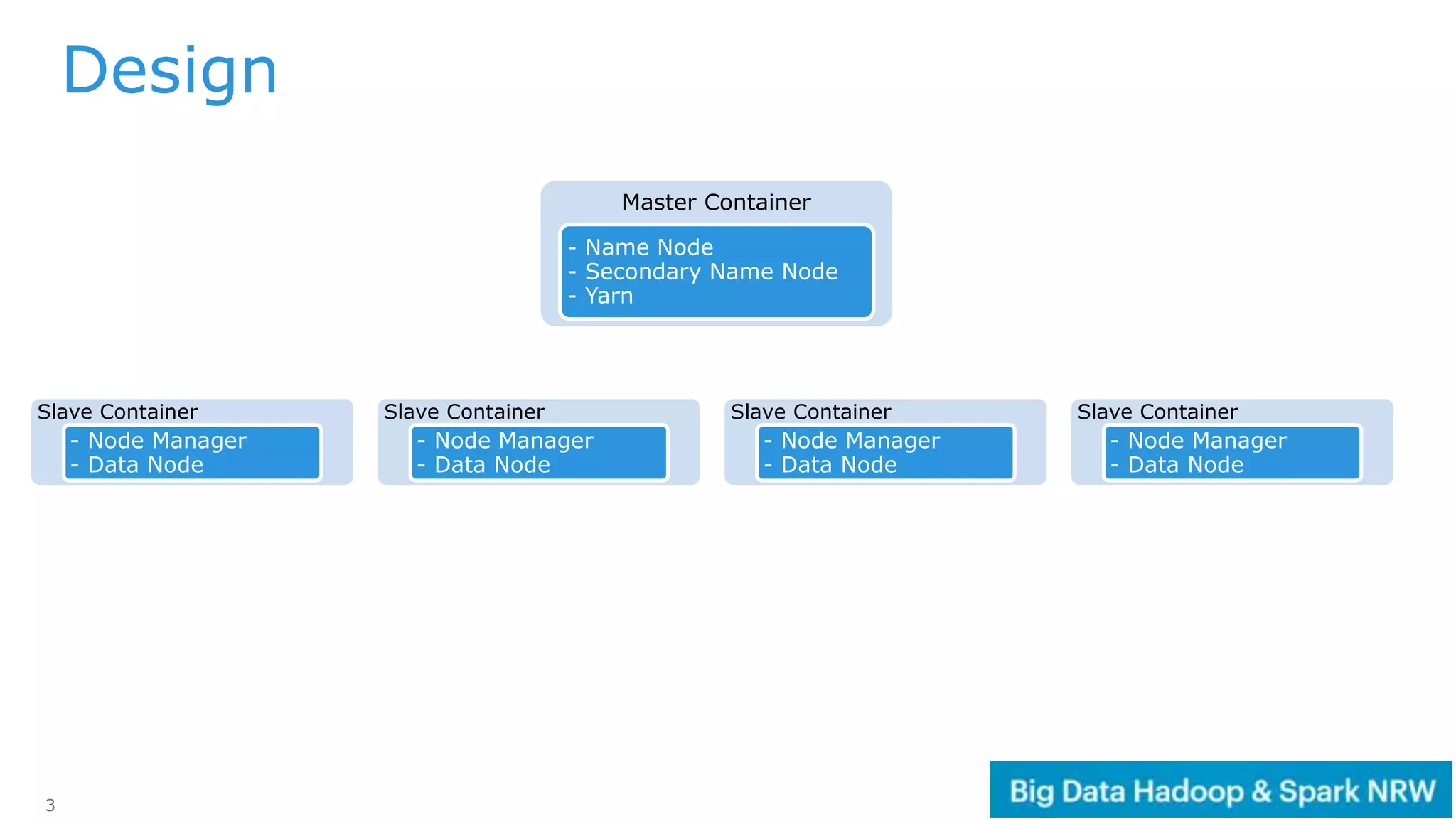
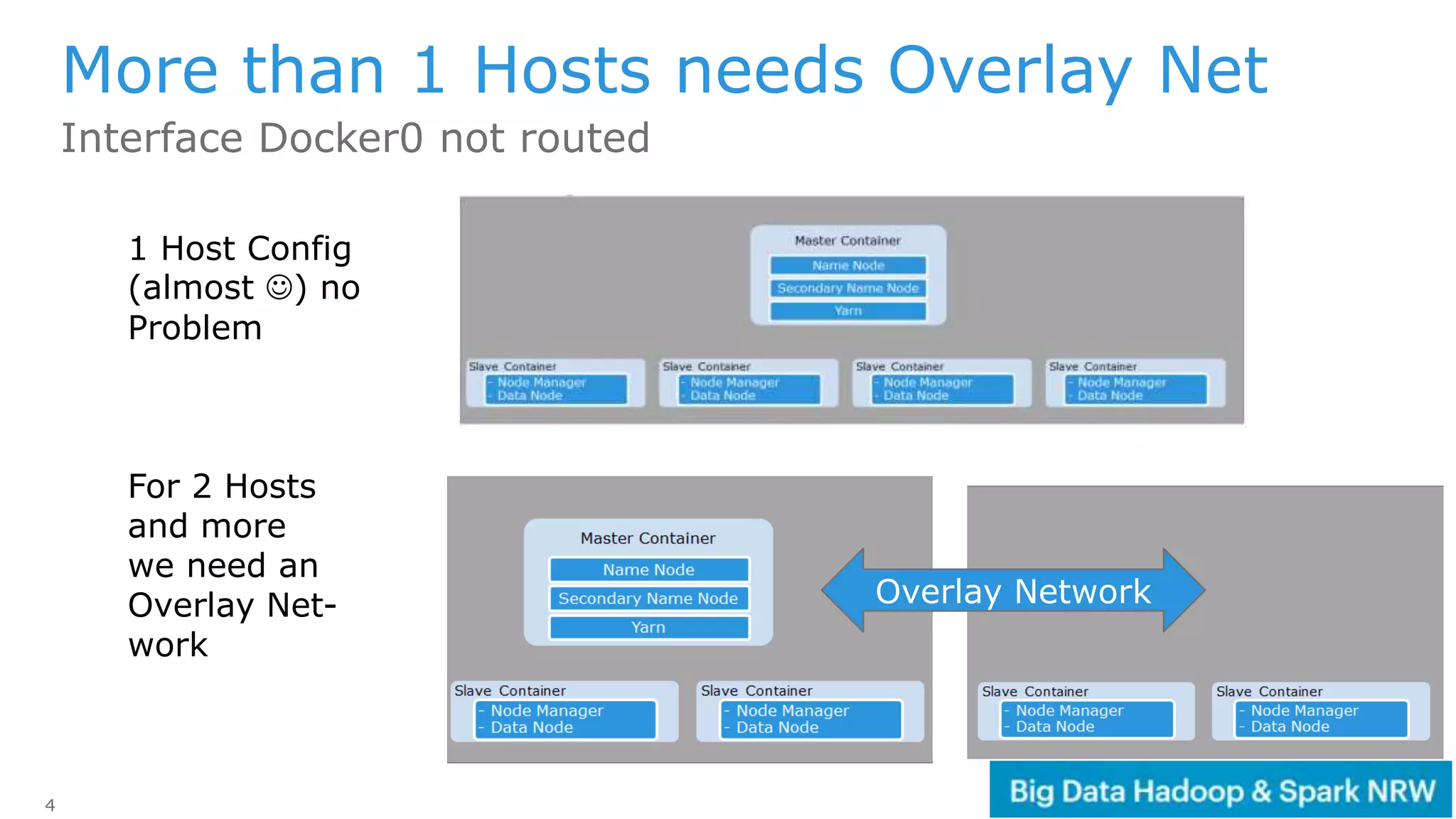
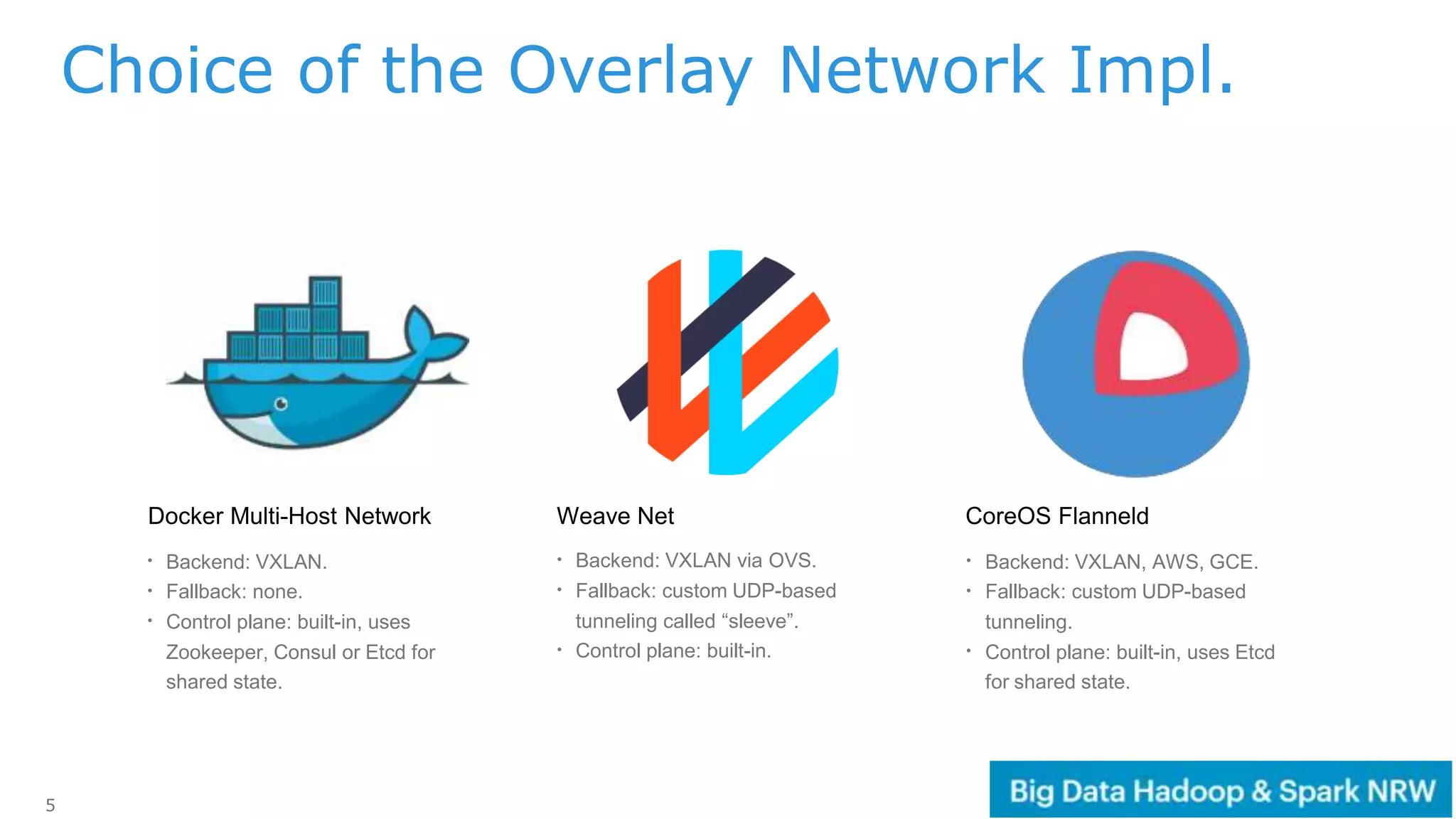
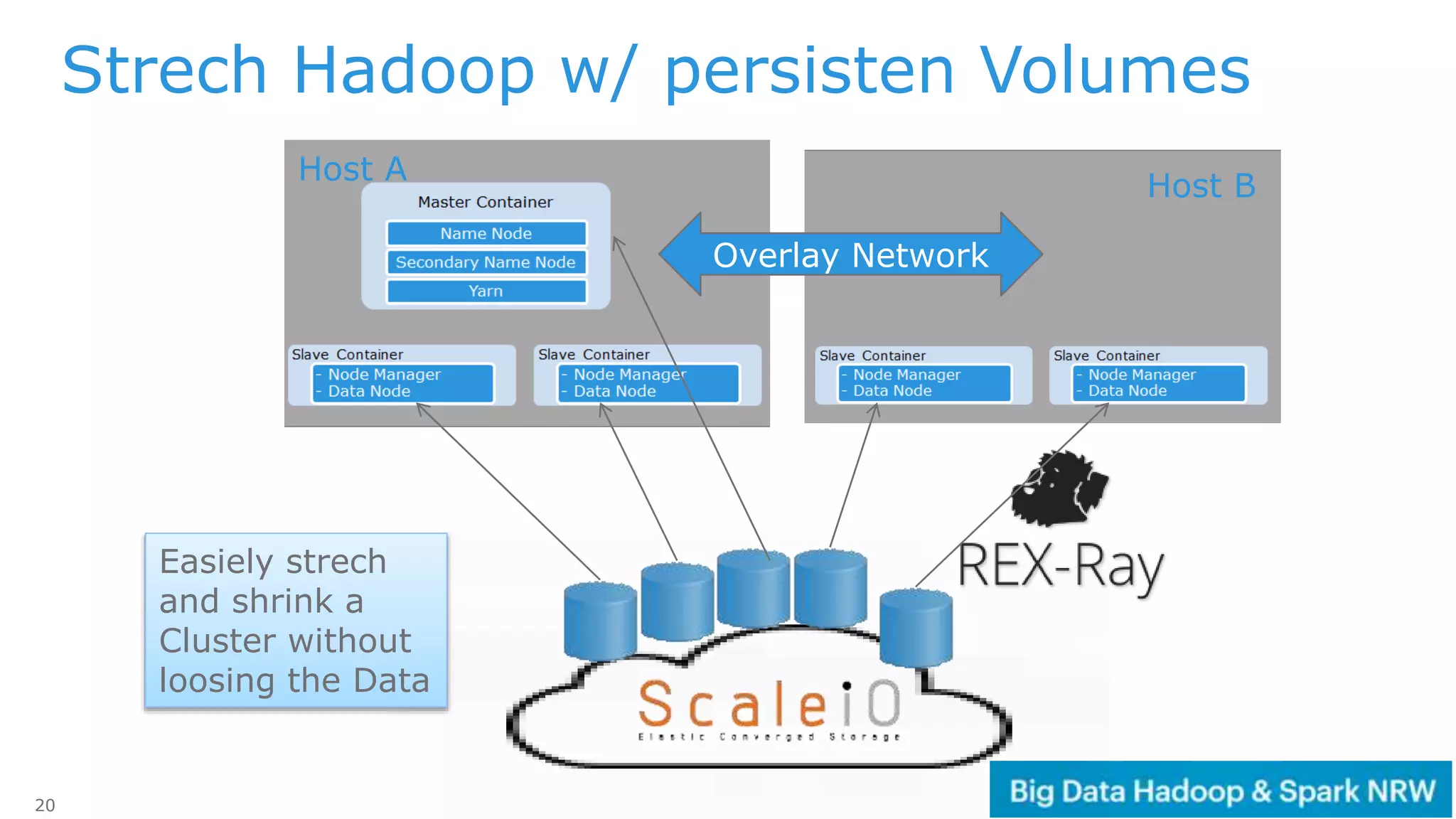
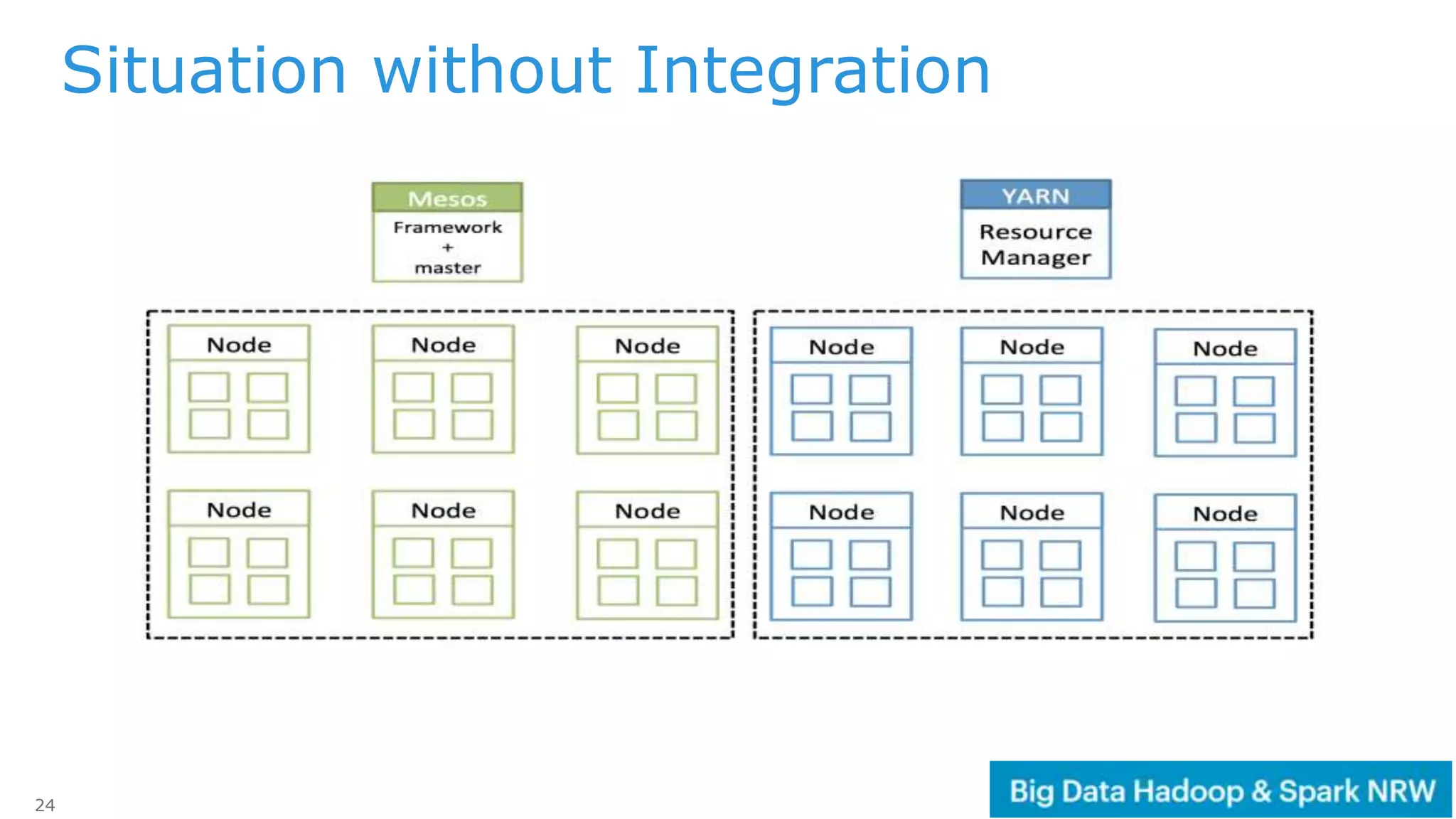
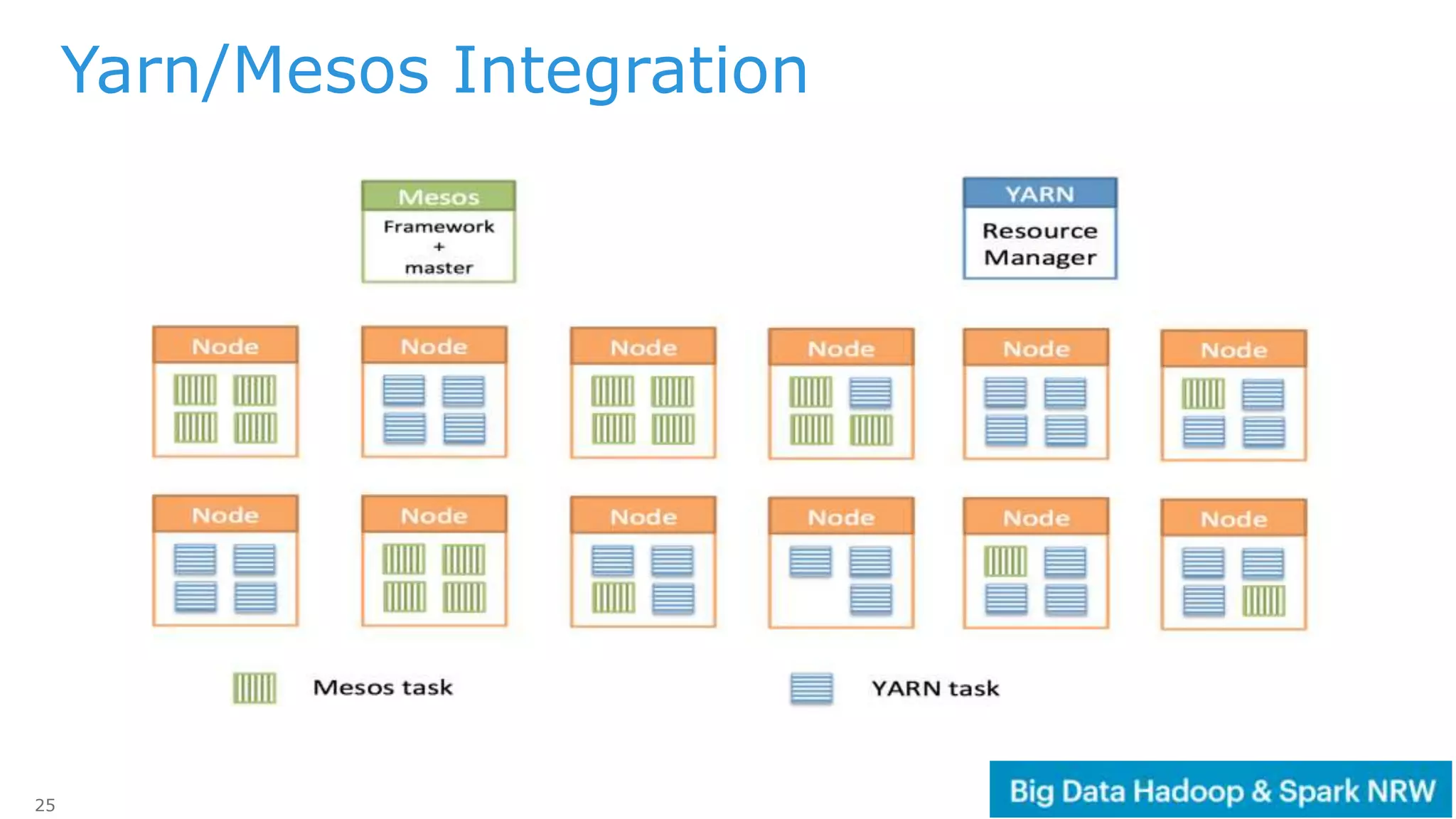
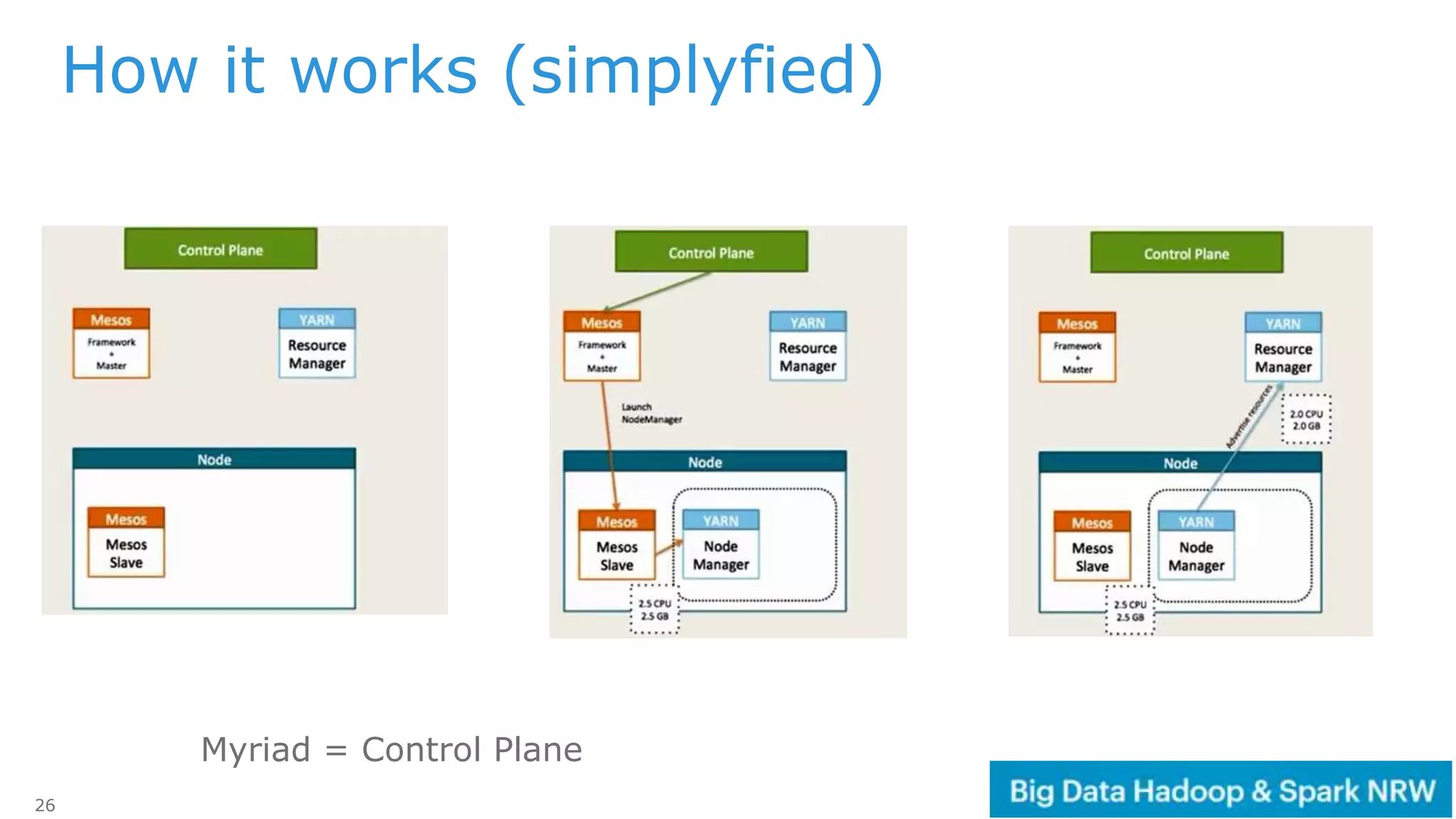
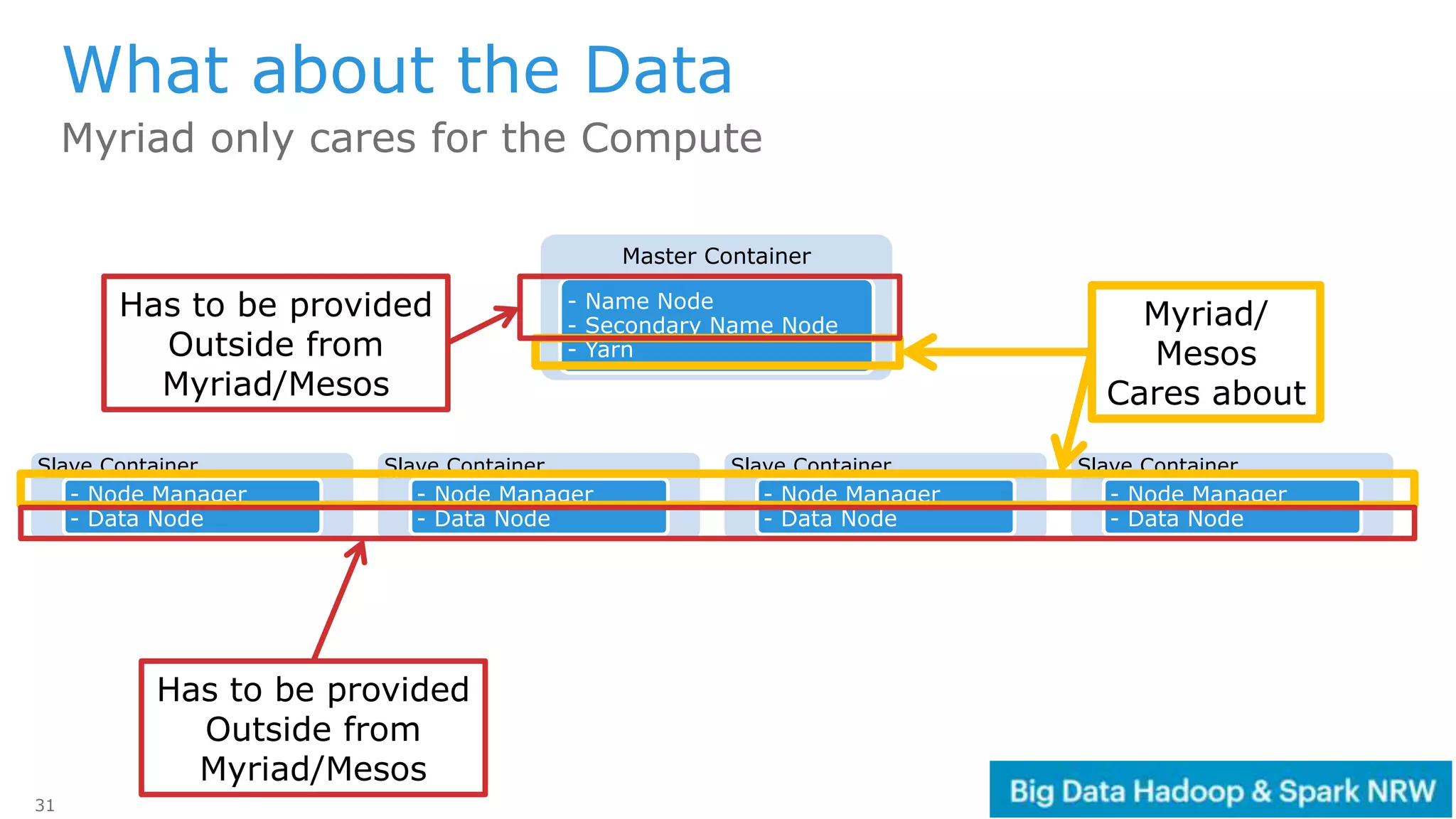
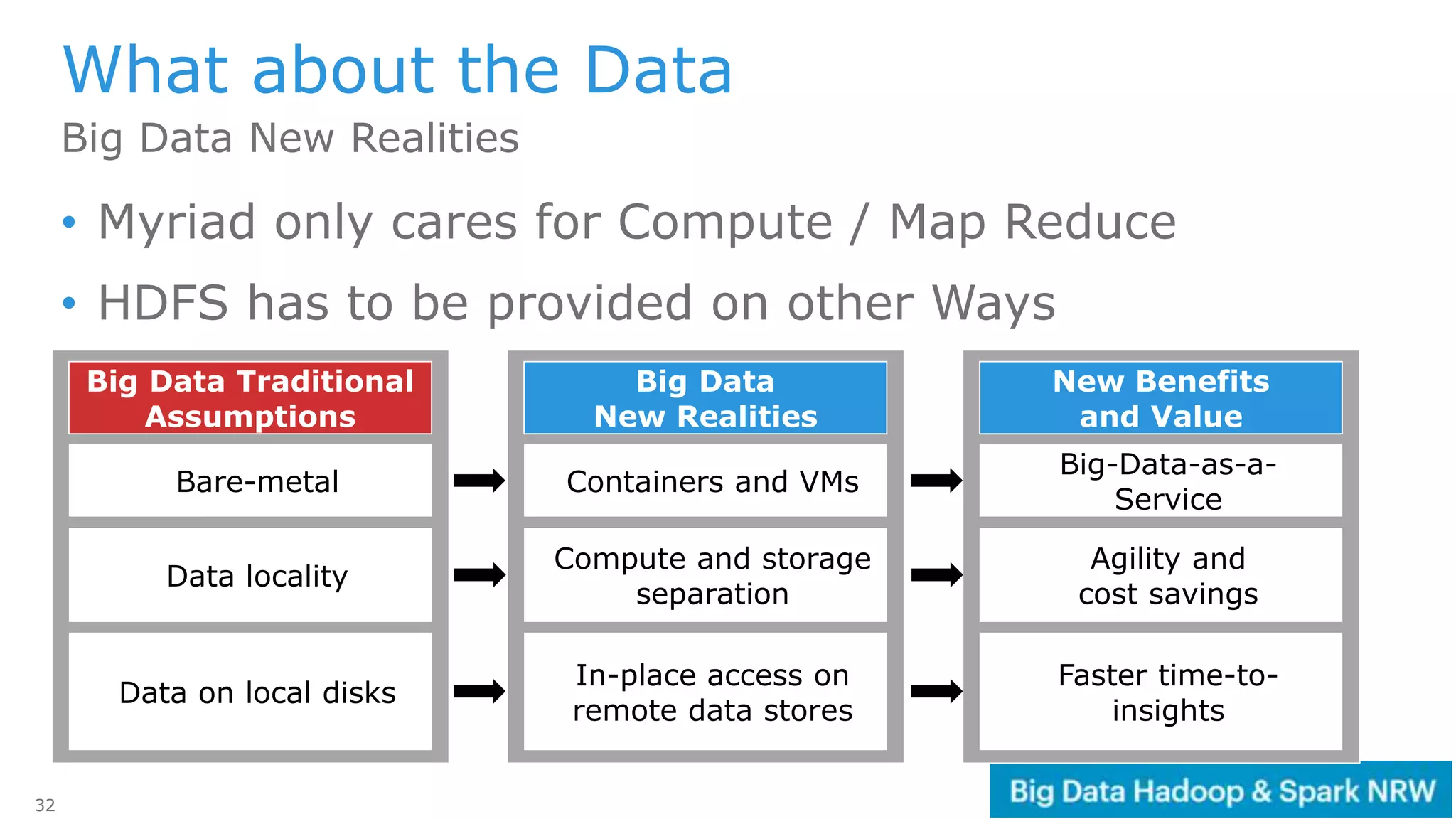
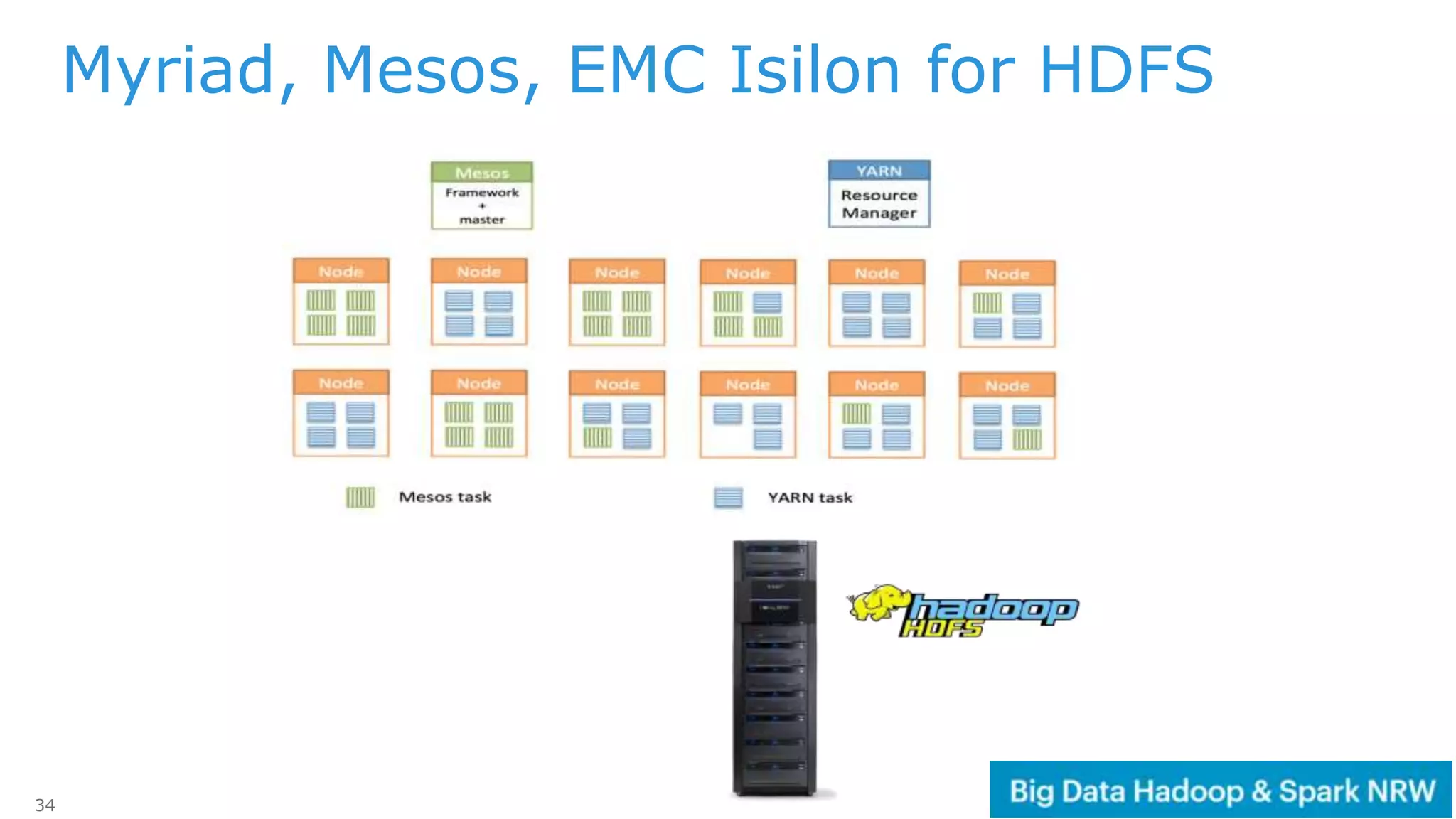
The document discusses the deployment and management of a Hadoop cluster using Docker containers and overlay networking. It explores the use of various network implementations and the necessity for persistent storage solutions in containerized environments, particularly focusing on the relationship between Hadoop and persistent volumes. Additionally, it highlights integration with Mesos for resource management and outlines challenges and solutions for operationalizing big data through containers.





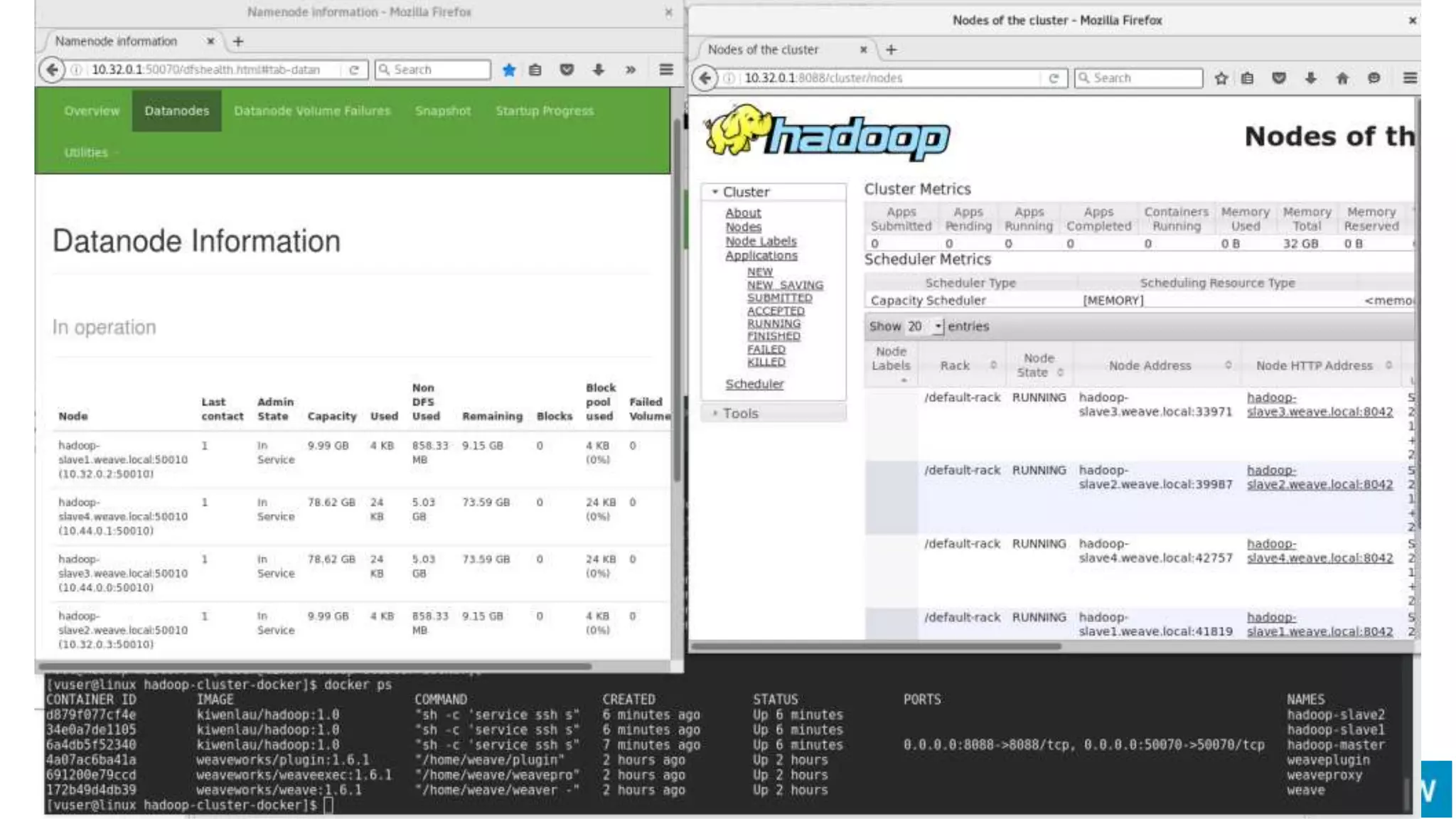
![9
[vuser@linux ~]$ ifconfig | grep -v "^ "
docker0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
enp3s0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
[vuser@linux ~]$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
[vuser@linux ~]$ sudo weave launch
[vuser@linux ~]$ eval $(sudo weave env)
[vuser@linux ~]$ sudo weave -–local expose
10.32.0.6
[vuser@linux ~]$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
0fd6ab928d96 weaveworks/plugin:1.6.1 "/home/weave/plugin" 11 seconds ago Up 8 seconds weaveplugin
4b24e5802fcc weaveworks/weaveexec:1.6.1 "/home/weave/weavepro" 13 seconds ago Up 10 seconds weaveproxy
c4882326398a weaveworks/weave:1.6.1 "/home/weave/weaver -" 18 seconds ago Up 15 seconds weave
[vuser@linux ~]$ ifconfig | grep -v "^ "
datapath: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1410
docker0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
enp3s0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
vethwe-bridge: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1410
vethwe-datapath: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1410
vxlan-6784: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 65485
weave: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1410
WEAVE
Container
WEAVE Interfaces
Weave Run](https://image.slidesharecdn.com/hadoop-container-160825075722/75/Big-Data-in-Container-Hadoop-Spark-in-Docker-and-Mesos-9-2048.jpg)
![10
https://github.com/kiwenlau/hadoop-cluster-docker/blob/master/Dockerfile
Hadoop Container Docker File
FROM ubuntu:14.04
# install openssh-server, openjdk and wget
# install hadoop 2.7.2
# set environment variable
# ssh without key
# set up Hadoop directorties
# copy config files from local
# make Hadoop start files executable
# format namenode
#standard run command
CMD [ "sh", "-c", "service ssh start; bash"]
$ docker build –t loewe/hadoop:latest](https://image.slidesharecdn.com/hadoop-container-160825075722/75/Big-Data-in-Container-Hadoop-Spark-in-Docker-and-Mesos-10-2048.jpg)























































































![[DSC Europe 25] Bassam Maharmeh - Artificial Intelligence: Opportunities and ...](https://cdn.slidesharecdn.com/ss_thumbnails/thhfmr2fqpawzj7hsjpg-5-251211083048-2c23204f-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Debmalya Biswas - Agentification: the art of transforming man...](https://cdn.slidesharecdn.com/ss_thumbnails/r5azlggvtqiaiiusrqdr-4-251212103249-5a12c89b-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Branko Urosevic -Rethinking Financial Talent: Integrating Cod...](https://cdn.slidesharecdn.com/ss_thumbnails/8jjrus8ttko6qj64f58f-3-251212103250-642c6374-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Dunja Adzic Jovanovic - AI and Cybersecurity: Defending Data ...](https://cdn.slidesharecdn.com/ss_thumbnails/o1zylpbhrtwnixxq2xj8-7-251211083048-185086f6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dusan Nesic - Securing Tomorrow’s Infrastructure: Why Cyber-P...](https://cdn.slidesharecdn.com/ss_thumbnails/qikbszfftyowjm2q6duw-1-251211083848-8f2ead6b-thumbnail.jpg?width=640&height=640&fit=bounds)
