Downloaded 42 times









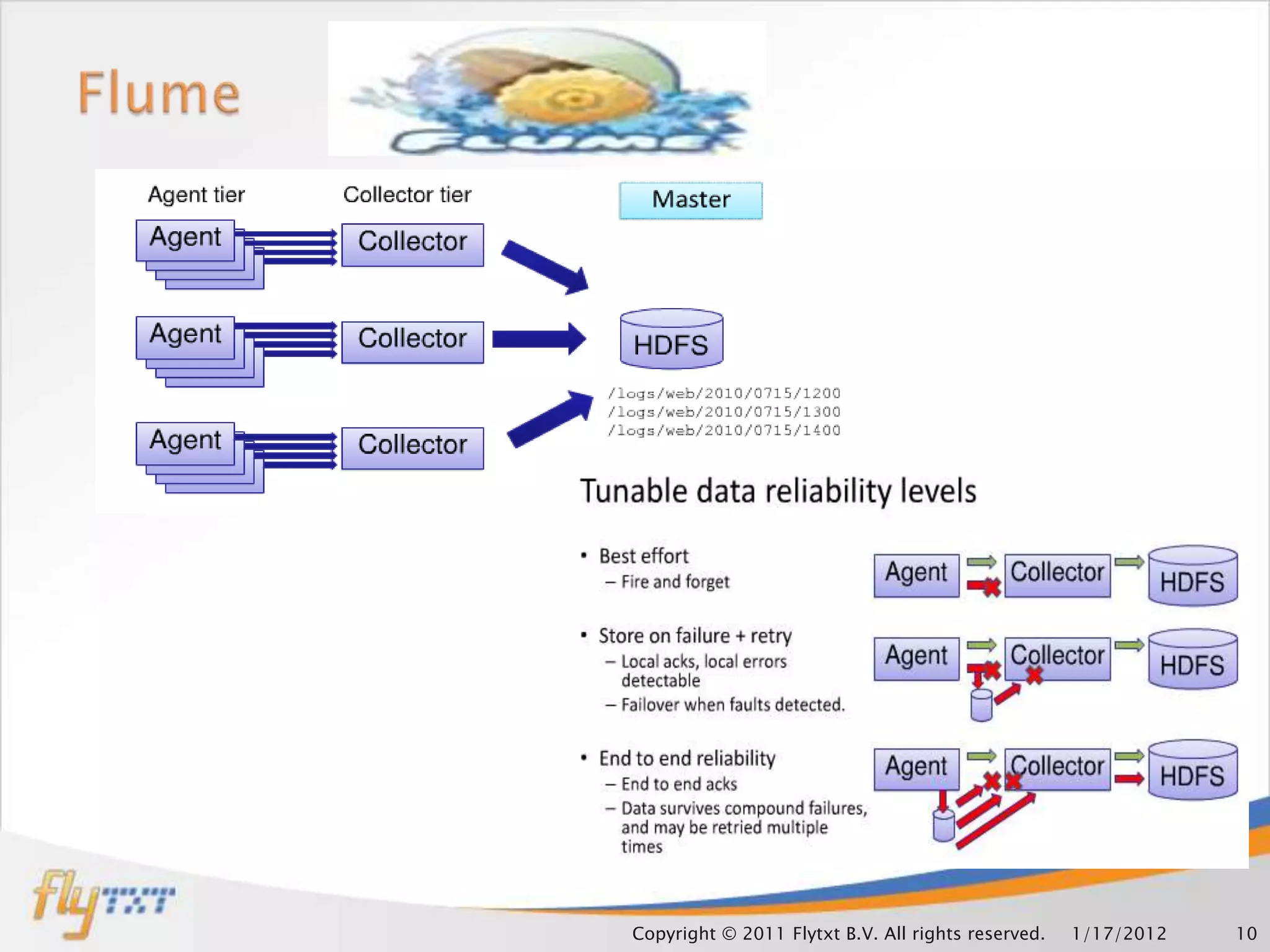




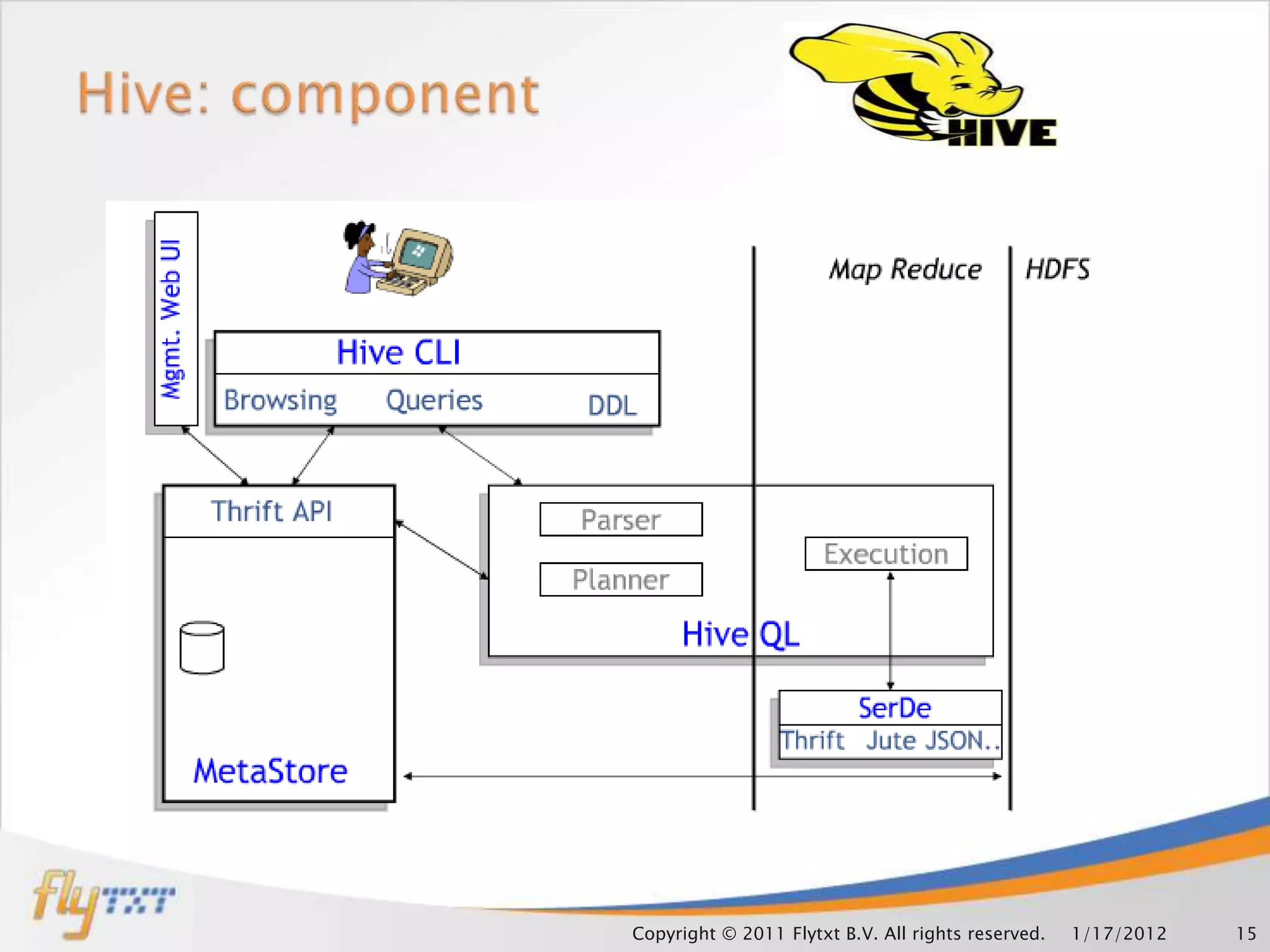
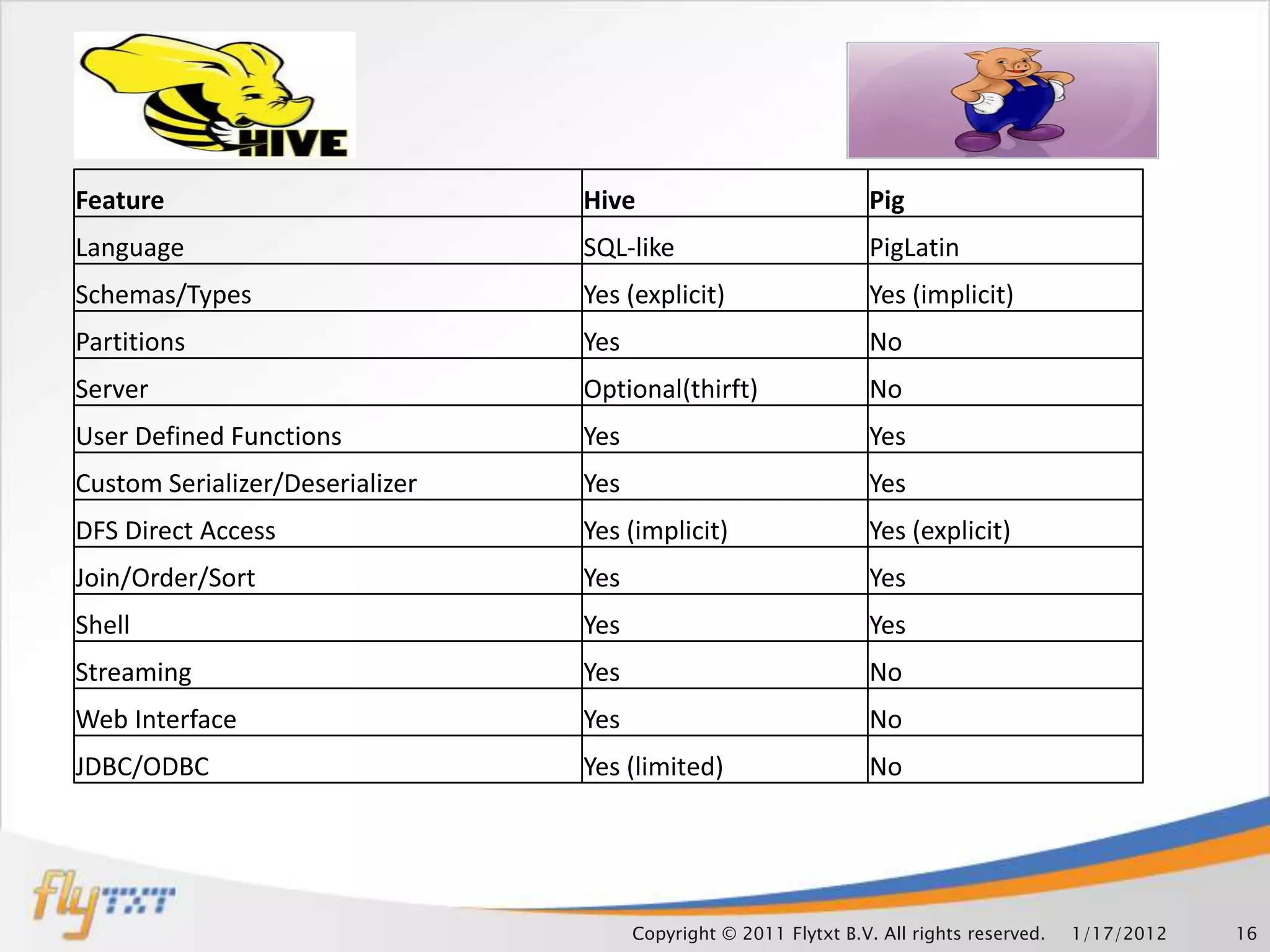
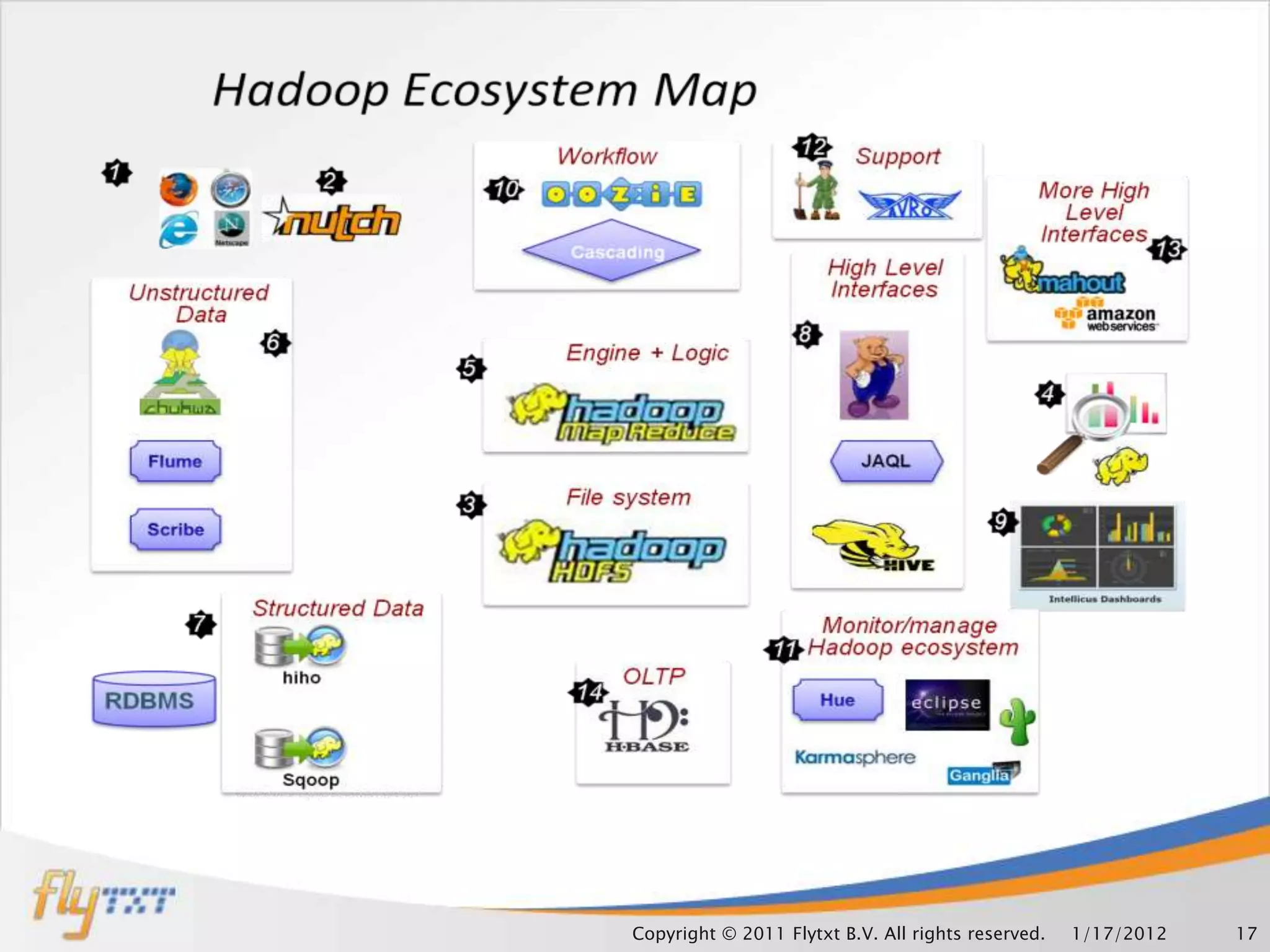


This document discusses leveraging Hadoop clusters for carrier grade applications. It notes that carriers generate huge amounts of data daily from sources like call detail records, signaling data, web traffic and SMS. Hadoop is presented as a solution for analyzing this "mammoth data" through its distributed processing capabilities and ability to handle large datasets across clusters. The document outlines components of Hadoop like HDFS, MapReduce and how it can help address bottlenecks in traditional systems for loading, accessing and analyzing carrier data at scale.




























![Deriving economic value for CSPs with Big Data [read-only]](https://cdn.slidesharecdn.com/ss_thumbnails/derivingeconomicvalueforcspswithbigdata-final11sep2013read-only-130911045922-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
















![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)












