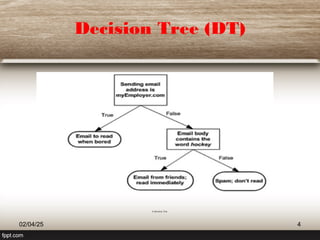
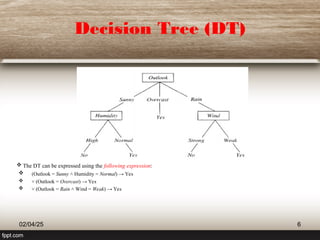
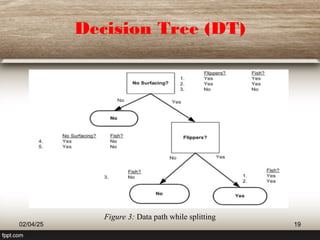
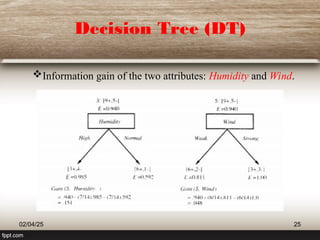
The document provides an extensive overview of decision trees (DT) as a classification technique used in machine learning, detailing their structure, advantages, and limitations. It explains how decision trees utilize information theory for dataset splitting and discusses essential concepts such as entropy and information gain. The document also touches on various algorithms related to decision trees and presents issues surrounding their implementation.