
Downloaded 11 times









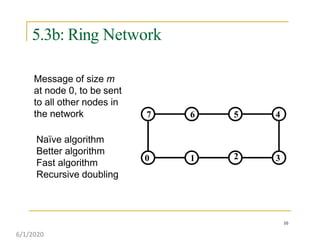
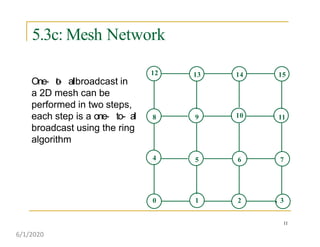



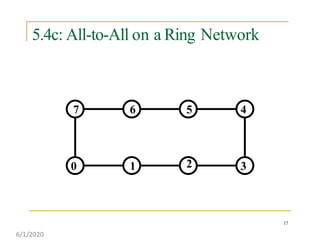

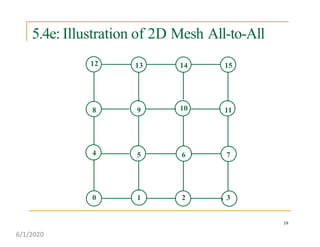

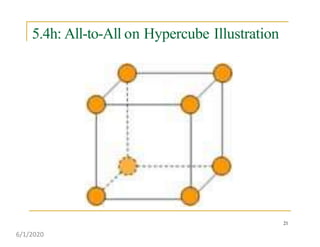



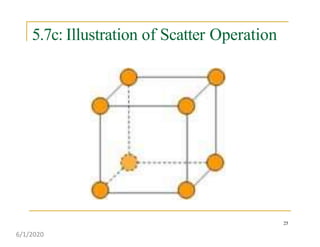



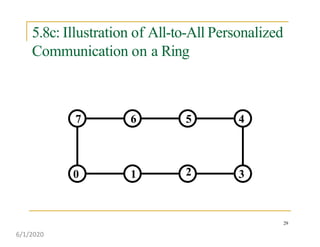
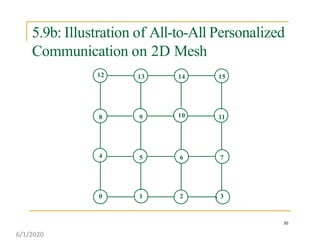


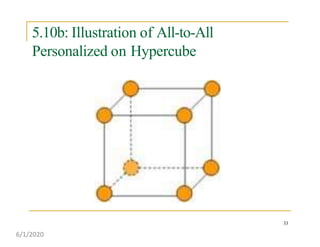

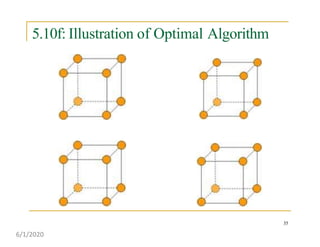
This document discusses various communication operations that are commonly used in parallel and distributed systems, including one-to-one, one-to-all, all-to-all, all-to-one, and personalized communication. It describes how these basic operations can be implemented on different network topologies like rings, meshes, and hypercubes. The communication costs for different operations on these networks are analyzed and illustrated with examples. Optimal algorithms for all-to-all personalized communication on hypercubes are also presented.























































































