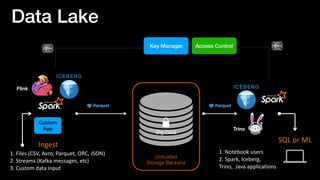
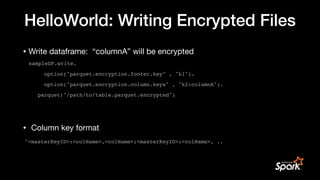
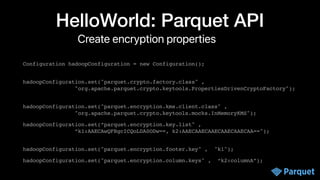
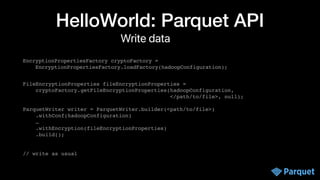
The document presents a comprehensive overview of big data security within various Apache projects, particularly focusing on the security features of Apache Parquet, Spark, Iceberg, and others. It discusses modular encryption capabilities, performance impacts, integration options, and various use-cases for ensuring data confidentiality and integrity. The document also provides insights into configuration and implementation details for encryption in data workflows across Apache ecosystems.



















![Real World
• Master keys are kept in your KMS (Key Management Service) in your platform
• controls key access for users in your organization
• if your org doesn’t have KMS: use cloud KMS, or install an open source KMS
• Develop client for your KMS server
• Implement KMS client interface
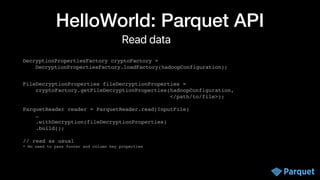
public interface KmsClient {
// encrypt e.g. data key with master key (envelope encryption)
String wrapKey(byte[] keyBytes, String masterKeyIdentifier)
// decrypt key
byte[] unwrapKey(String wrappedKey, String masterKeyIdentifier)
}](https://image.slidesharecdn.com/apachecon22-gershinskybig-data-security-221218065509-43ca39b6/85/Big-Data-Security-in-Apache-Projects-by-Gidon-Gershinsky-24-320.jpg)









































































![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)




