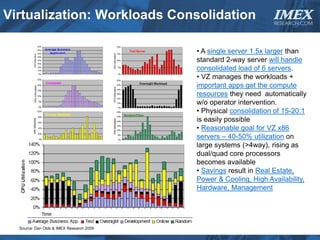

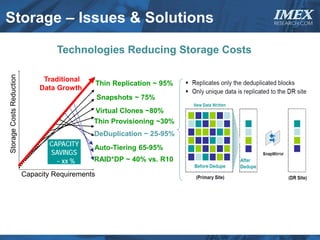
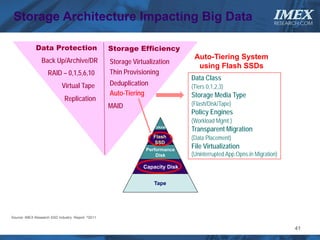

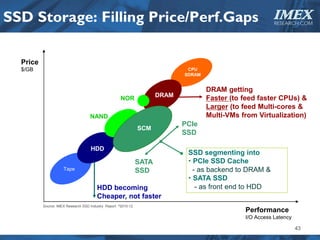
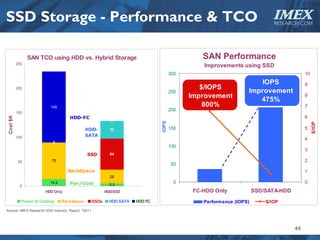
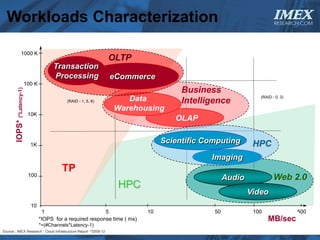

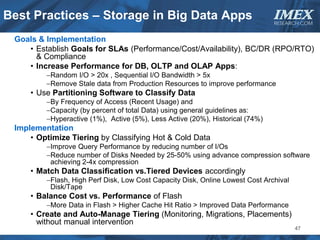
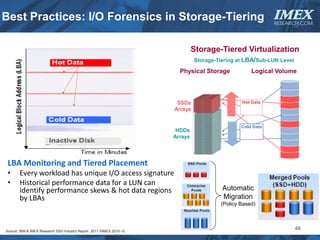

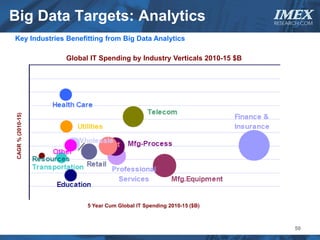
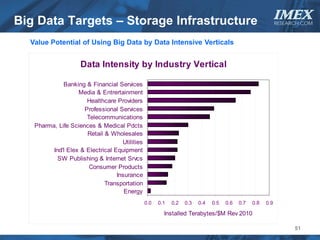

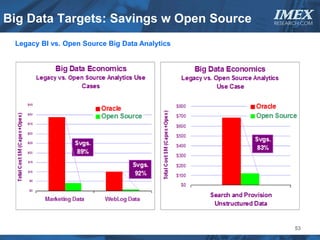
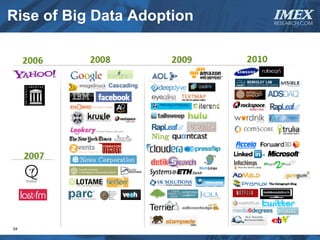


The document discusses how big data is driving the need for new database technologies that can handle large, unstructured datasets and provide real-time analytics capabilities that traditional relational databases cannot support. It outlines the limitations of relational databases for big data and analyzes emerging technologies like Hadoop, NoSQL databases, and cloud computing that are better suited for storing, processing, and analyzing large volumes of diverse data types. The document also examines the infrastructure, architectural, and market requirements for big data platforms and products.






















































































