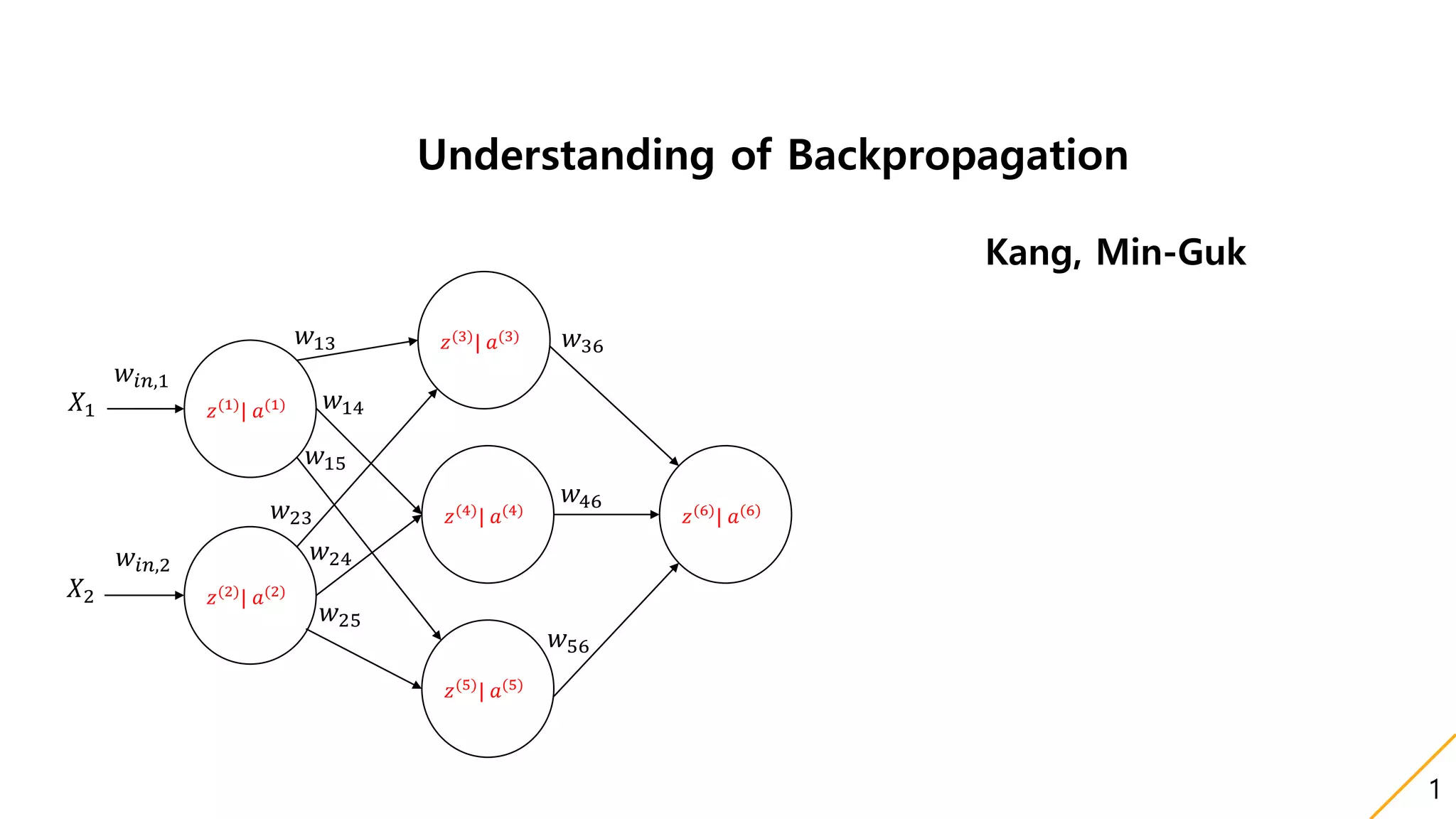
This document discusses backpropagation, an algorithm for supervised learning of artificial neural networks using gradient descent. It provides definitions and history of backpropagation, and explains how to use it with three main points:
1) It uses simple chain rules to calculate derivatives between weights in different layers to update weights.
2) Preparations include defining a cost function and the derivative of the sigmoid activation function commonly used.
3) The weight updates are dependent on derivatives from previous layers, and both forward and backward paths must be considered to calculate some derivatives between weights. Gradient descent is then applied to renew the weights.


![3. Jump to the Backpropagation
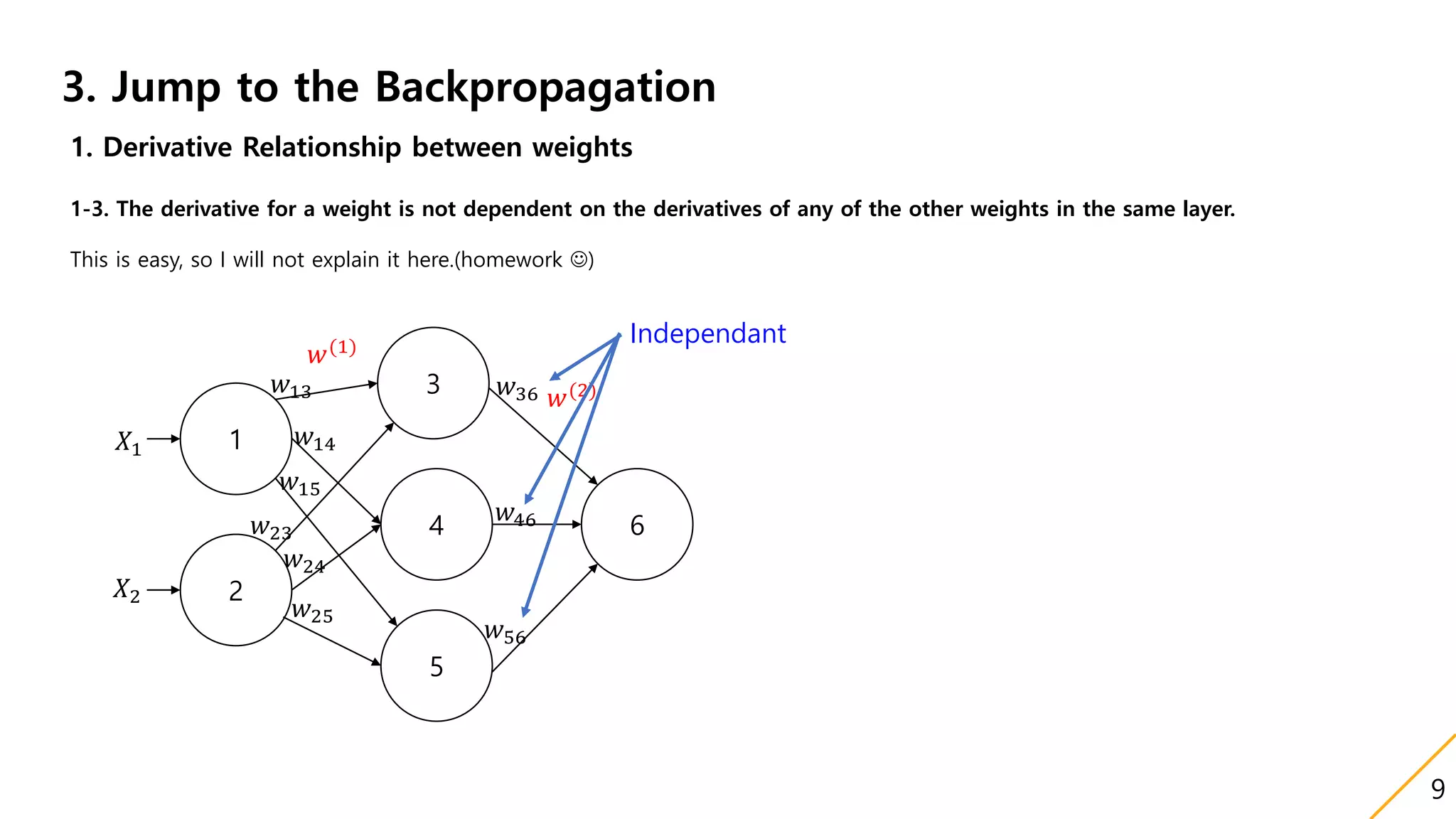
1. Derivative Relationship between weights
1-1. The weight update is dependent on derivatives that reside previous layers.(The Word previous means it is located right side )
𝐶 =
1
2
(𝑦𝑎 − 𝑦𝑡)2
→
𝜕𝐶
𝜕𝑊2,3
= (𝑦𝑎 − 𝑦𝑡) ×
𝜕𝑦 𝑎
𝜕𝑊2,3
= (𝑦𝑎 − 𝑦𝑡) ×
𝜕
𝜕𝑊2,3
[σ{𝑧(3)
}] (σ is sigmoid function)
𝜕𝐶
𝜕𝑊2,3
= (𝑦𝑎 − 𝑦𝑡) ×σ{𝑧(3)
} × [1 − σ{𝑧(3)
}] ×
𝜕𝑍3
𝜕𝑊2,3
= (𝑦𝑎 − 𝑦𝑡) ×σ{𝑧(3)
} × [1 − σ{𝑧(3)
}] ×
𝜕
𝜕𝑊2,3
( 𝑎(2)
𝑤2,3)
∴
𝜕𝐶
𝜕𝑊2,3
= (𝑦𝑎 − 𝑦𝑡)σ{𝑧(3)
}[1 − σ{𝑧(3)
}] 𝑎(2)
1𝑋𝑖𝑛 2 3
𝑤1,2 𝑤2,3
𝑤𝑖𝑛,1
𝑧(2)
| 𝑎(2)
𝑧(1)
| 𝑎(1)
𝑧(3)
| 𝑎(3)
𝑎(3)
= 𝑦𝑎
Feed forward
Backpropagation
4](https://image.slidesharecdn.com/backpropagation-180102061746/75/Backpropagation-4-2048.jpg)
![3. Jump to the Backpropagation
1. Derivative Relationship between weights
1-1. The weight update is dependent on derivatives that reside previous layers.(The Word previous means it is located right side )
𝐶 =
1
2
(𝑦𝑎 − 𝑦𝑡)2
→
𝜕𝐶
𝜕𝑊1,2
= (𝑦𝑎 − 𝑦𝑡) ×
𝜕𝑦 𝑎
𝜕𝑊1,2
= (𝑦𝑎 − 𝑦𝑡) ×
𝜕
𝜕𝑊1,2
[σ{𝑧(3)
}] (σ is sigmoid function)
𝜕𝐶
𝜕𝑊1,2
= (𝑦𝑎 − 𝑦𝑡) ×σ{𝑧(3)
} × [1 − σ{𝑧(3)
}] ×
𝜕𝑍3
𝜕𝑊1,2
= (𝑦𝑎 − 𝑦𝑡) ×σ{𝑧(3)
} × [1 − σ{𝑧(3)
}] ×
𝜕
𝜕𝑊1,2
( 𝑎(2)
𝑤2,3)
𝜕𝐶
𝜕𝑊1,2
= (𝑦𝑎 − 𝑦𝑡) ×σ{𝑧(3)
} × [1 − σ{𝑧(3)
}] × 𝑤2,3 ×
𝜕
𝜕𝑊1,2
𝑎(2)
= (𝑦𝑎 − 𝑦𝑡) ×σ{𝑧(3)
} × [1 − σ{𝑧(3)
}] × 𝑤2,3 ×
𝜕
𝜕𝑊1,2
σ{𝑧(2)
}
∴
𝜕𝐶
𝜕𝑊1,2
= (𝑦𝑎 − 𝑦𝑡)σ{𝑧(3)
}[1 − σ{𝑧(3)
}] 𝑤2,3 σ{𝑧(2)
}[1 − σ{𝑧(2)
} ] 𝑎(1)
1𝑋𝑖𝑛 2 3
𝑤1,2 𝑤2,3
𝑤𝑖𝑛,1
𝑧(2)
| 𝑎(2)
𝑧(1)
| 𝑎(1)
𝑧(3)
| 𝑎(3)
𝑎(3)
= 𝑦𝑎
Feed forward
Backpropagation
5](https://image.slidesharecdn.com/backpropagation-180102061746/75/Backpropagation-5-2048.jpg)
![3. Jump to the Backpropagation
1. Derivative Relationship between weights
1-1. The weight update is dependent on derivatives that reside previous layers.(The Word previous means it is located right side )
𝐶 =
1
2
(𝑦𝑎 − 𝑦𝑡)2
→
𝜕𝐶
𝜕𝑊 𝑖𝑛,1
= (𝑦𝑎 − 𝑦𝑡) ×
𝜕𝑦 𝑎
𝜕𝑊 𝑖𝑛,1
= (𝑦𝑎 − 𝑦𝑡) ×
𝜕
𝜕𝑊 𝑖𝑛,1
[σ{𝑧(3)
}] (σ is sigmoid function)
Using same way, we will get below equation.
𝜕𝐶
𝜕𝑊 𝑖𝑛,1
= (𝑦𝑎 − 𝑦𝑡)σ{𝑧(3)
}[1 − σ{𝑧(3)
}] 𝑤2,3 σ{𝑧(2)
}[1 − σ{𝑧(2)
} ] 𝑤1,2 σ{𝑧(1)
}[1 − σ{𝑧(1)
} ] 𝑋𝑖𝑛
1𝑋𝑖𝑛 2 3
𝑤1,2 𝑤2,3
𝑤𝑖𝑛,1
𝑧(2)
| 𝑎(2)
𝑧(1)
| 𝑎(1)
𝑧(3)
| 𝑎(3)
𝑎(3)
= 𝑦𝑎
Feed forward
Backpropagation
6](https://image.slidesharecdn.com/backpropagation-180102061746/75/Backpropagation-6-2048.jpg)
![3. Jump to the Backpropagation
1. Derivative Relationship between weights
1-2. The weight update is dependent on derivatives that reside on both paths.
To get the result, you have to do more tedious calculations than the previous one. So I now just write the result of it.
If you want to know the calculation process, look at the next slide!
𝜕𝐶
𝜕𝑊 𝑖𝑛,1
= (𝑦𝑎 − 𝑦𝑡) 𝑋𝑖𝑛[ σ{𝑧(2)
}[1 − σ{𝑧(2)
}]𝑤2,4 σ{𝑧(1)
}[1 − σ{𝑧(1)
}] 𝑤1,2 + σ{𝑧(3)
}[1 − σ{𝑧(3)
}]𝑤3,4 σ{𝑧(1)
}[1 − σ{𝑧(1)
}]𝑤1,3]
① ② ③ ④
2
3
𝑋𝑖𝑛 1
𝑤𝑖𝑛,1
4 𝑎(3) = 𝑦𝑎
Feed forward
𝑧(4)
| 𝑎(4)
𝑧(3)
| 𝑎(3)
𝑧(1)| 𝑎(1)
𝑤1,2 𝑤2,4
𝑤3,4𝑤1,3
𝑧(2)
| 𝑎(2)
①②
③④
7](https://image.slidesharecdn.com/backpropagation-180102061746/75/Backpropagation-7-2048.jpg)
![2
3
𝑋𝑖𝑛 1
𝑤𝑖𝑛,1
4 𝑎(3)
= 𝑦𝑎
Feed forward
𝑧(4)
| 𝑎(4)
𝑧(3)
| 𝑎(3)
𝑧(1)
| 𝑎(1)
𝑤1,2 𝑤2,4
𝑤3,4𝑤1,3
𝑧(2)
| 𝑎(2)
𝜕𝐶
𝜕𝑊 𝑖𝑛,1
=
𝜕
𝜕𝑊 𝑖𝑛,1
1
2
(𝑦𝑎 − 𝑦𝑡)2
= 𝑦𝑎 − 𝑦𝑡 (
𝜕
𝜕𝑊 𝑖𝑛,1
(σ{𝑧 2
}𝑤2,4 + σ{𝑧 3
}𝑤3,4))
𝜕𝐶
𝜕𝑊 𝑖𝑛,1
= 𝑦𝑎 − 𝑦𝑡 [ 𝑤2,4
𝜕
𝜕𝑊 𝑖𝑛,1
σ{𝑧 2
} + 𝑤3,4
𝜕
𝜕𝑊 𝑖𝑛,1
σ{𝑧 3
} ] = 𝑦𝑎 − 𝑦𝑡 [ 𝑤2,4σ{𝑧 2
}
𝜕
𝜕𝑊 𝑖𝑛,1
(σ{𝑧 1
}𝑤1,2)+
𝑤3,4σ{𝑧 3
}
𝜕
𝜕𝑊 𝑖𝑛,1
(σ{𝑧 1
}𝑤1,3) ]
𝜕𝐶
𝜕𝑊 𝑖𝑛,1
= 𝑦𝑎 − 𝑦𝑡 [ 𝑤2,4σ{𝑧 2
}𝑤1,2σ{𝑧 1
}
𝜕
𝜕𝑊 𝑖𝑛,1
(𝑋𝑖𝑛 𝑤𝑖𝑛,1) + 𝑤3,4σ{𝑧 3
} 𝑤1,3 σ{𝑧 1
}
𝜕
𝜕𝑊 𝑖𝑛,1
(𝑋𝑖𝑛 𝑤𝑖𝑛,1) ]
𝜕𝐶
𝜕𝑊 𝑖𝑛,1
= 𝑦𝑎 − 𝑦𝑡 [ 𝑤2,4σ{𝑧 2
}𝑤1,2σ{𝑧 1
} 𝑋𝑖𝑛 + 𝑤3,4σ{𝑧 3
} 𝑤1,3 σ{𝑧 1
}𝑋𝑖𝑛 ]
= (𝑦𝑎 − 𝑦𝑡) 𝑋𝑖𝑛[ σ{𝑧(2)
}[1 − σ{𝑧(2)
}]𝑤2,4 σ{𝑧(1)
}[1 − σ{𝑧(1)
}] 𝑤1,2 + σ{𝑧(3)
}[1 − σ{𝑧(3)
}]𝑤3,4 σ{𝑧(1)
}[1 − σ{𝑧(1)
}]𝑤1,3]
𝑧(1)
𝑧(1)
8](https://image.slidesharecdn.com/backpropagation-180102061746/75/Backpropagation-8-2048.jpg)

![3. Jump to the Backpropagation
3. Error Signals
1-1 Defintion: δ𝒋 =
𝝏𝑪
𝝏𝒁 𝒋
1-2 General Form of Signals
δj =
𝜕C
𝜕Zj
=
𝜕
𝜕Zj
1
2
(𝑦𝑎 − 𝑦𝑡)2
= (𝑦𝑎 − 𝑦𝑡)
𝜕𝑦 𝑎
𝜕𝑍 𝑗
------- ①
𝜕𝑦 𝑎
𝜕𝑍 𝑗
=
𝜕𝑦 𝑎
𝜕𝑎 𝑗
𝜕𝑎 𝑗
𝜕𝑍 𝑗
=
𝜕𝑦 𝑎
𝜕𝑎 𝑗
× σ(𝑧𝑗) (∵ 𝑎𝑗 = σ(𝑧𝑗))
Because neural network consists of Multiple units, we can think all of the units 𝑘 ∈ 𝑜𝑢𝑡𝑠 𝑗 .
So,
𝜕𝑦 𝑎
𝜕𝑍 𝑗
= σ(𝑧𝑗) 𝑘∈𝑜𝑢𝑡𝑠 𝑗
𝜕𝑦 𝑎
𝜕𝑧 𝑘
𝜕𝑧 𝑘
𝜕𝑎 𝑗
𝜕𝑦 𝑎
𝜕𝑍 𝑗
= σ(𝑧𝑗) 𝑘∈𝑜𝑢𝑡𝑠 𝑗
𝜕𝑦 𝑎
𝜕𝑧 𝑘
𝑤𝑗𝑘 (∵ 𝑧 𝑘 = 𝑤𝑗𝑘 𝑎𝑗)
By above equation ① and δk = (𝑦𝑎 − 𝑦𝑡)
𝜕𝑦 𝑎
𝜕𝑍 𝑘
δj = (𝑦𝑎 − 𝑦𝑡) σ(𝑧𝑗) 𝑘∈𝑜𝑢𝑡𝑠 𝑗
𝜕𝑦 𝑎
𝜕𝑧 𝑘
𝑤𝑗𝑘 = (𝑦𝑎 − 𝑦𝑡)σ(𝑧𝑗) 𝑘∈𝑜𝑢𝑡𝑠 𝑗
δk
(𝑦 𝑎−𝑦𝑡)
𝑤𝑗𝑘
∴ δj= σ(𝑧𝑗) 𝑘∈𝑜𝑢𝑡𝑠 𝑗 δk 𝑤𝑗𝑘 , and for starting, we define δ𝑖𝑛𝑖𝑡𝑖𝑎𝑙 = (𝑦𝑎 − 𝑦𝑡)σ{𝑧(𝑖𝑛𝑖𝑡𝑖𝑎𝑙)
}[1 − σ{𝑧(𝑖𝑛𝑖𝑡𝑖𝑎𝑙)
}]
11](https://image.slidesharecdn.com/backpropagation-180102061746/75/Backpropagation-11-2048.jpg)
![3. Jump to the Backpropagation
3. Error Signals
1-3 The General Form of weight variation
( ※ 𝑊3→6,𝑛𝑒𝑤= 𝑊3→6,𝑜𝑙𝑑 − η
𝜕𝐶
𝜕𝑊3→6,𝑜𝑙𝑑
)
( ※ δ6 = δ𝑖𝑛𝑖𝑡𝑖𝑎𝑙 = (𝑦𝑎 − 𝑦𝑡)σ{𝑧(6)
}[1 − σ{𝑧(6)
}] )
∆𝑊3,6 = −η (𝑦𝑎 − 𝑦𝑡)σ{𝑧(6)
}[1 − σ{𝑧(6)
}] 𝑎(3)
= −ηδ6 𝑎(3)
∆𝑊4,6 = −η (𝑦𝑎 − 𝑦𝑡)σ{𝑧(6)
}[1 − σ{𝑧(6)
}] 𝑎(4)
= −ηδ6 𝑎(4)
∆𝑊5,6 = −η (𝑦𝑎 − 𝑦𝑡)σ{𝑧(6)
}[1 − σ{𝑧(6)
}] 𝑎(5)
= −ηδ6 𝑎(5)
∆𝑊1,3 = −η (𝑦𝑎 − 𝑦𝑡)σ{𝑧(6)
}[1 − σ{𝑧(6)
}] 𝑊3,6 σ{𝑧(3)
}[1 − σ{𝑧(3)
}] 𝑎(1)
= −η ( 𝑘∈𝑜𝑢𝑡𝑠 𝑗 δ6) × 𝑤3,6 σ(𝑧3) 𝑎(1)
= −ηδ3 𝑎(1)
………
∴ ∆𝑊𝑖,𝑗= −ηδ𝑗 𝑎(𝑖)
We can easily renew weights by using Error Signals δ and Equation ∆𝑾𝒊,𝒋= −𝜼𝜹𝒋 𝒂(𝒊)
𝑋1
𝑋2
𝑧(1)
| 𝑎(1)
𝑧(2)
| 𝑎(2)
𝑧(3)
| 𝑎(3)
𝑧(4)
| 𝑎(4)
𝑧(5)
| 𝑎(5)
𝑧(6)
| 𝑎(6)
𝑤13 𝑤36
𝑤14
𝑤15
𝑤23
𝑤24
𝑤25
𝑤46
𝑤56
𝑤𝑖𝑛,1
𝑤𝑖𝑛,2
12](https://image.slidesharecdn.com/backpropagation-180102061746/75/Backpropagation-12-2048.jpg)


















































![[Pr12] deep anomaly detection using geometric transformations](https://cdn.slidesharecdn.com/ss_thumbnails/pr12deepanomalydetectionusinggeometrictransformations-190317140121-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Pr12] self supervised gan](https://cdn.slidesharecdn.com/ss_thumbnails/pr12selfsupervisedgan-190119162617-thumbnail.jpg?width=640&height=640&fit=bounds)



![[Probability for machine learning]](https://cdn.slidesharecdn.com/ss_thumbnails/probabilityformachinelearning-180726131331-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DSC Europe 25] Debmalya Biswas - Agentification: the art of transforming man...](https://cdn.slidesharecdn.com/ss_thumbnails/r5azlggvtqiaiiusrqdr-4-251212103249-5a12c89b-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Dunja Adzic Jovanovic - AI and Cybersecurity: Defending Data ...](https://cdn.slidesharecdn.com/ss_thumbnails/o1zylpbhrtwnixxq2xj8-7-251211083048-185086f6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Jon Dajci - Bridging TradFi and DeFi: Building the Future of ...](https://cdn.slidesharecdn.com/ss_thumbnails/fqmhfvlbqhkihjvqvhmu-7-251211083849-6af7e325-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Kaja Kandare - LLM as a judge.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/arxyccaxsdsd1ba99wjw-7-251212104007-2b4e3f64-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Bassam Maharmeh - Artificial Intelligence: Opportunities and ...](https://cdn.slidesharecdn.com/ss_thumbnails/thhfmr2fqpawzj7hsjpg-5-251211083048-2c23204f-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Jovan Bogicevic - Legacy to AI-Driven Defense: Transforming D...](https://cdn.slidesharecdn.com/ss_thumbnails/rsarluadt563hntyfc8q-3-251211083849-3e7bc4c0-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Miodrag Pesovic & Vladislav Radonjic - Federated Data Archite...](https://cdn.slidesharecdn.com/ss_thumbnails/gsbe3y5it5uhndi4e08e-1-251212103249-f1008e0c-thumbnail.jpg?width=640&height=640&fit=bounds)