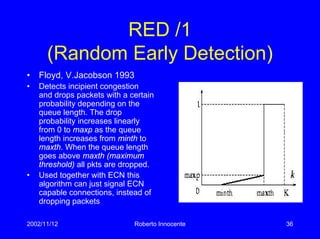
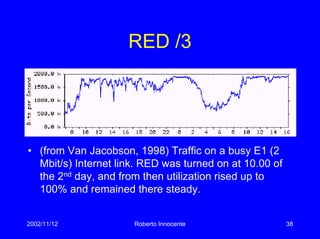
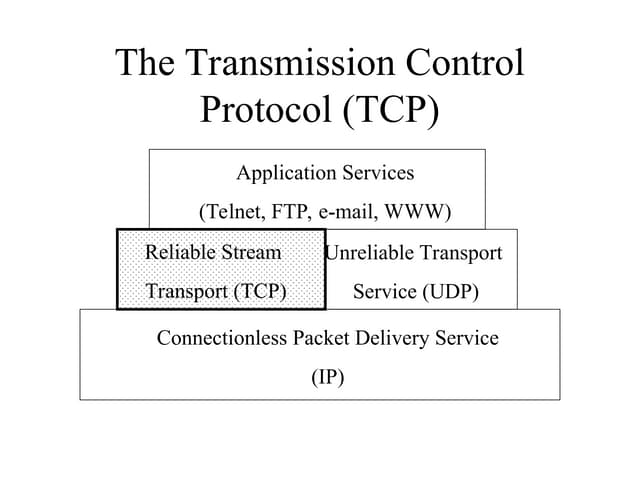
This document discusses transport protocols and how they have been optimized for large data transfers but are not as well suited for the small file transfers that now dominate web traffic. It describes several key aspects of TCP including flow control using a sliding window, congestion control algorithms like slow start and congestion avoidance, and mechanisms for detecting and responding to packet loss like fast retransmit. It notes how TCP was adapted over time, including additions like fast recovery, and alternatives like TCP Vegas which aims to avoid rather than just respond to congestion. The document provides historical context and details on TCP implementations.














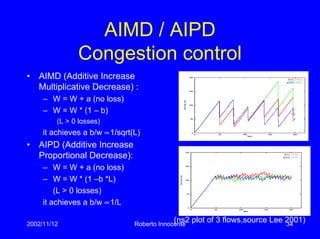
![2002/11/12 Roberto Innocente 14
Congestion control in TCP
from [Balakrishnan 98]](https://image.slidesharecdn.com/innocentetcp-web-160623091146/85/features-of-tcp-important-for-the-web-14-320.jpg)