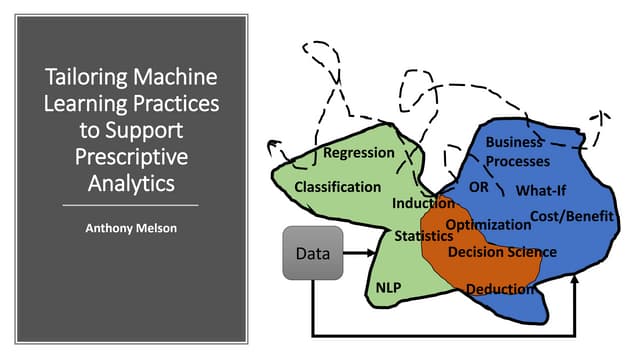
The document outlines various data engineering roles including data store engineer, ETL engineer, and machine learning engineer, detailing their responsibilities and required skills. Each role focuses on specific aspects of data management and processing such as data retrieval, optimization, quality, visualization, and deployment. The document emphasizes the importance of programming languages like SQL, Python, and tools like Hadoop and AWS in these positions.