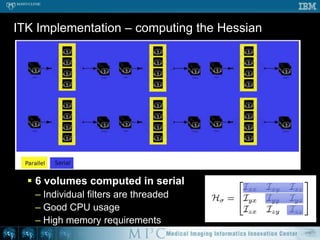
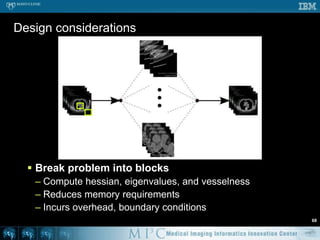
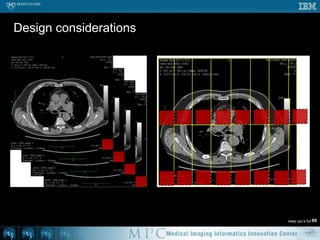
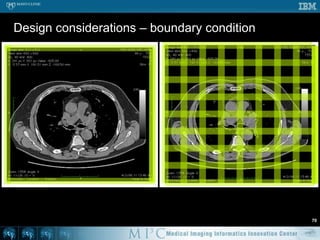
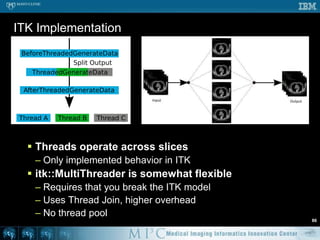
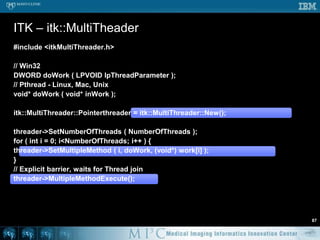
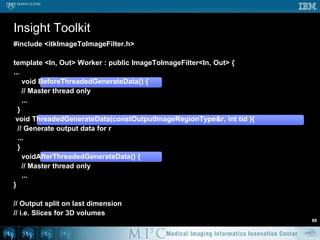
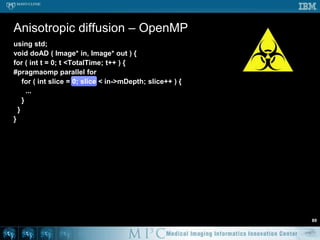
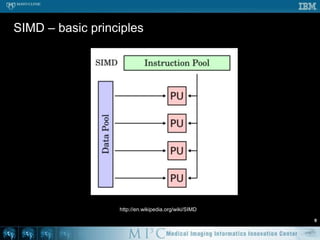
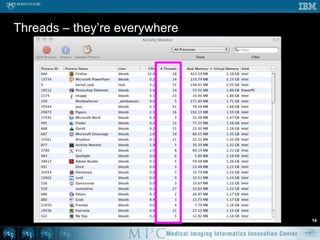
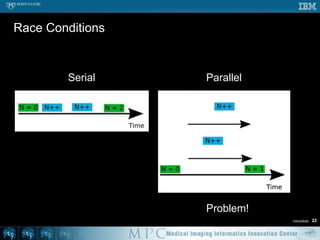
This document discusses various strategies for parallelizing medical image processing tasks across multi-core CPUs. It begins with a poll asking about readers' computer hardware and parallel programming experience. It then covers degrees of parallelism from serial to large-scale parallelism. The document presents pragmatic approaches using C/C++ with "bolted on" parallel concepts. It provides a brief introduction to SIMD and focuses on SMP concepts using threads, concurrency, and parallel programming models like OpenMP, TBB, and ITK. It discusses example problems like thresholding images and common errors. It concludes with next steps in parallel computing.











![Data structures for SIMDArray of Structuresstruct Vec { float x, y, z;};Vec[] points = new Vec[sz];10XYZ--PackXYZ--XYZ--*UnpackXYZ--](https://image.slidesharecdn.com/multicorecpu-090628175313-phpapp01/85/Medical-Image-Processing-Strategies-for-multi-core-CPUs-16-320.jpg)
![Data structures for SIMD 11Structure of Arraysstruct Vec { float[] x; float[] y; float[] z; Vec ( int sz ) { x = new float[sz]; y = new float[sz]; z = new float[sz]; };};Structure of Arraysstruct Vec{ Vector4f[] v; Vec ( int sz ) { // must be word // aligned v = new Vector4f[sz]; };};](https://image.slidesharecdn.com/multicorecpu-090628175313-phpapp01/85/Medical-Image-Processing-Strategies-for-multi-core-CPUs-17-320.jpg)






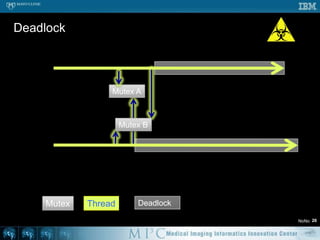
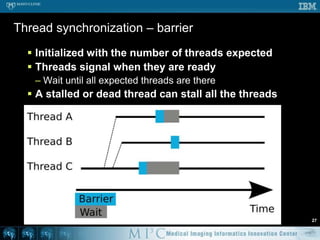
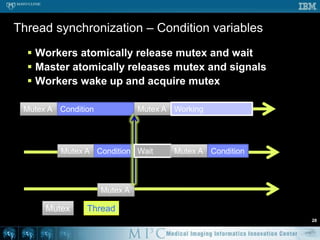
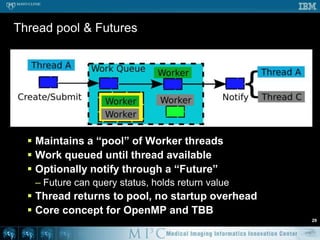











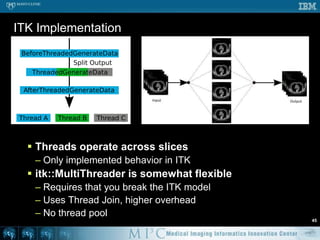


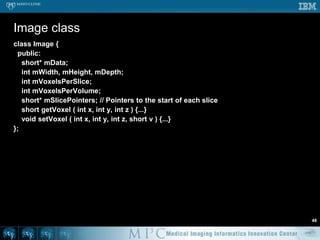

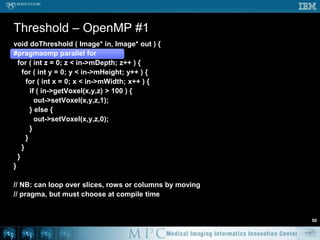
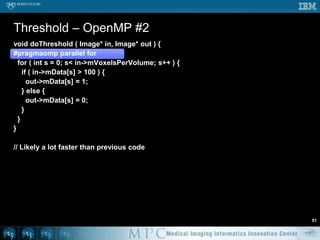

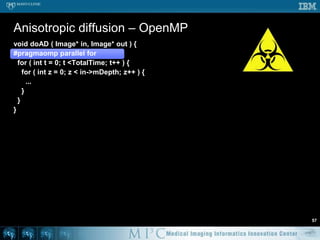
![Threshold – OpenMP #251void doThreshold ( Image* in, Image* out ) {#pragmaomp parallel for for ( int s = 0; s < in->mVoxelsPerVolume; s++ ) { if ( in->mData[s] > 100 ) { out->mData[s] = 1; } else { out->mData[s] = 0; } }}// Likely a lot faster than previous code](https://image.slidesharecdn.com/multicorecpu-090628175313-phpapp01/85/Medical-Image-Processing-Strategies-for-multi-core-CPUs-58-320.jpg)
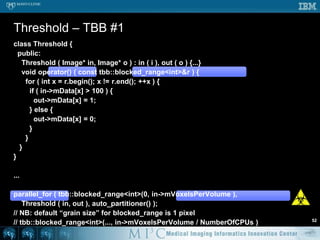
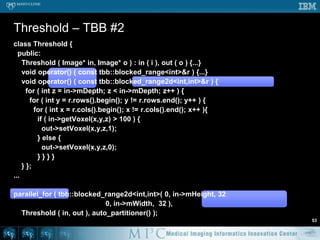
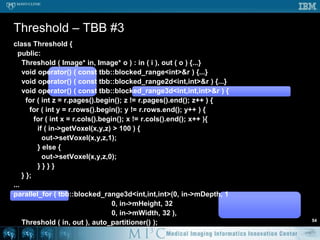
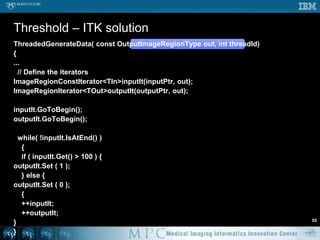
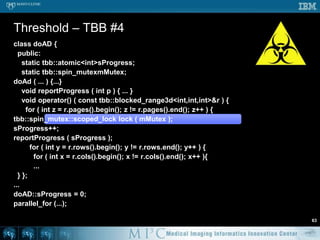
![class Threshold { public: Threshold ( Image* in, Image* o ) : in ( i ), out ( o ) {...} void operator() ( const tbb::blocked_range<int>& r ) { for ( int x = r.begin(); x != r.end(); ++x ) { if ( in->mData[x] > 100 ) { out->mData[x] = 1; } else { out->mData[x] = 0; } } }}...parallel_for ( tbb::blocked_range<int>(0, in->mVoxelsPerVolume ), Threshold ( in, out ), auto_partitioner() );// NB: default “grain size” for blocked_range is 1 pixel// tbb::blocked_range<int>(..., in->mVoxelsPerVolume / NumberOfCPUs )Threshold – TBB #152](https://image.slidesharecdn.com/multicorecpu-090628175313-phpapp01/85/Medical-Image-Processing-Strategies-for-multi-core-CPUs-59-320.jpg)
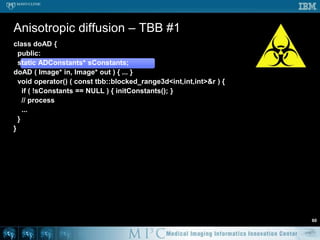
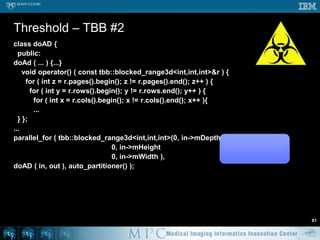
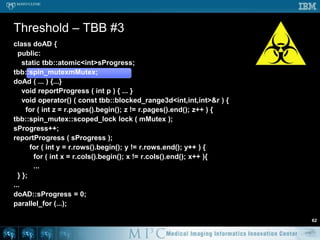
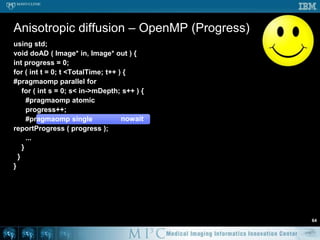
![Anisotropic diffusion – OpenMP58void doAD ( Image* in, Image* out ) { short *previousSlice, *slice, *nextSlice; for ( int t = 0; t < TotalTime; t++ ) {#pragmaomp parallel for for ( int z = 1; z < in->mDepth-1; z++ ) {previousSlice = in->mSlicePointers[z-1]; slice = in->mSlicePointers[z];nextSlice = in->mSlicePointers[z+1]; for ( int y = 1; y < in->mHeight-1; y++ ) { short* previousRow = slice + y-1 * in->mWidth; short* row = slice + y * in->mWidth; short* nextRow = slice + y-1 * in->mWidth; short* aboveRow = previousSlice + y * in->mWidth; short* belowRow = nextSlice + y * in->mWidth; for ( int x = 1; i < in->mWidth-1; x++ ) {dx = 2 * row[x] – row[x-1] – row[x+1];dy = 2 * row[x] – previousRow[x] – nextRow[x];dz = 2 * row[x] – aboveRow[x] – belowRow[x]; ...](https://image.slidesharecdn.com/multicorecpu-090628175313-phpapp01/85/Medical-Image-Processing-Strategies-for-multi-core-CPUs-65-320.jpg)
![Anisotropic diffusion – OpenMP59void doAD ( Image* in, Image* out ) { for ( int t = 0; t < TotalTime; t++ ) {#pragmaomp parallel for for ( int z = 1; z < in->mDepth-1; z++ ) { short* previousSlice = in->mSlicePointers[z-1]; short* slice = in->mSlicePointers[z]; short* nextSlice = in->mSlicePointers[z+1]; for ( int y = 1; y < in->mHeight-1; y++ ) { short* previousRow = slice + y-1 * in->mWidth; short* row = slice + y * in->mWidth; short* nextRow = slice + y-1 * in->mWidth; short* aboveRow = previousSlice + y * in->mWidth; short* belowRow = nextSlice + y * in->mWidth; for ( int x = 1; i < in->mWidth-1; x++ ) {dx = 2 * row[x] – row[x-1] – row[x+1];dy = 2 * row[x] – previousRow[x] – nextRow[x];dz = 2 * row[x] – aboveRow[x] – belowRow[x]; ...](https://image.slidesharecdn.com/multicorecpu-090628175313-phpapp01/85/Medical-Image-Processing-Strategies-for-multi-core-CPUs-66-320.jpg)