Downloaded 43 times








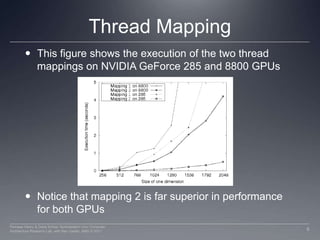




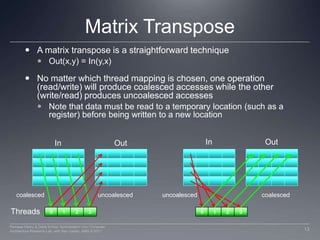
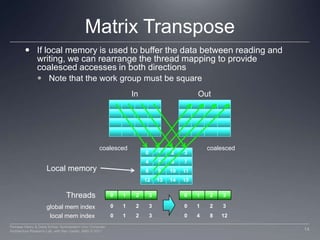








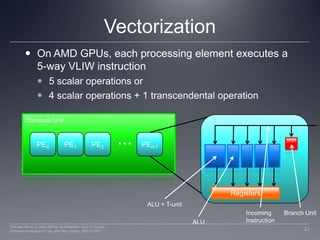

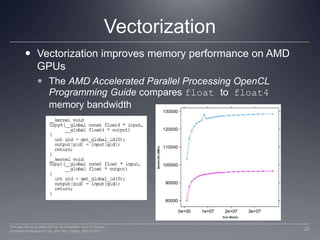


This document discusses three important optimizations for GPU performance: thread mapping, device occupancy, and vectorization. Thread mapping involves assigning threads to data in a way that aligns with hardware and provides efficient memory access. Device occupancy refers to how fully the compute unit resources are utilized. Having enough active threads to hide memory latency impacts performance. Vectorization, or processing multiple data elements with each thread, is particularly important for AMD GPUs. Examples are provided of different thread mappings and how they affect memory access and performance.




























![[Harvard CS264] 11b - Analysis-Driven Performance Optimization with CUDA (Cli...](https://cdn.slidesharecdn.com/ss_thumbnails/analysisdrivenoptimization-110407230024-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 11a - Programming the Memory Hierarchy with Sequoia (Mike Bau...](https://cdn.slidesharecdn.com/ss_thumbnails/analysisdrivenoptimization-110407225811-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)





































