




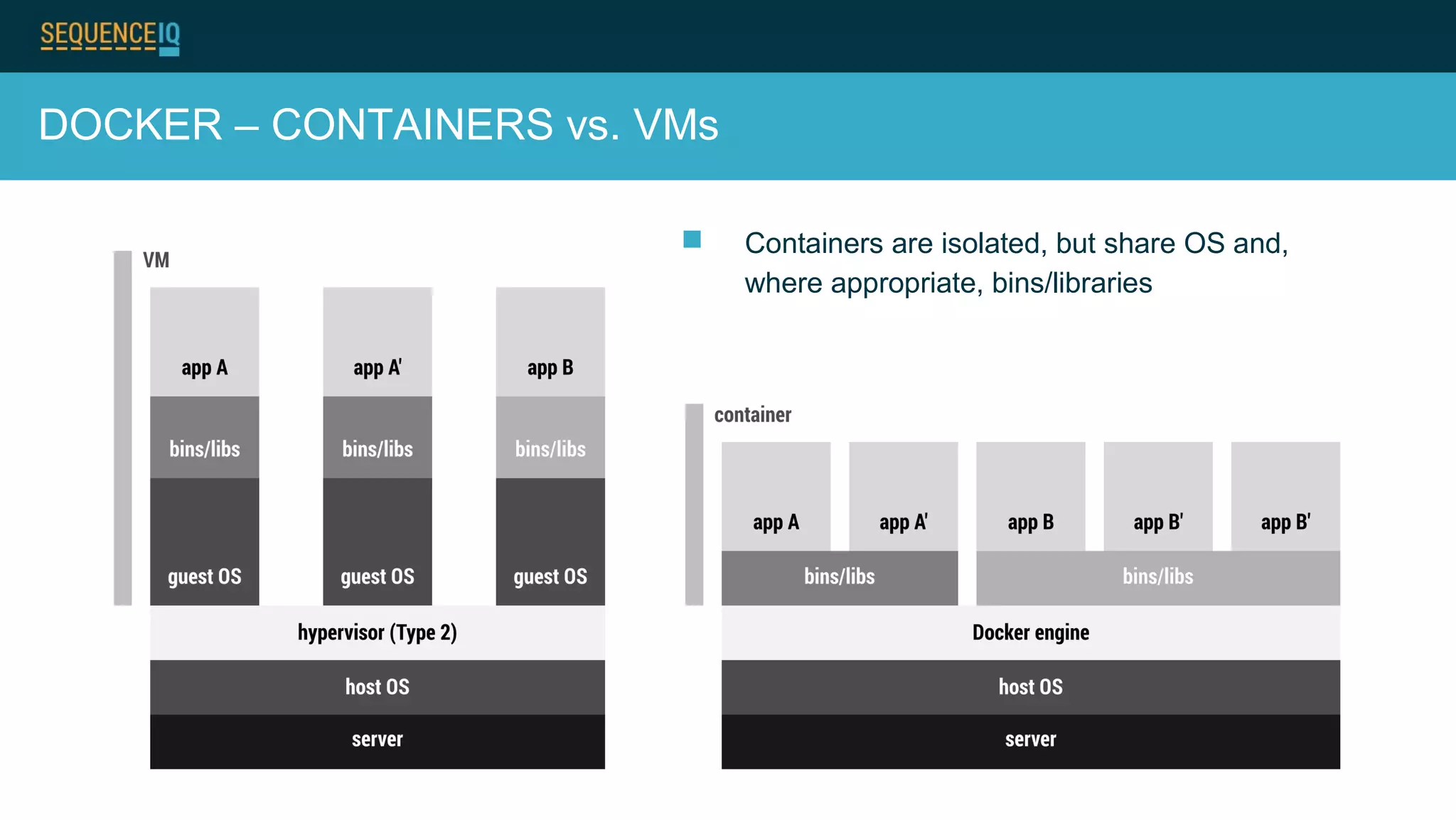
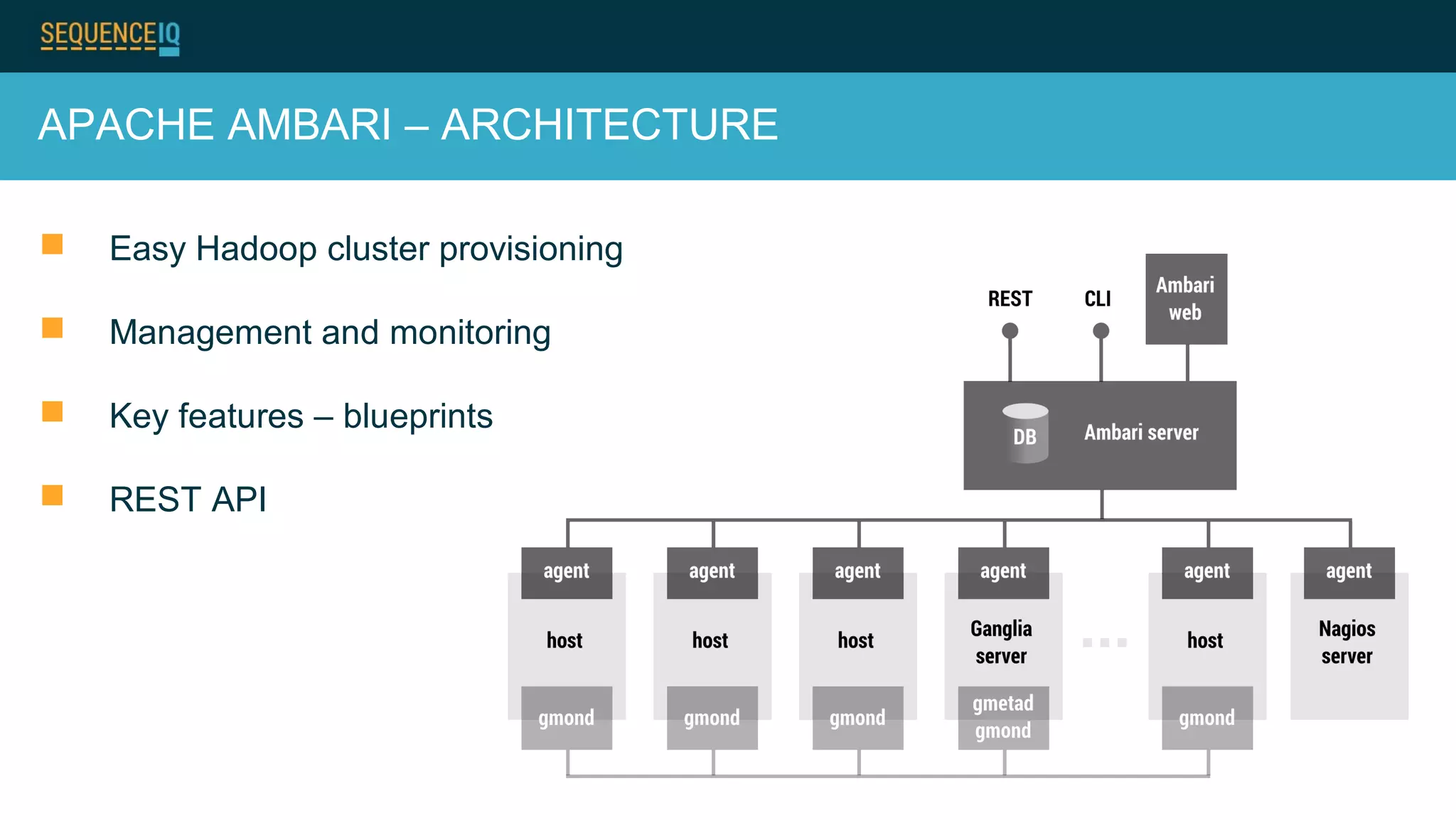
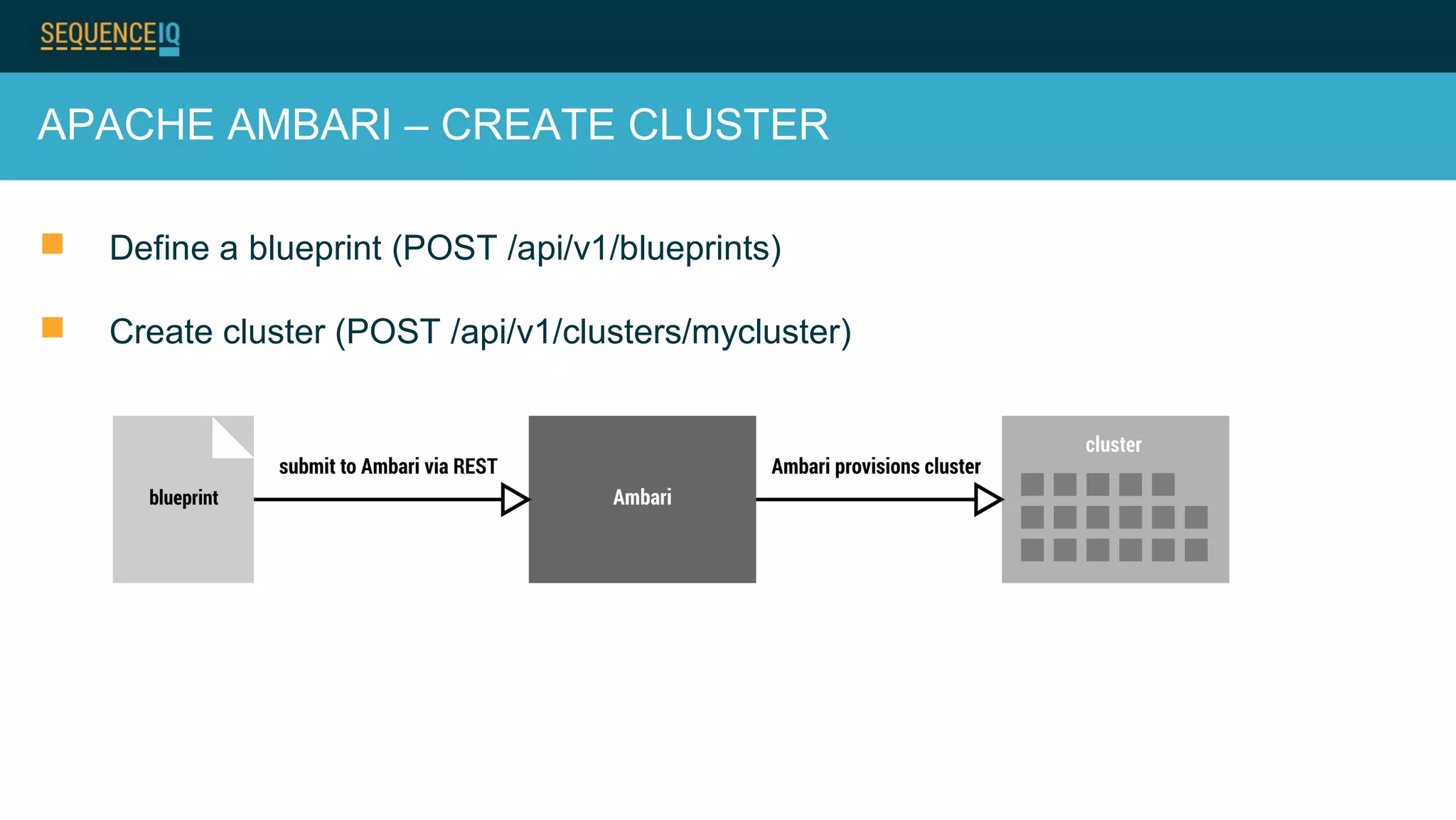




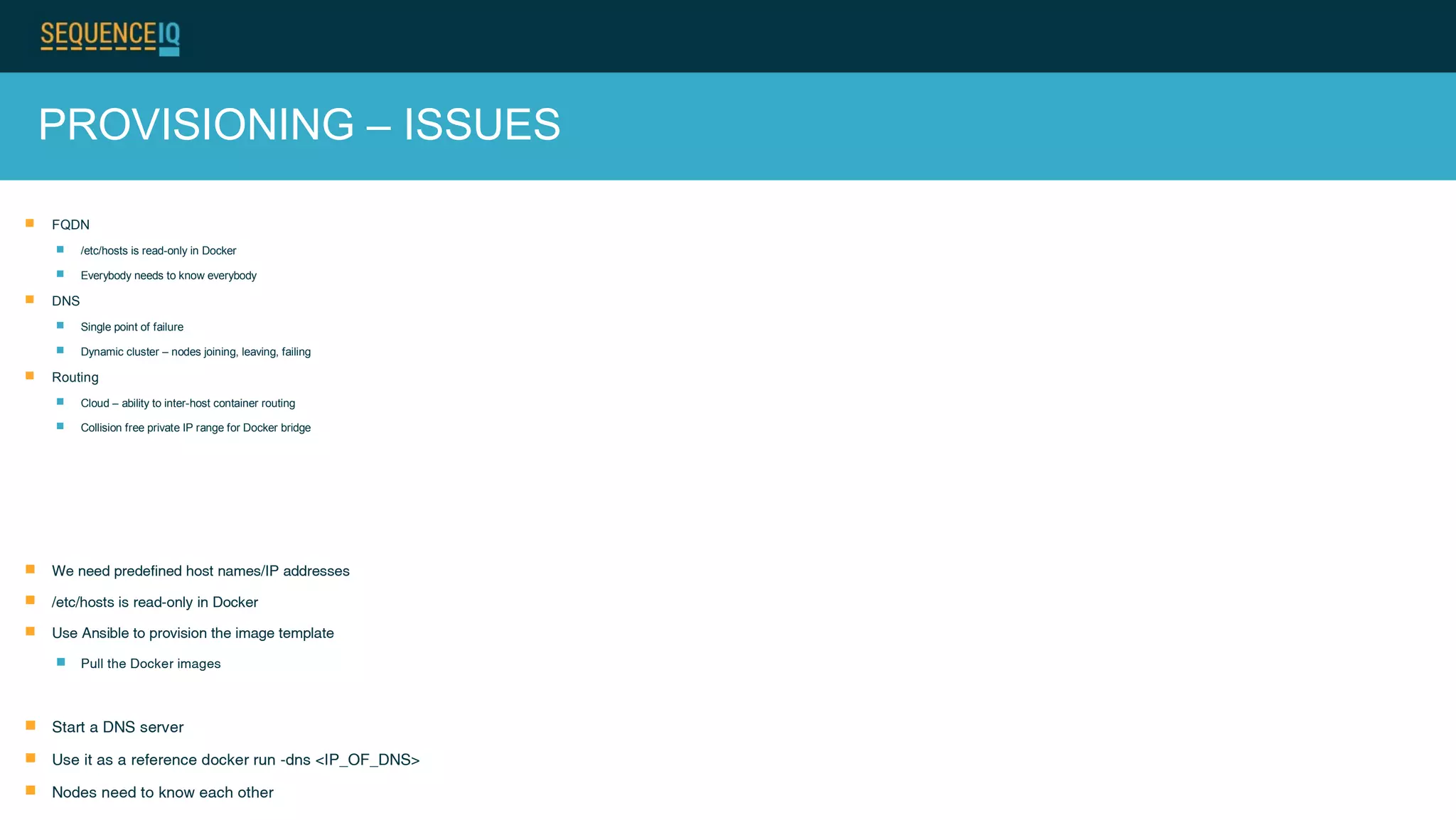



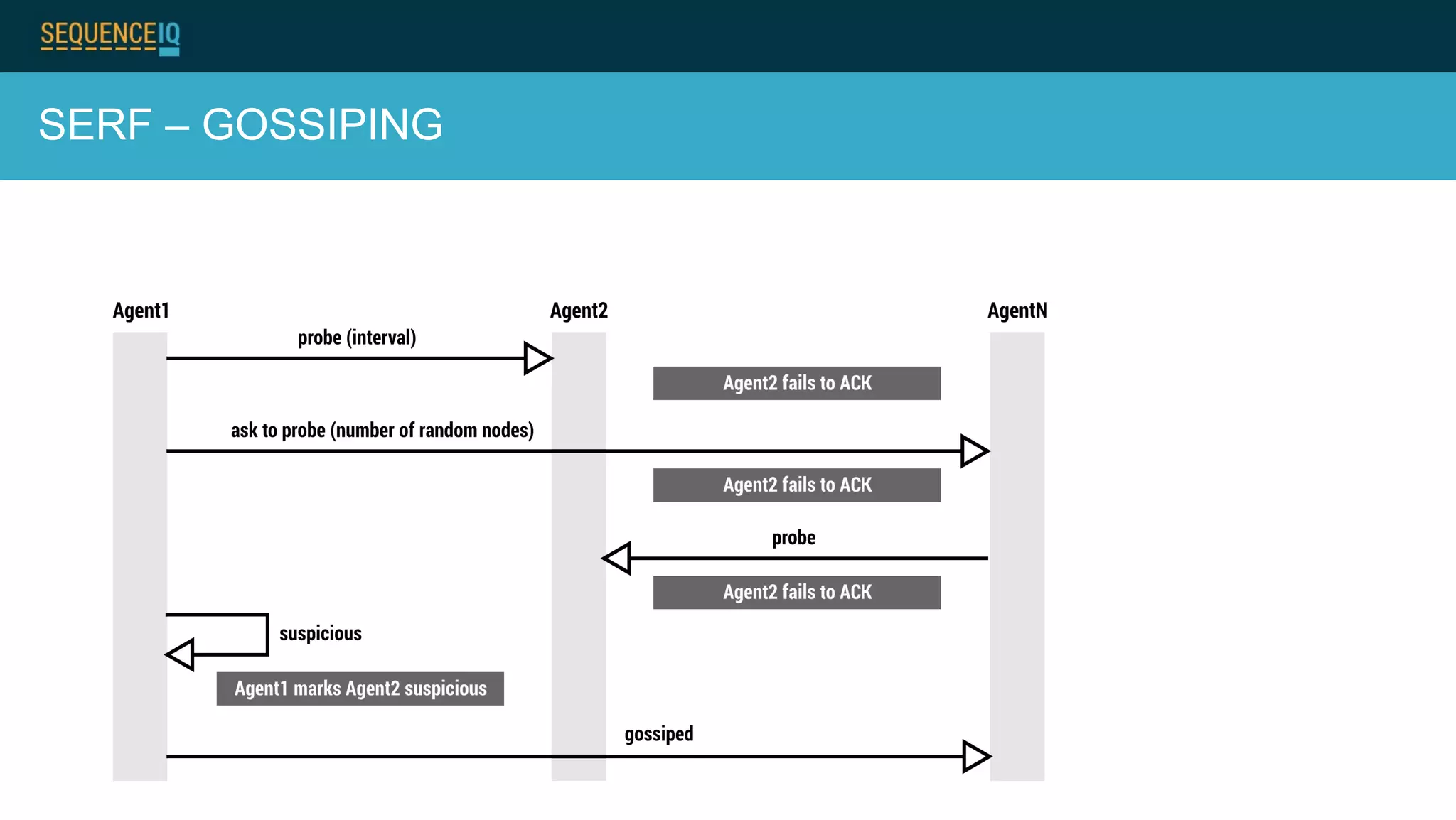
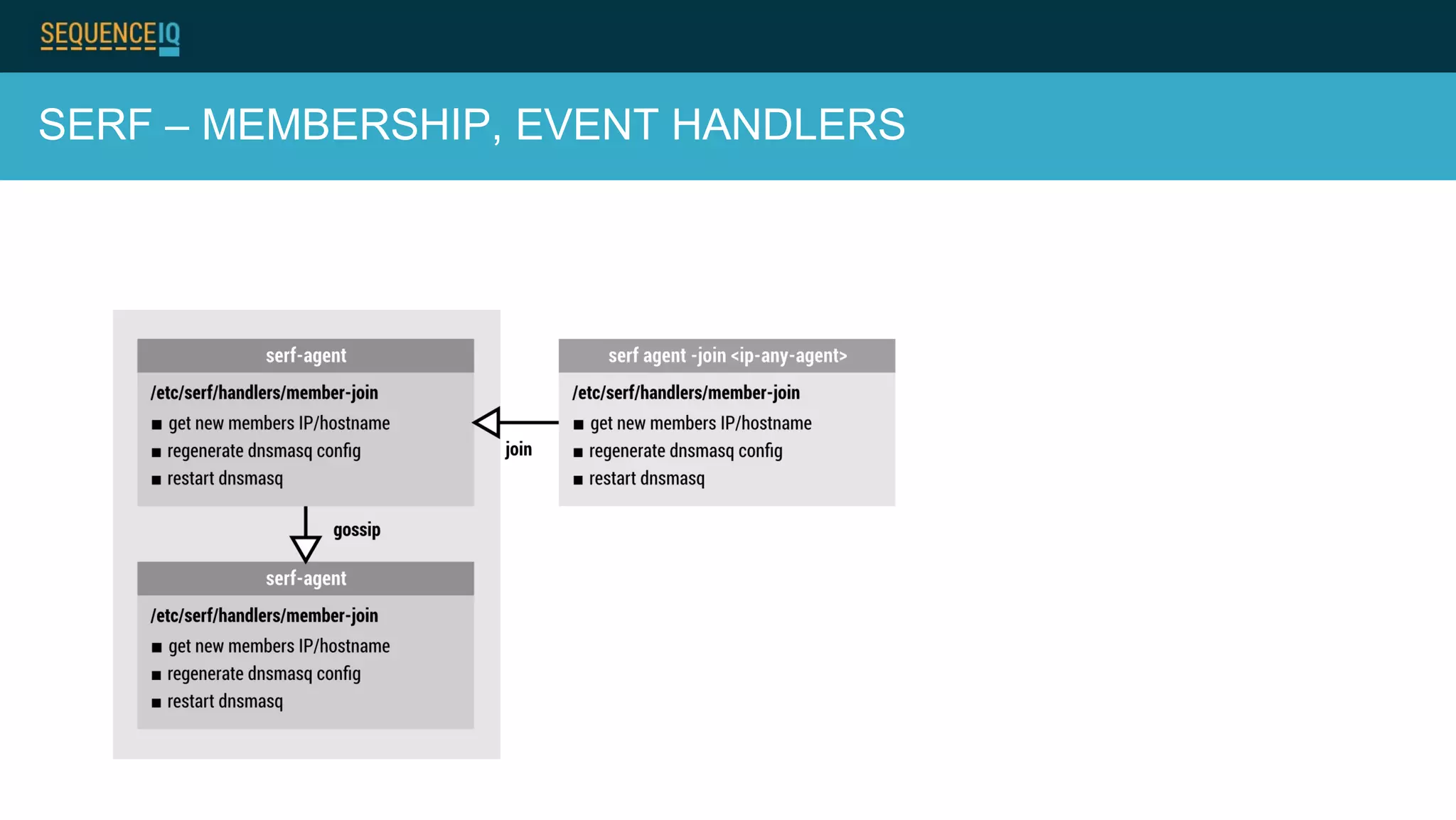


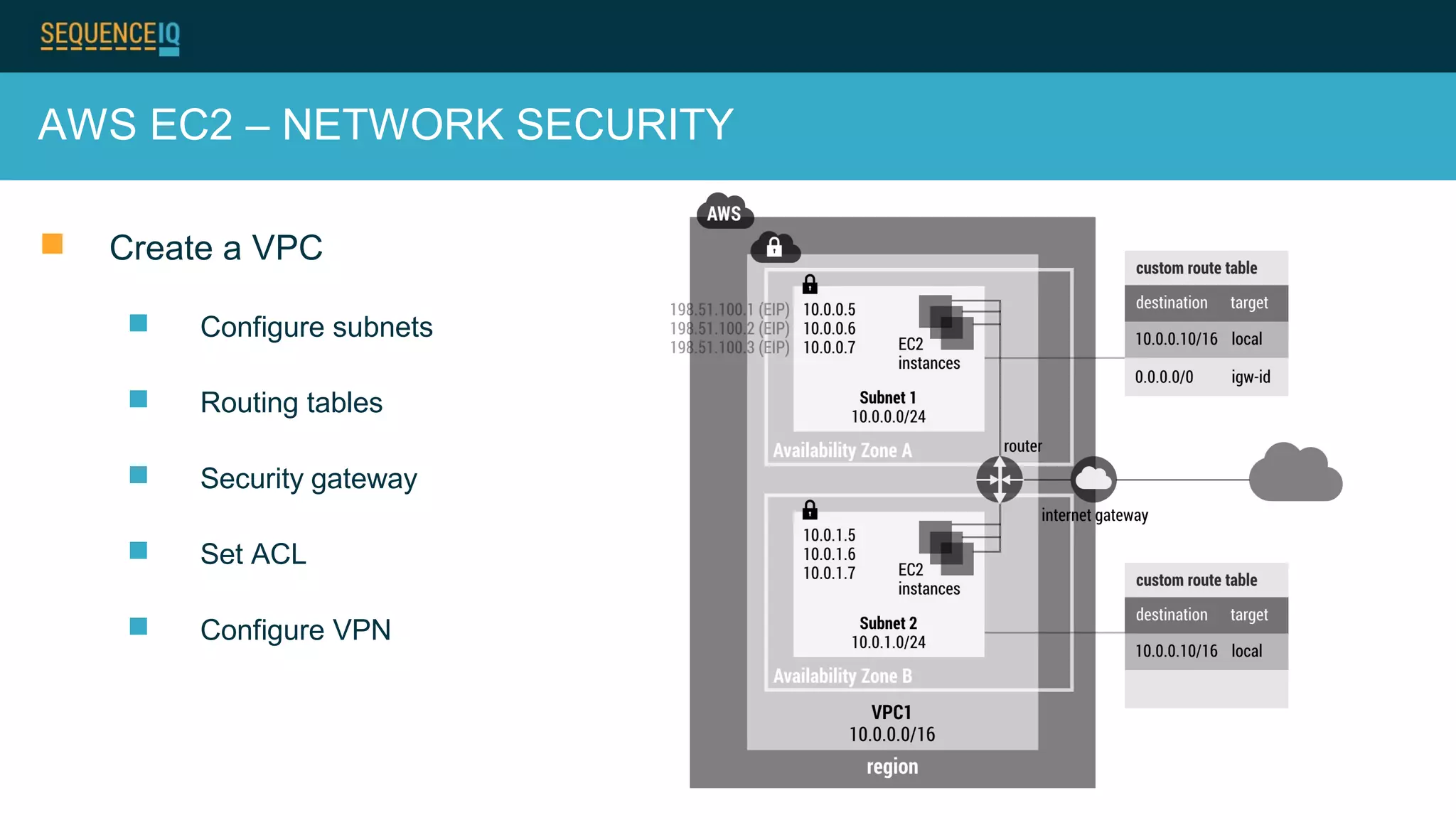








Janos Matyas discusses SequenceIQ's technology for provisioning Hadoop clusters. They use Docker containers and Apache Ambari for easy cluster setup across cloud providers. Key components are building Docker images, using Ansible to provision cloud templates, and running Serf and dnsmasq for service discovery and dynamic cluster membership changes. Their Cloudbreak product provides an API for on-demand Hadoop provisioning on various clouds.





























































![Getting Started with DevOps on AWS [Mar 2020]](https://cdn.slidesharecdn.com/ss_thumbnails/gettingstartedwithdevopsonawsmar2020-240904112851-e692c900-thumbnail.jpg?width=640&height=640&fit=bounds)












































