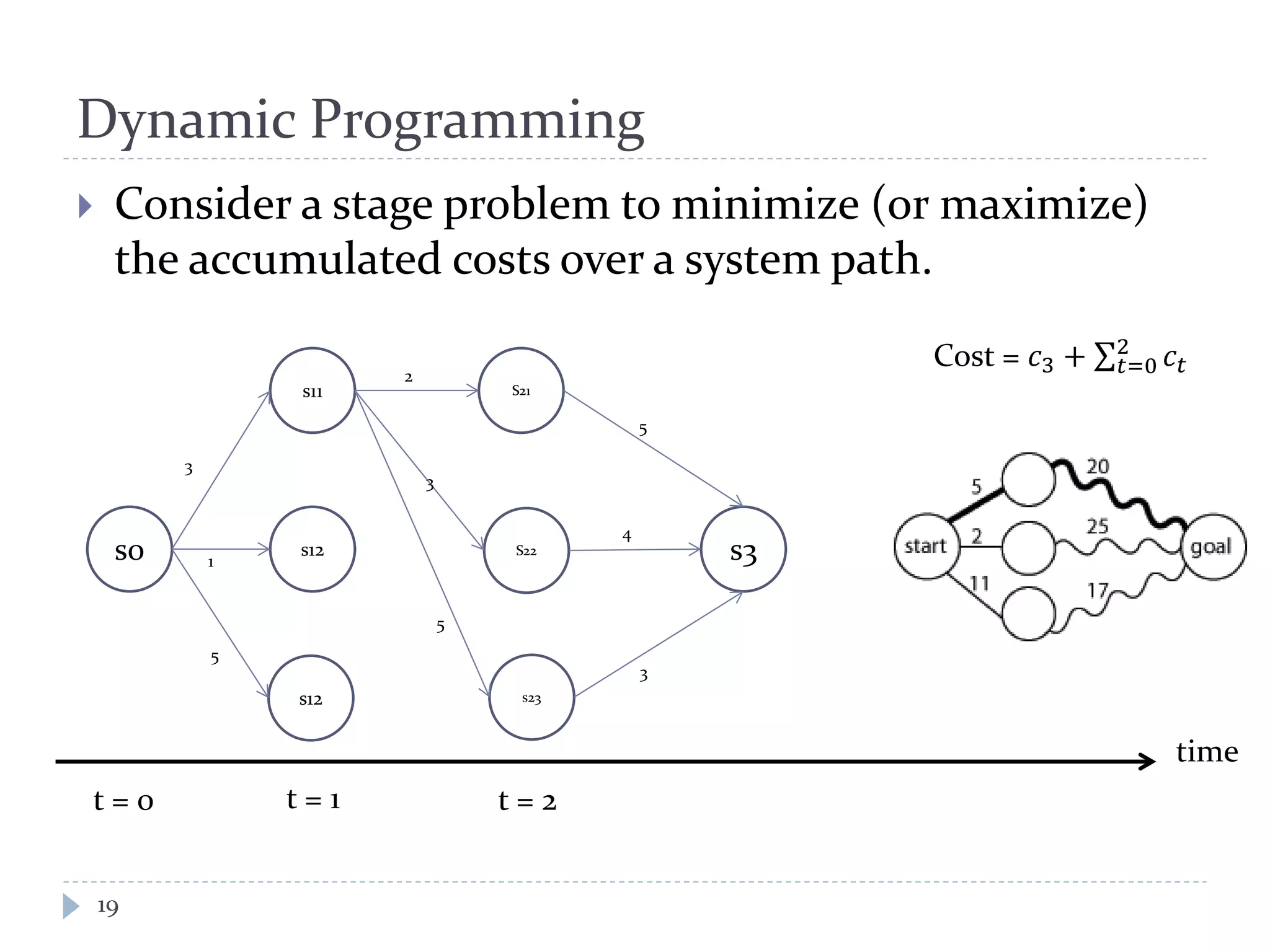
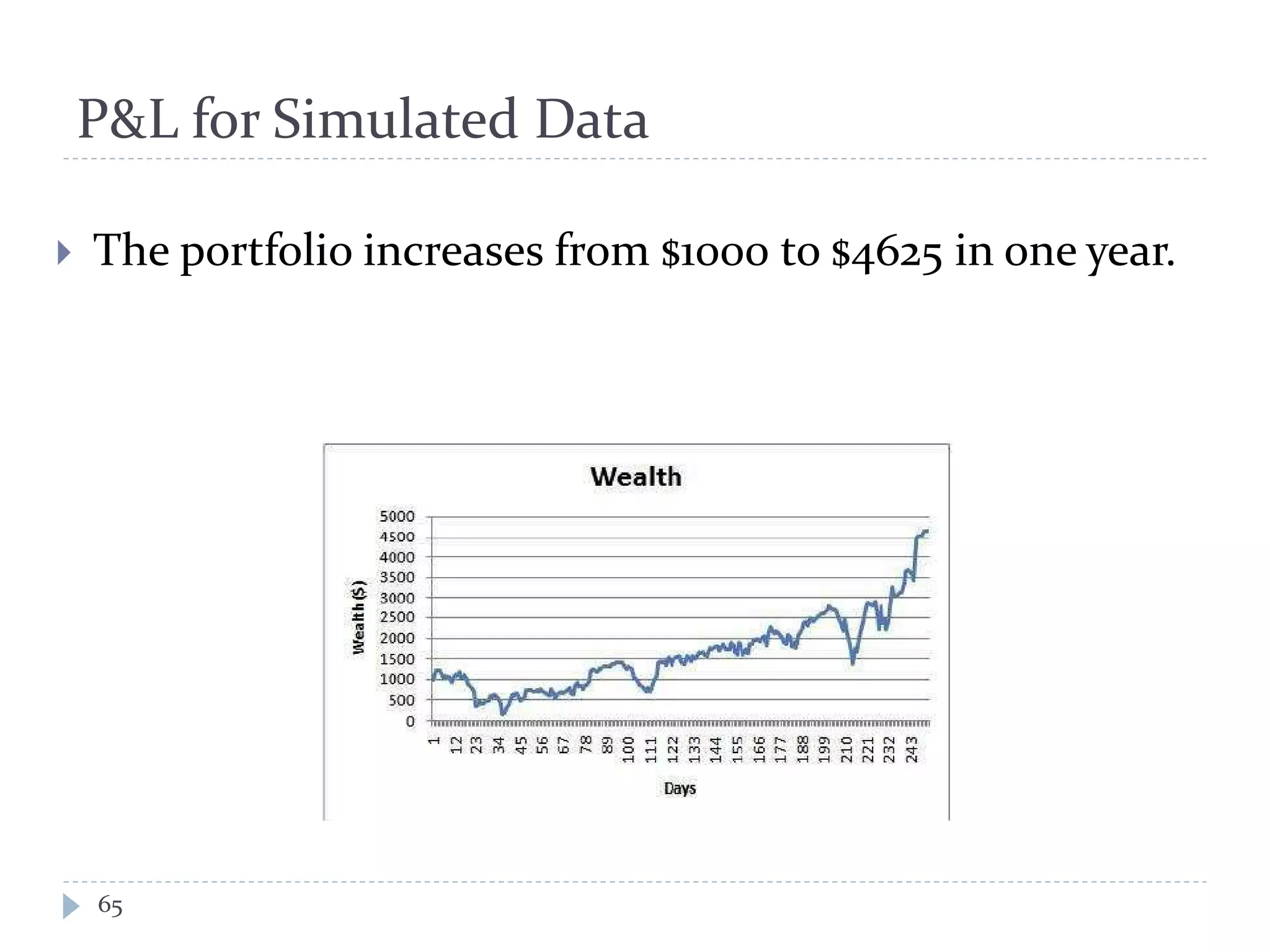
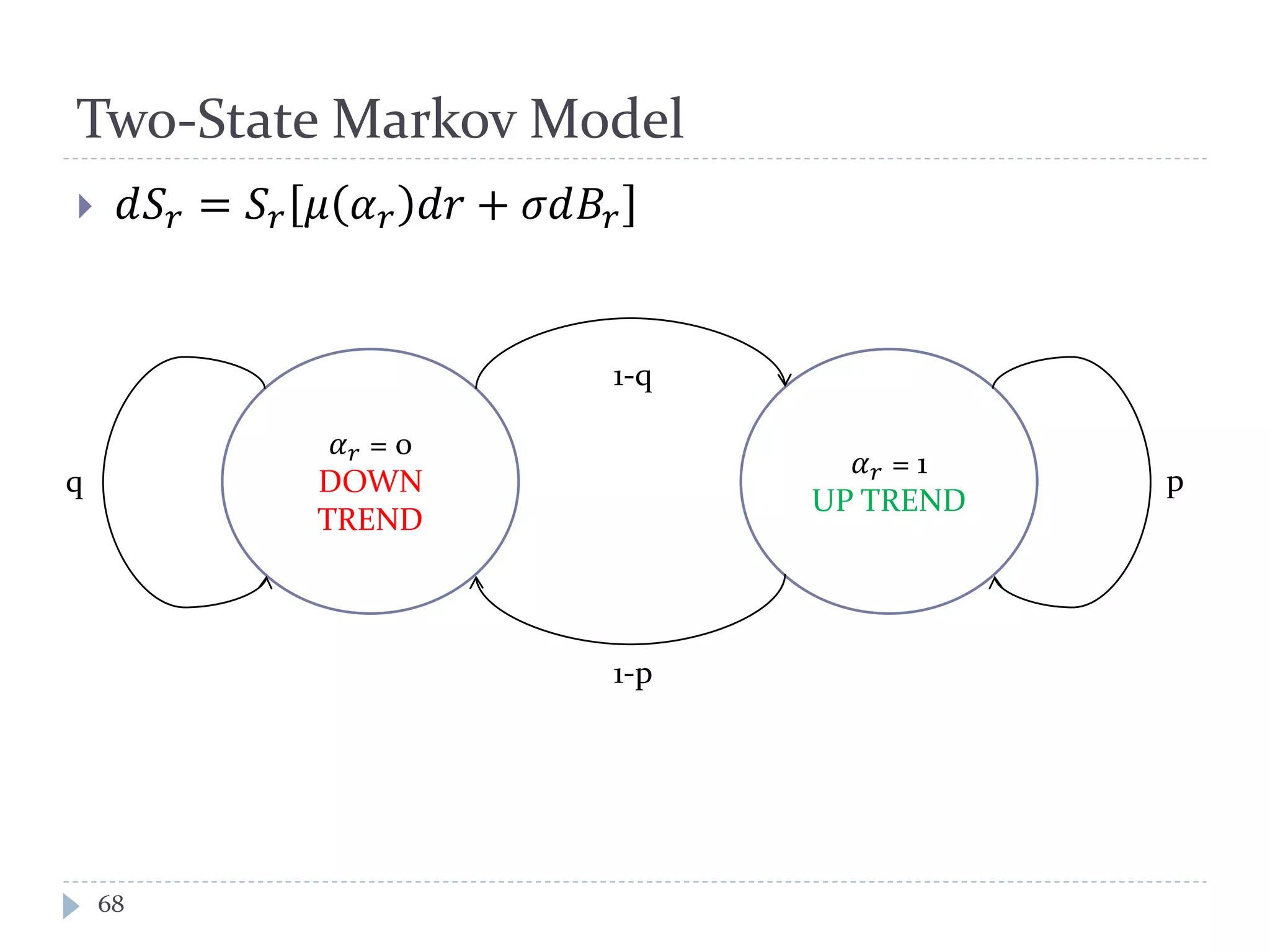
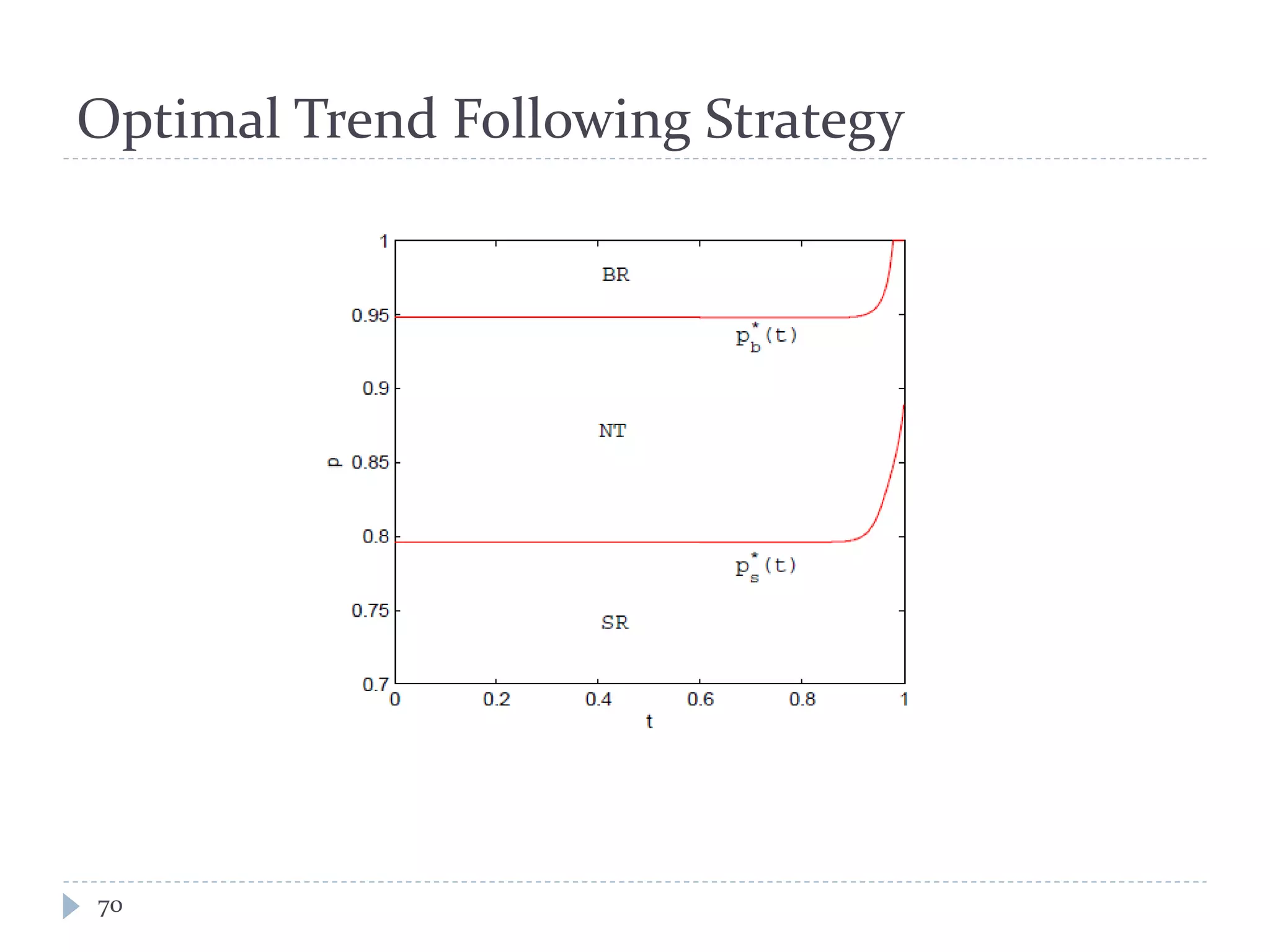
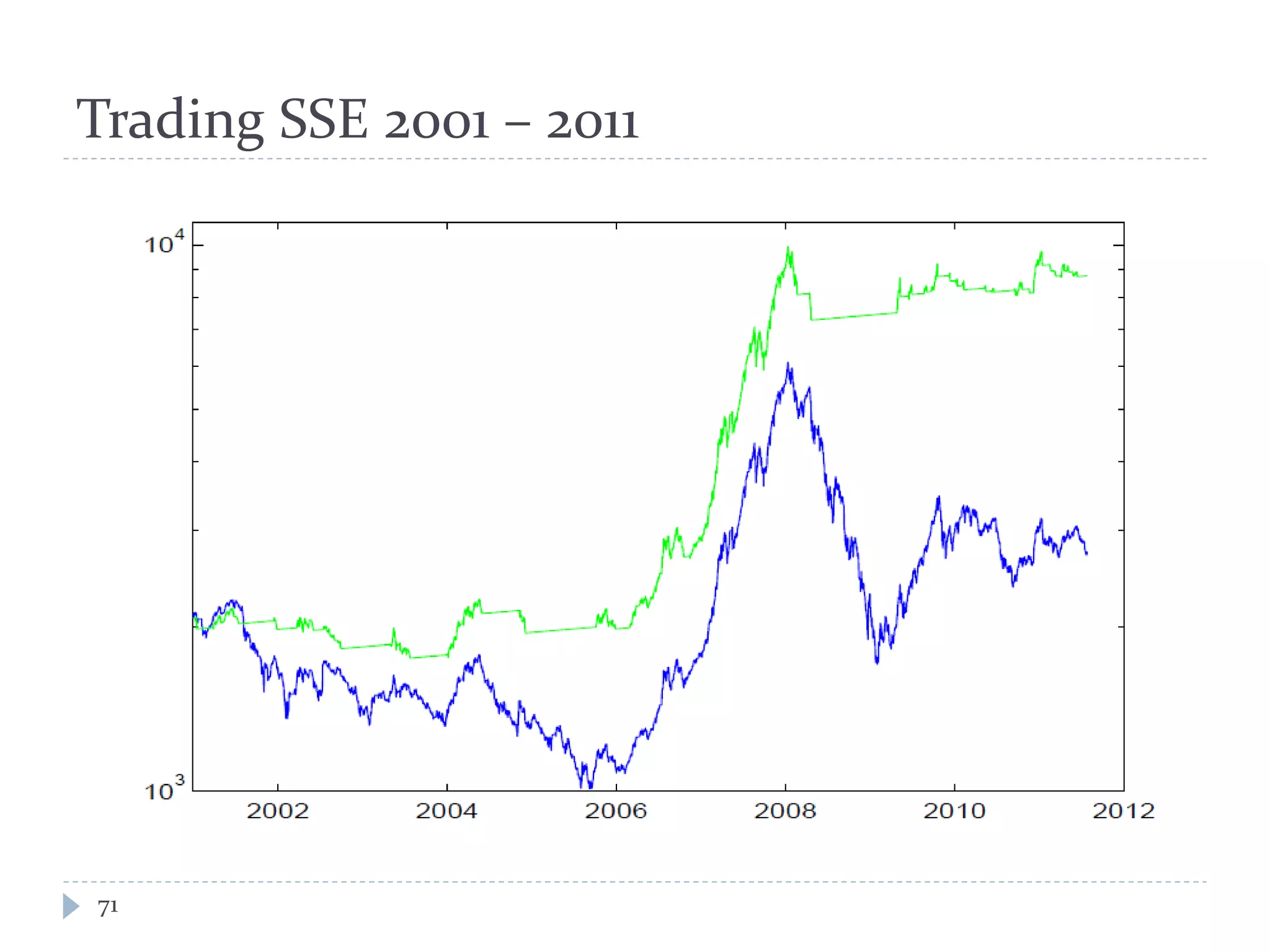
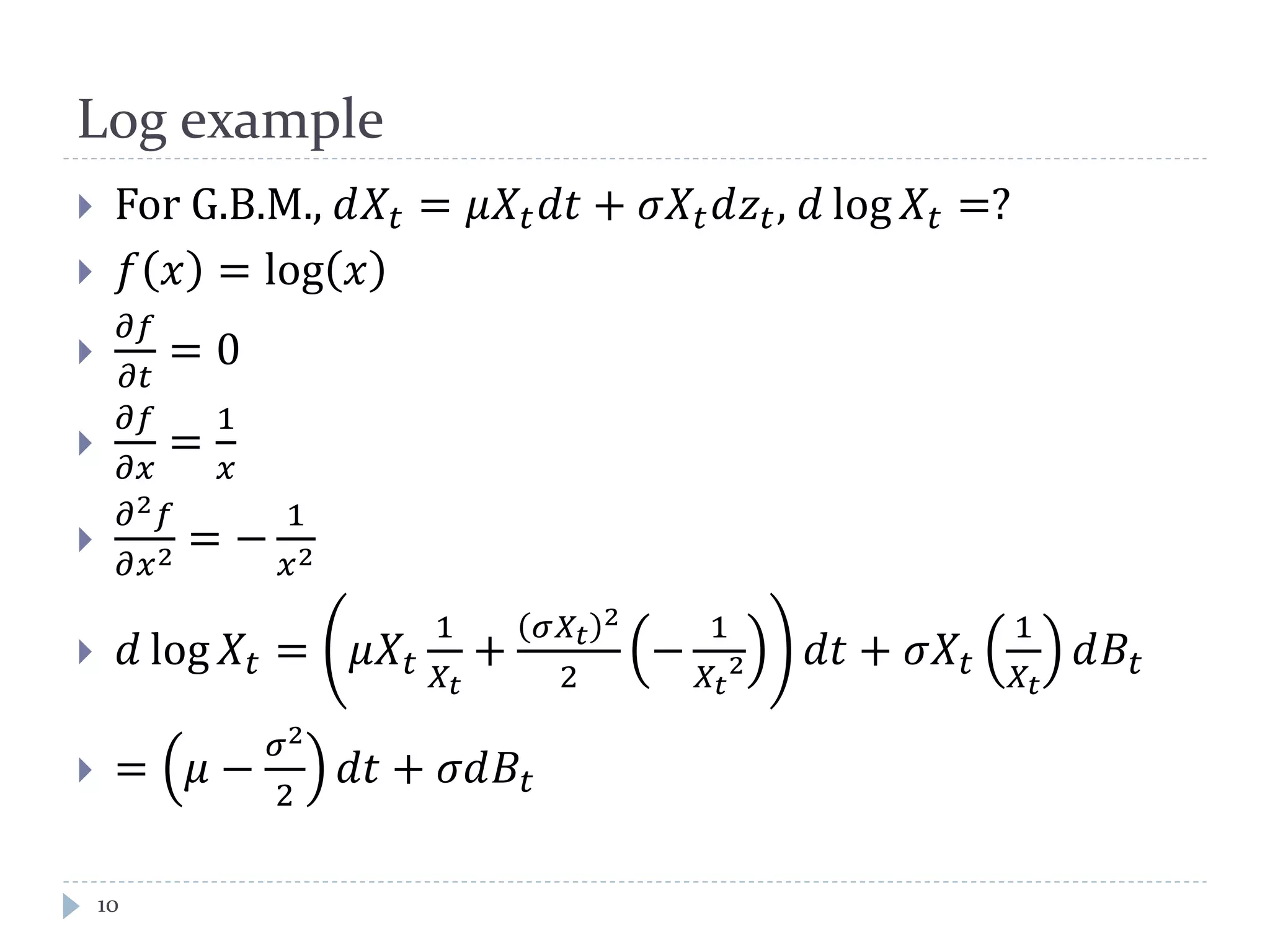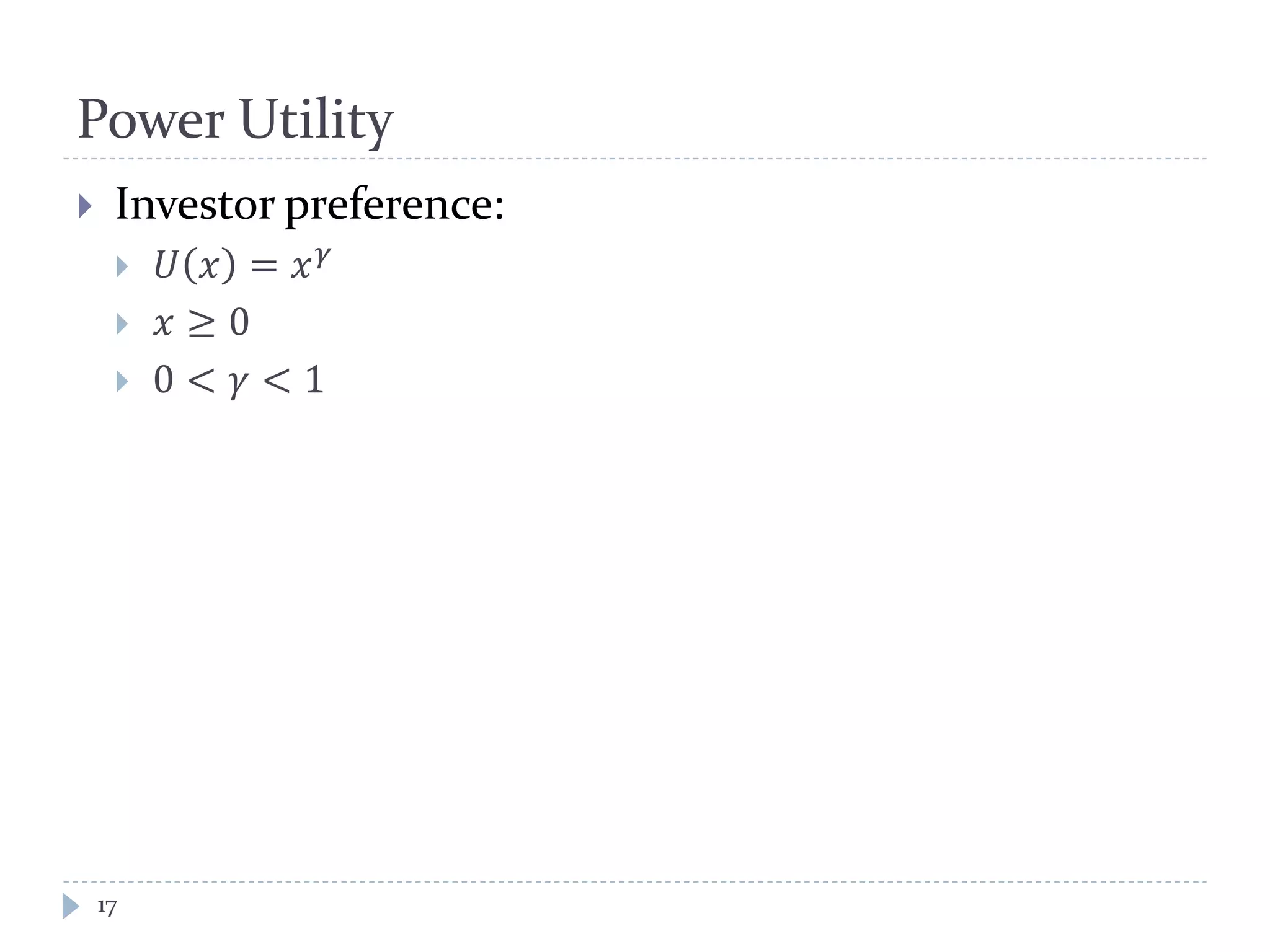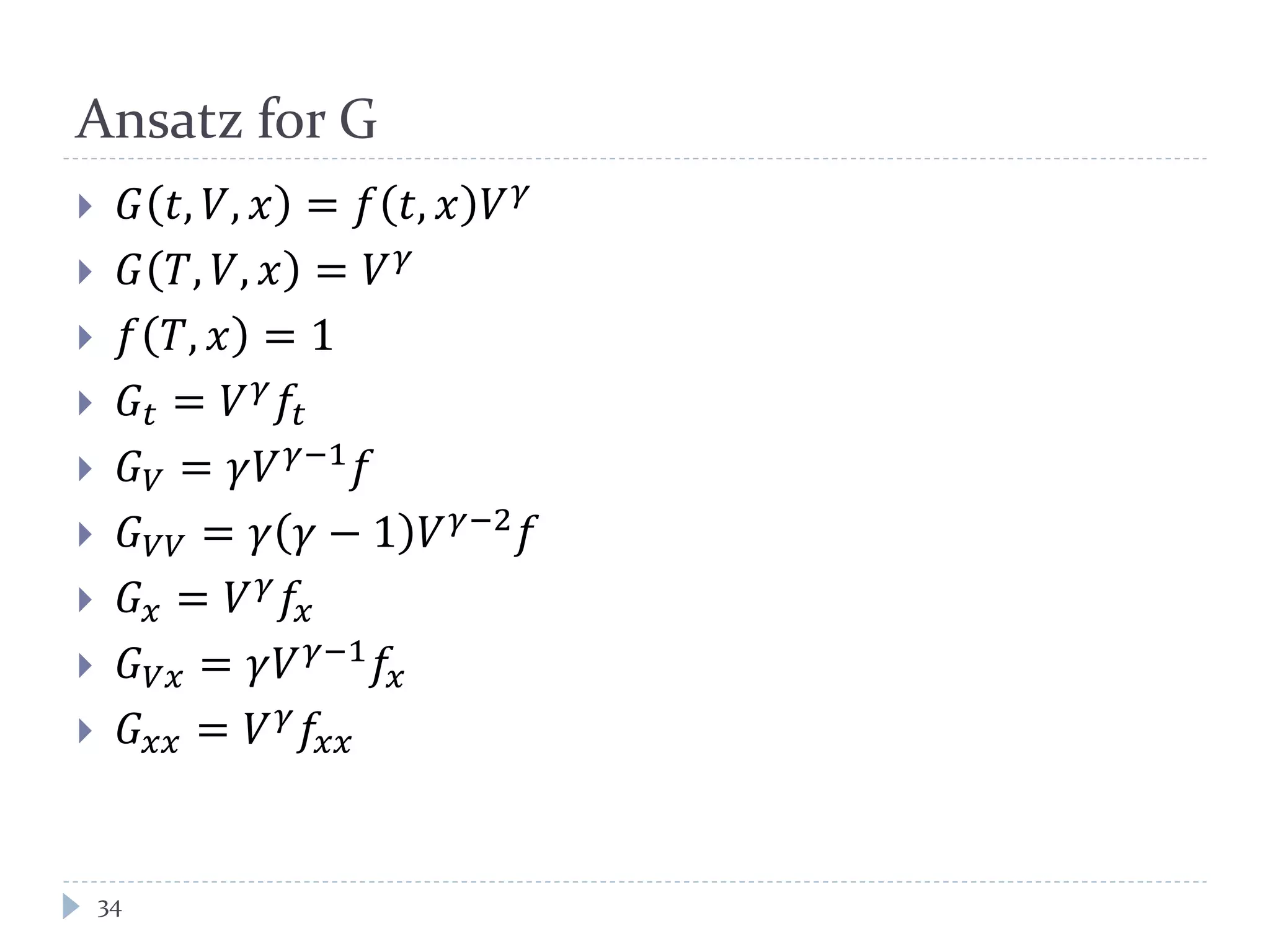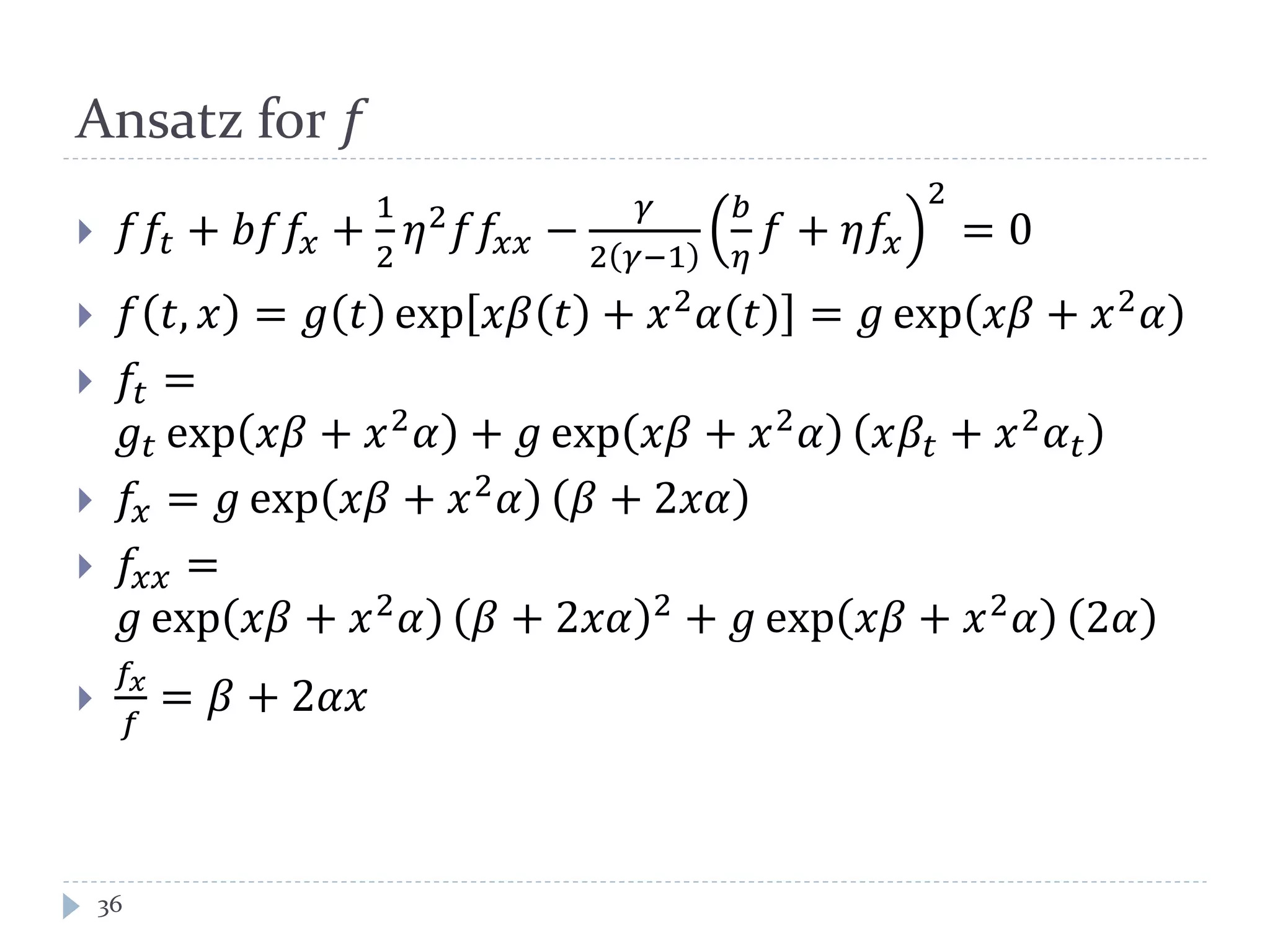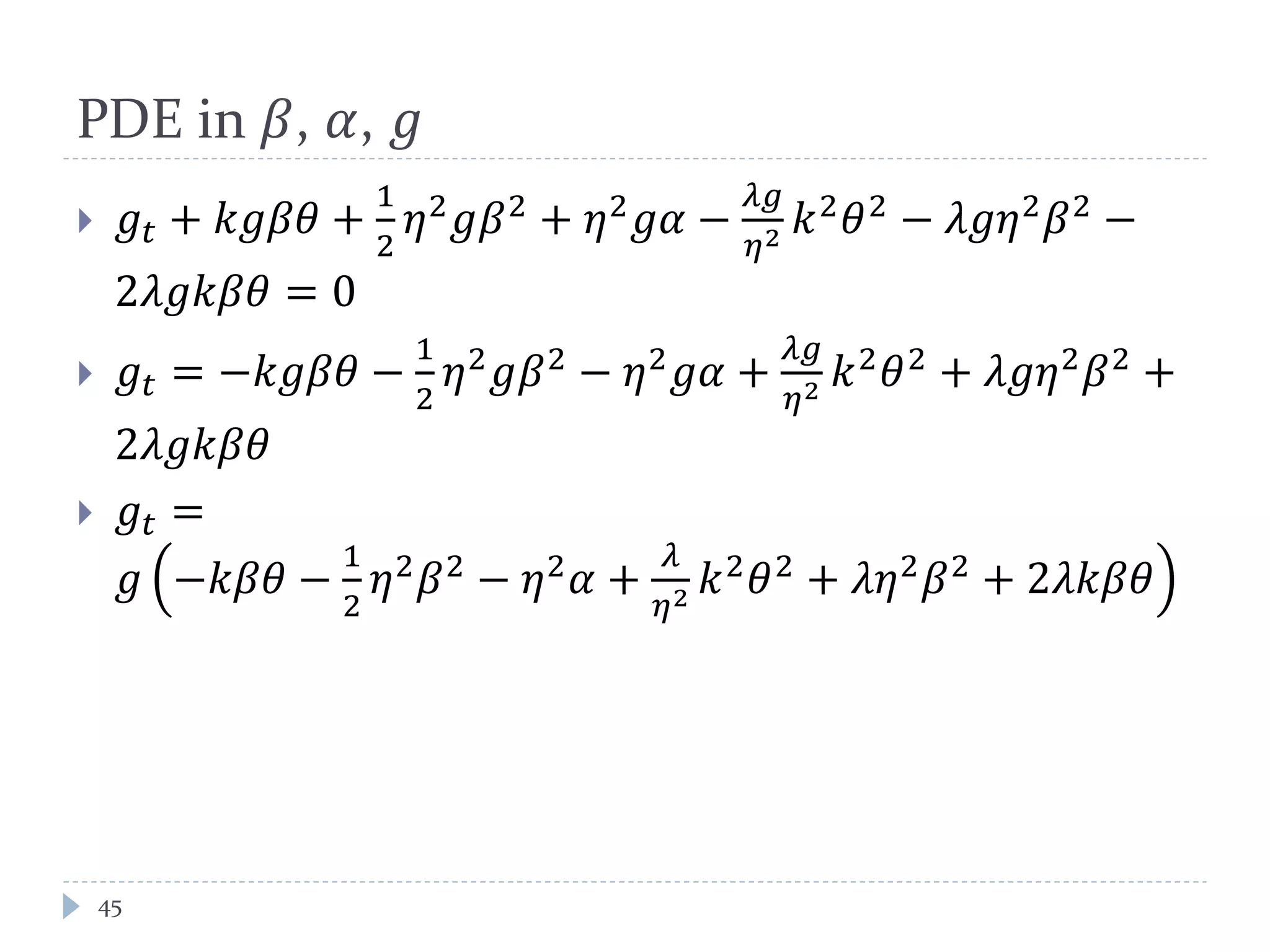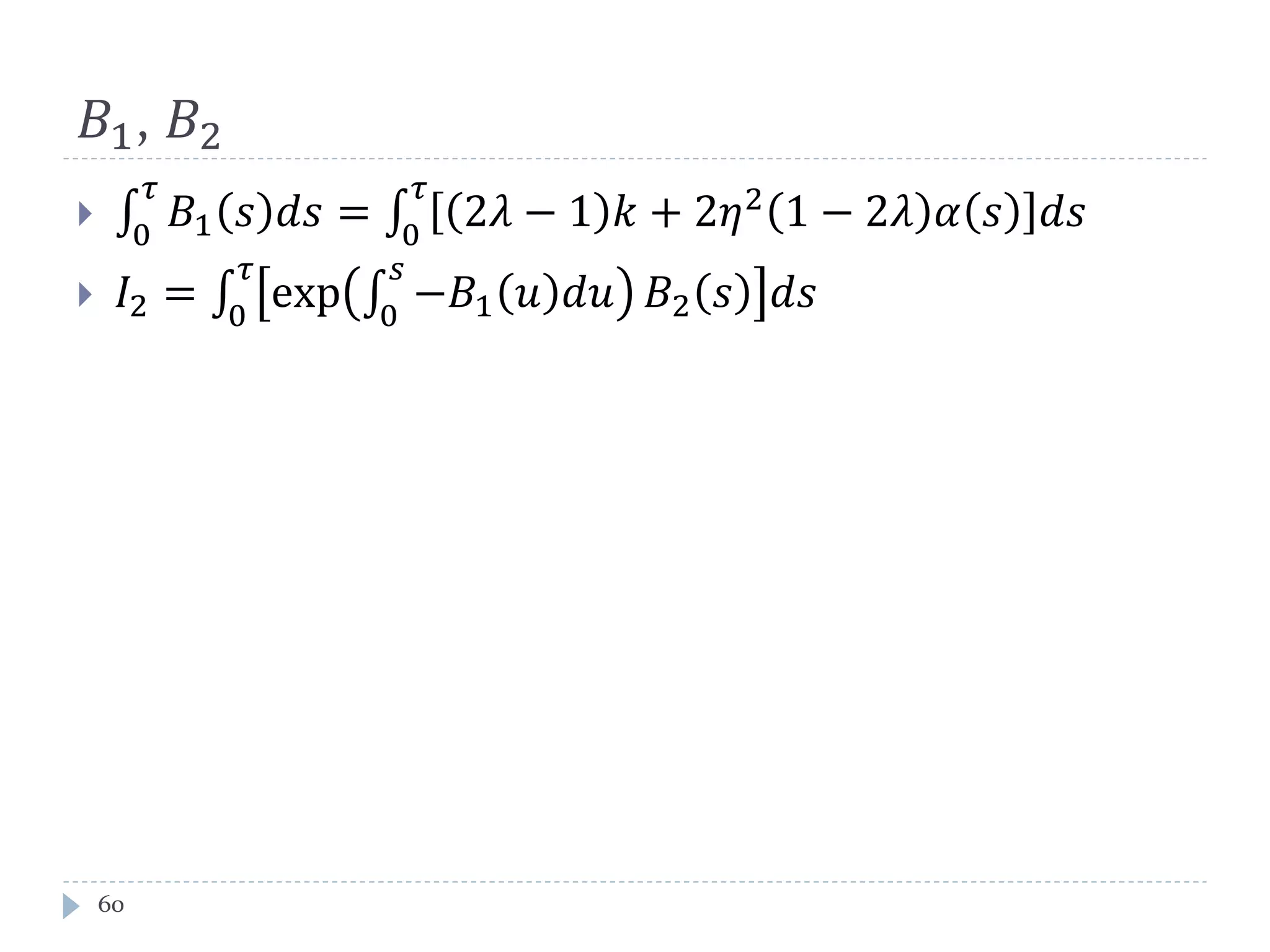This document discusses optimal trading strategies using stochastic control. It provides background on the speaker, Haksun Li, and references related work on optimal pairs trading and trend following rules. It then describes modeling the difference between two asset returns as a mean-reverting Ornstein-Uhlenbeck process. It formulates the optimal trading problem using dynamic programming and stochastic control to maximize expected utility of the trading portfolio value over time.