Download to read offline



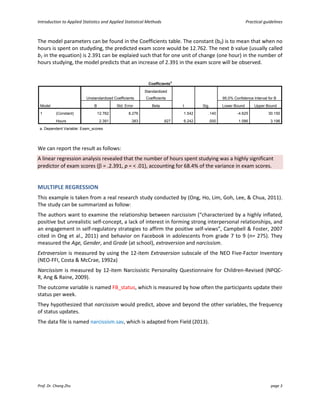


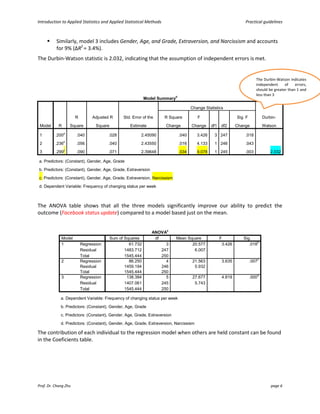
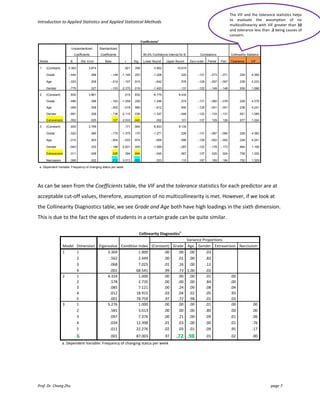
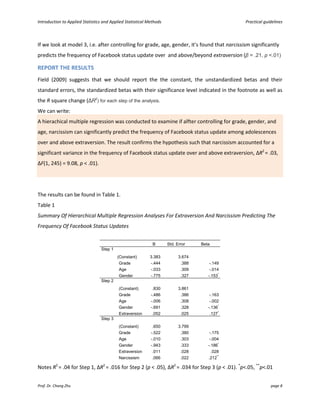
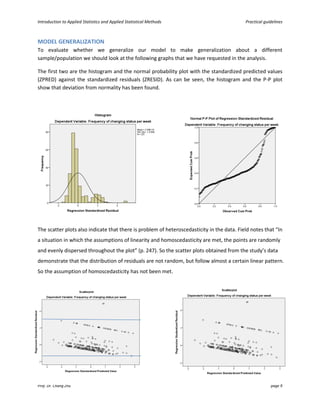
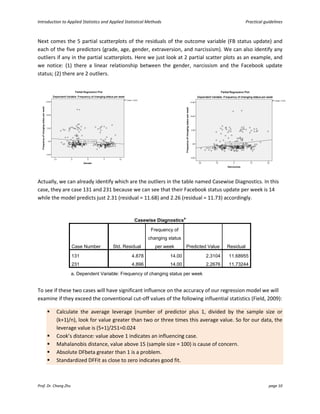
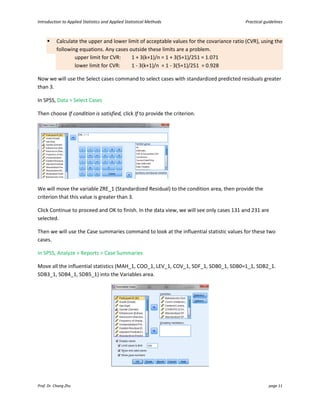
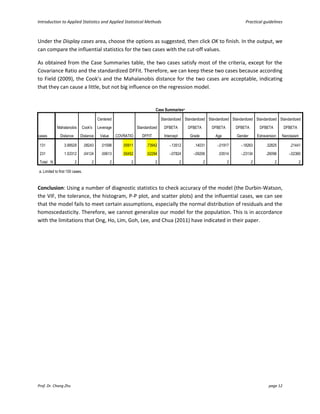


This document provides an introduction and guidelines for linear and multiple regression analyses. It discusses key aspects of each analysis including examining outputs such as model summaries, ANOVA tables, and coefficients. For multiple regression, it recommends a hierarchical approach, entering demographic variables in the first block, extraversion in the second, and narcissism in the third to test if narcissism predicts social media use over and above other factors. The output would show if narcissism explains a significant unique amount of variance in the outcome.



































































