Download to read offline























![Gecko Delete
Vault: Petcare Data
Platform
Mars Petcare Business
Unit (Veterinary)
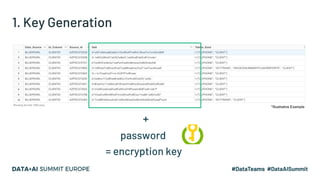
Right To Forget
Request:
Banfield ID
7586241
Right to forget
request comes from
the Business Unit
Via the OneTrust
System
Client is
identified within
the Vault Client’s Salt is redacted from
the ID table
• Without the Salt ID, the Encryption Key cannot be generated
• We only have to remove a single record from a single table but we achieve both of the following:
• From this point onwards, the Client PII can never be retrieved from the Vault
• All of the non-PII data stays exactly as it was in the lake, safely maintaining its overall integrity and value
7586241 [GECKO REDACTED]
*Illustrative Example](https://image.slidesharecdn.com/43haleharrington-201124203817/85/Leveraging-Apache-Spark-and-Delta-Lake-for-Efficient-Data-Encryption-at-Scale-28-320.jpg)







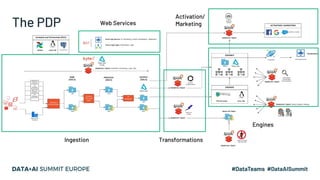
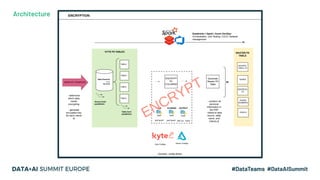
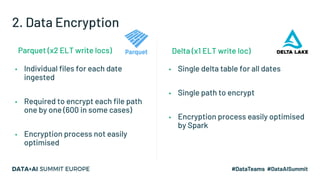
The document discusses leveraging Apache Spark and Delta Lake for enhanced data encryption, particularly related to CCPA compliance within Mars Petcare's data platform. It introduces 'Gecko', an ecosystem that utilizes row-level encryption for personal identifiable information (PII) and outlines its core functions for managing and deleting PII securely and efficiently. The presentation highlights optimizations in data processing to improve security, speed, and data integrity while also detailing future enhancements for the system.





































































![[DSC Europe 25] Harshvardhan Jain - From Pre-Trained to Purpose-Built: Fine-T...](https://cdn.slidesharecdn.com/ss_thumbnails/zru4zmiseku5tgvu2dgw-harshvardhan-jain-from-pre-trained-to-purpose-built-fine-tuning-llms-for-high-i-260119101520-8335585f-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Laila Kakar - Leveraging AI for Strategic Excellence: Enhanci...](https://cdn.slidesharecdn.com/ss_thumbnails/eykmhrtsqmaaftwkexh7-dsc-lailakakar-1-260119101520-5f3b5616-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Srdj Stanisic - Local and Private AI in UX.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/vwmetykqmztgmokmmkfa-3-srdjan-stanisic-local-and-small-ai-in-ux-260120105855-55a31869-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Jovan Sumarac - Real-World Applications of Computer Vision in...](https://cdn.slidesharecdn.com/ss_thumbnails/fiksms22smcpopvvld03-jovan-sumarac-real-life-applications-of-computer-vision-in-automotive-systems-260120105855-de622abb-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Tali Fulman - Guild Meetings, Then What? Building Data Commun...](https://cdn.slidesharecdn.com/ss_thumbnails/fgohhi33rwmhqdowdj5k-tali-fulman-guild-meetings-then-what-building-data-communities-that-actually-ch-260120105855-528492c3-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Dubravko Culibrk - Deep Learning for Mammography.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/yiscimuktacgqoiu4dkp-deep-learning-for-mammography-260119121559-aad59182-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Bojan Banjac - AI is always right when it comes to the matter...](https://cdn.slidesharecdn.com/ss_thumbnails/syoxtqierpydwxm5srcb-4-bojan-banjac-ai-is-always-right-when-it-comes-to-the-matters-of-taste-260119101519-694ee7d7-thumbnail.jpg?width=640&height=640&fit=bounds)
