Download to read offline







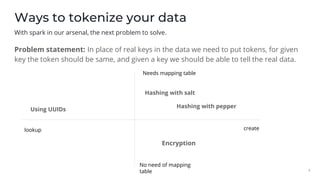








The document outlines the development of a PII scrubbing layer utilizing masking and tokenization techniques to enhance data accessibility and security for analysts and stakeholders. It discusses the shift from using pandas to Apache Spark due to performance issues and the challenges of data ingestion from various sources. The final implementation involves a comprehensive setup including Airflow and Docker, with necessary considerations for job management, token creation, and system architecture.















































