Downloaded 16 times



































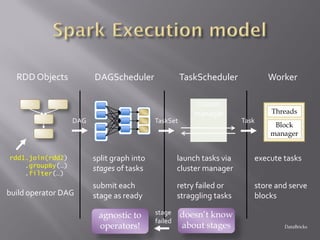
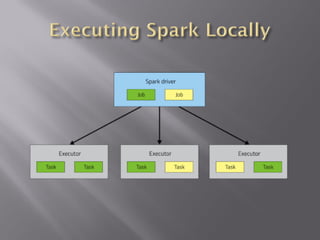
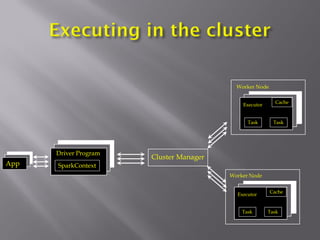





Apache Spark is a fast, general-purpose, and easy-to-use cluster computing system for large-scale data processing. It provides APIs in Scala, Java, Python, and R. Spark is versatile and can run on YARN/HDFS, standalone, or Mesos. It leverages in-memory computing to be faster than Hadoop MapReduce. Resilient Distributed Datasets (RDDs) are Spark's abstraction for distributed data. RDDs support transformations like map and filter, which are lazily evaluated, and actions like count and collect, which trigger computation. Caching RDDs in memory improves performance of subsequent jobs on the same data.
































































































