
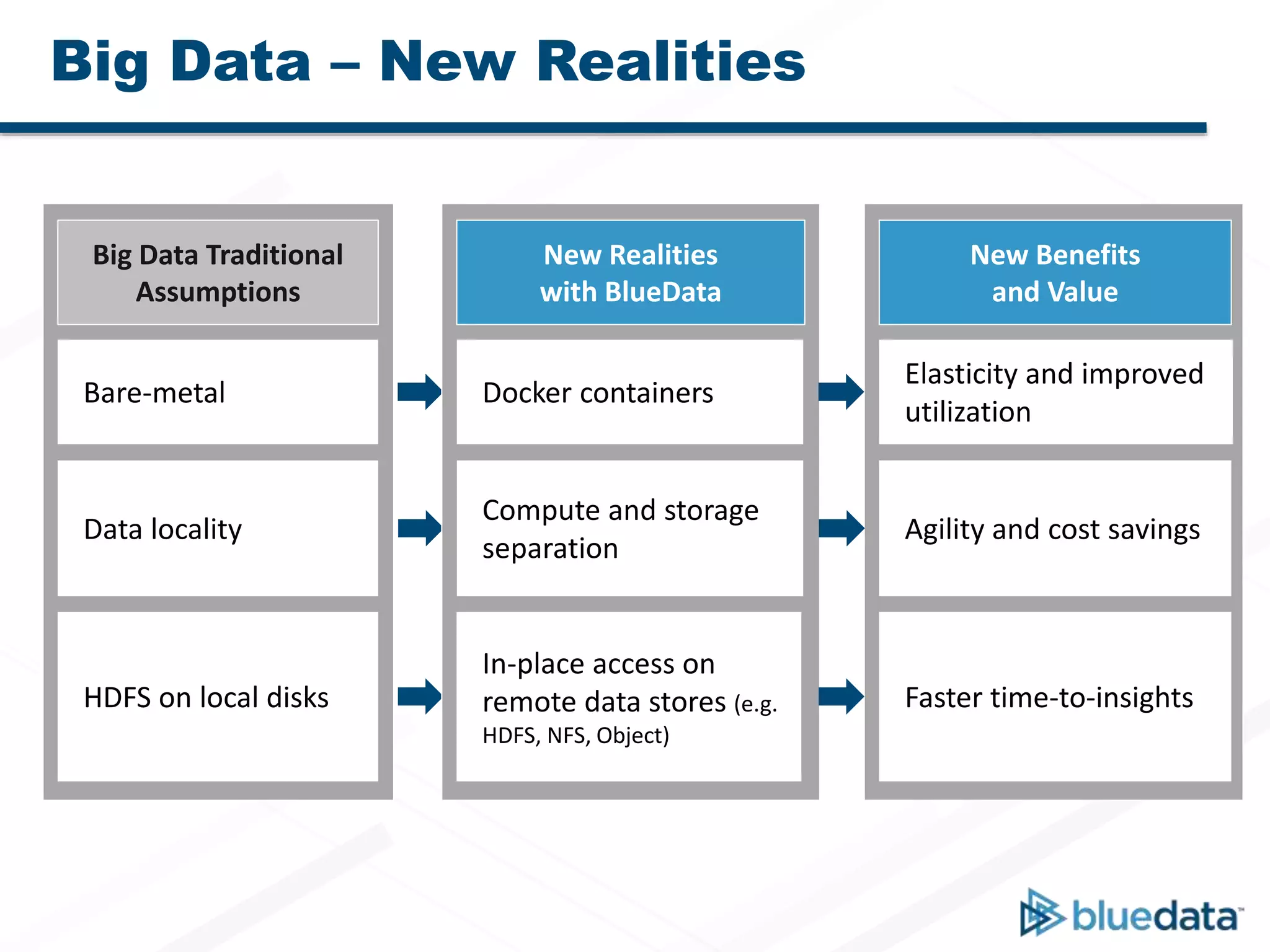
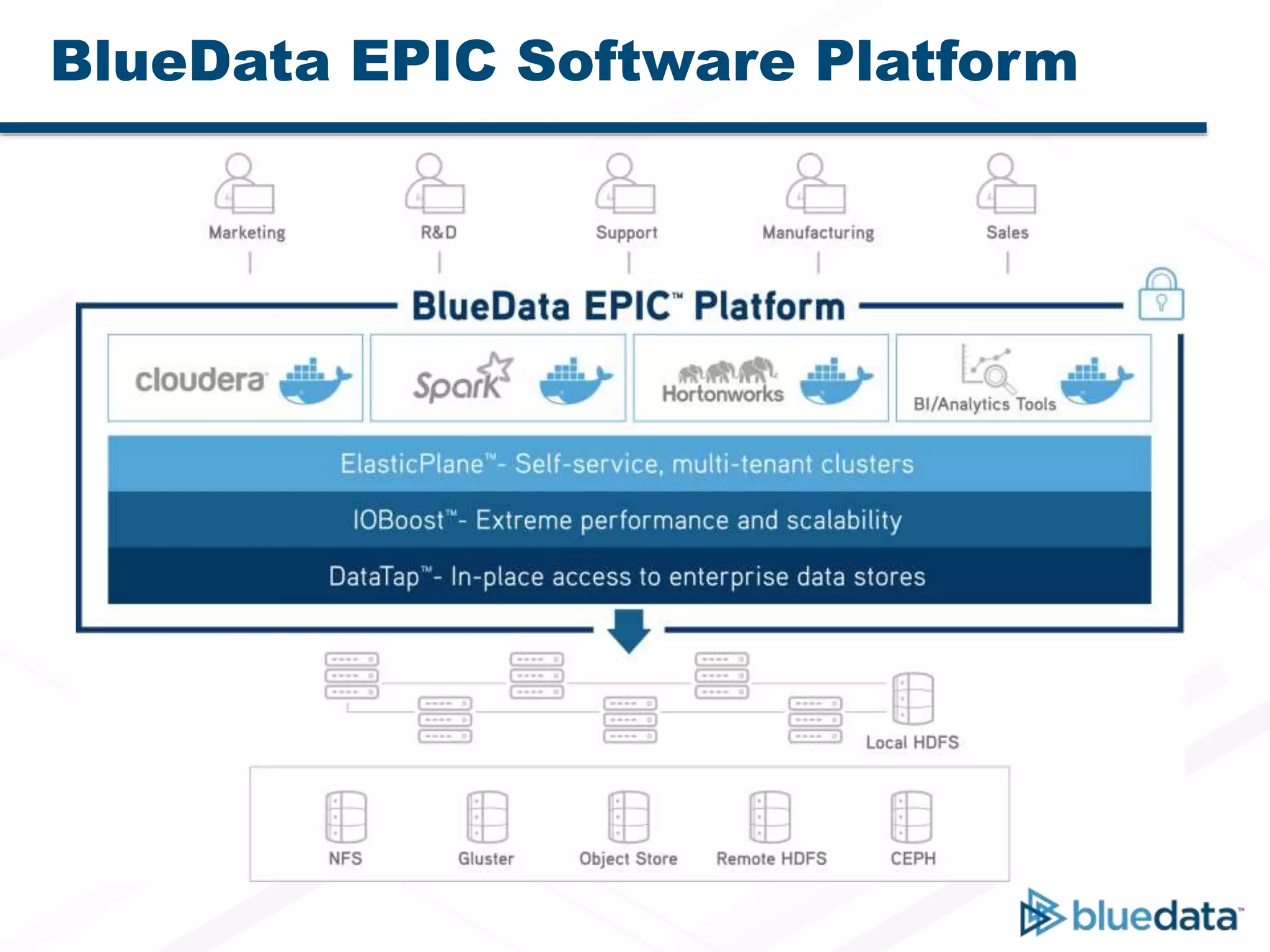



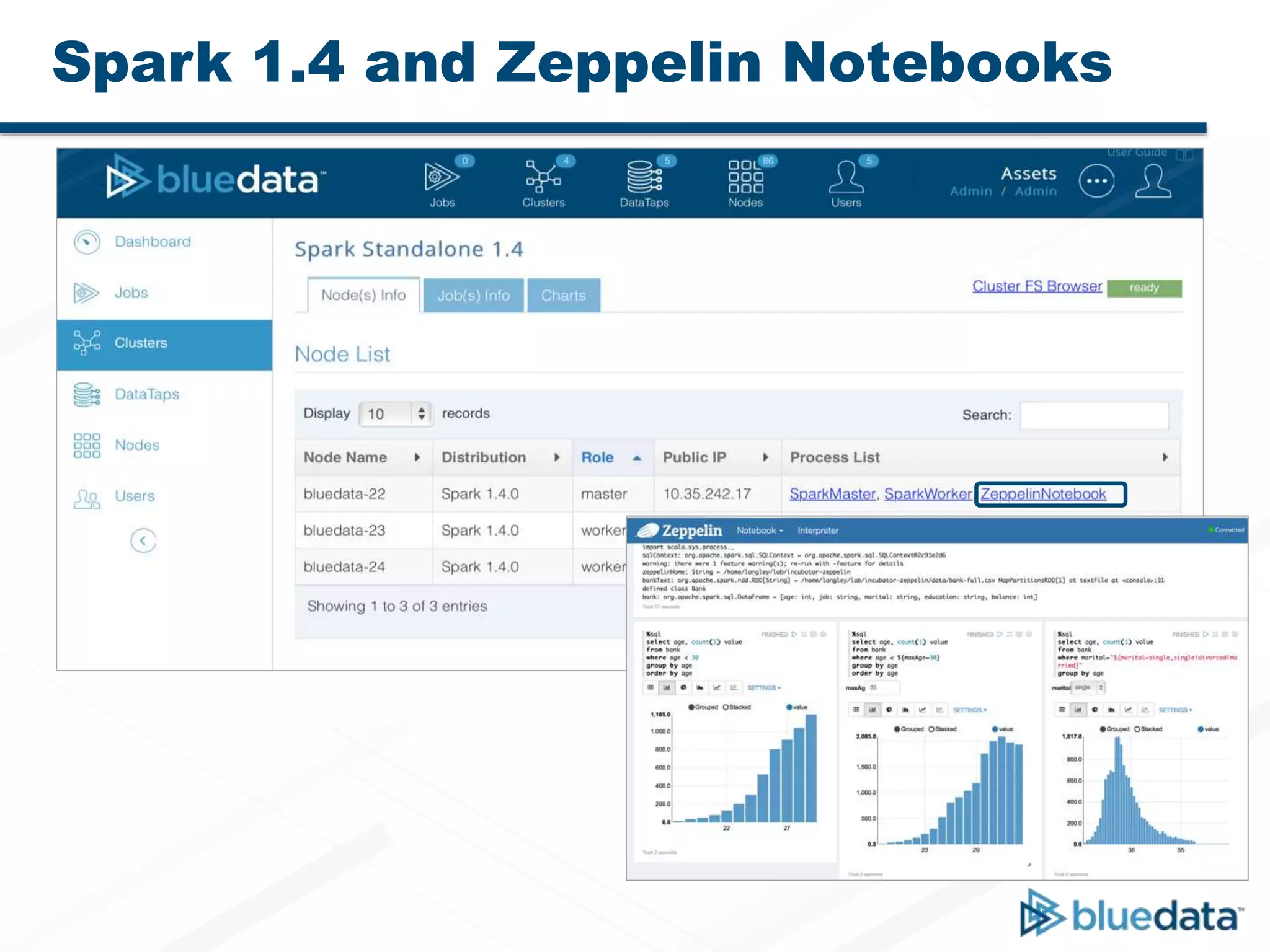
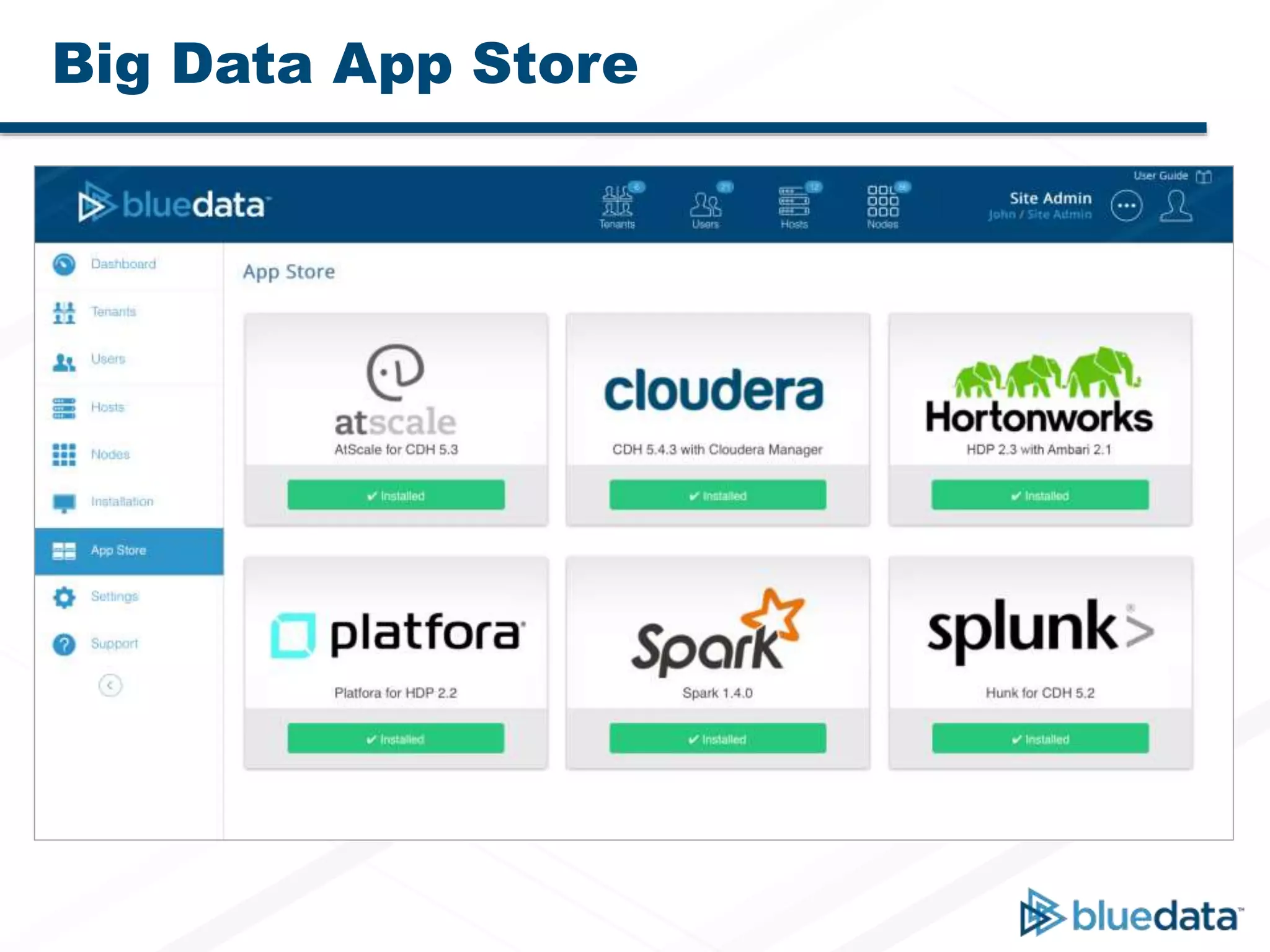
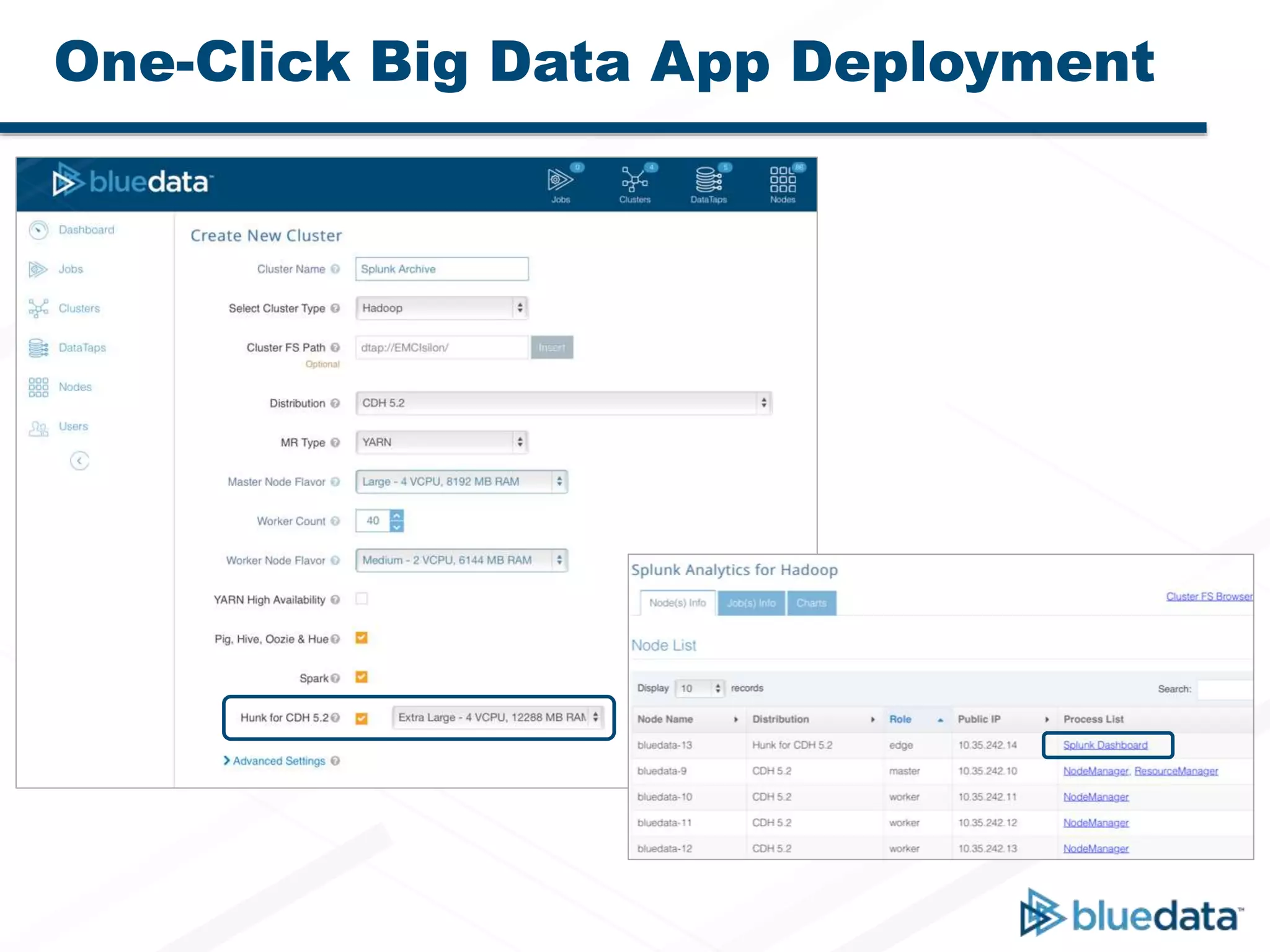


Bluedata Epic 2.0 is a Docker-based platform released on September 23, 2015, that offers flexible deployment options and improved resource management for big data applications. It supports multi-host setups, enhanced Apache Spark integration, and features a big data app store for one-click deployment of analytics tools. The platform emphasizes agility, cost savings, and faster insights while accommodating traditional Hadoop and Spark functionalities.























































































