Downloaded 51 times













![Warp Voting for Histogram256Build per warp subhistogramCombine to per work group subhistogramLocal memory budget in per warp sub histogram technique allows us to have multiple work groups activeHandle conflicting writes by threads within a warp using warp votingTag writes to per warp subhistogram with intra-warp thread IDThis allows the threads to check if their writes were successful in the next iteration of the while loopWorst case : 32 iterations done when all 32 threads write to the same bin32 bit Uint5 bit tag27 bit tagvoid addData256( volatile __local uint * l_WarpHist, uint data, uintworkitemTag) { unsigned intcount; do{ // Read the current value from histogram count = l_WarpHist[data] & 0x07FFFFFFU; // Add the tag and incremented data to // the position in the histogram count = workitemTag | (count + 1);l_WarpHist[data] = count; } // Check if the value committed to local memory // If not go back in the loop and try againwhile(l_WarpHist[data] != count);}Source: Nvidia GPU Computing SDK Examples16Perhaad Mistry & Dana Schaa, Northeastern Univ Computer Architecture Research Lab, with Ben Gaster, AMD © 2011](https://image.slidesharecdn.com/lec07threadinghw-110829103056-phpapp01/85/Lec07-threading-hw-16-320.jpg)




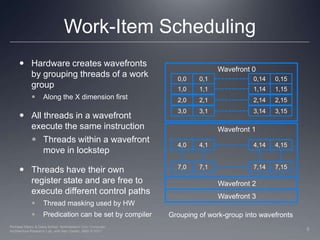
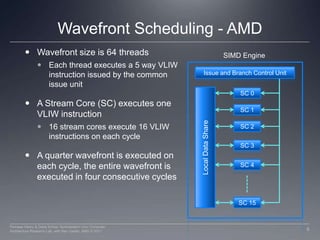
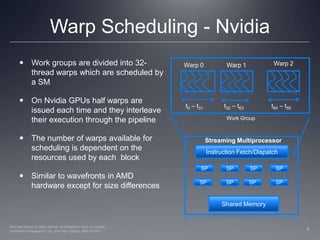
This document discusses how work groups are scheduled for execution on GPU compute units. It explains that work groups are broken down into hardware schedulable units known as warps or wavefronts. These group threads together and execute instructions in lockstep. The document covers thread scheduling, effects of divergent control flow, predication, warp voting, and optimization techniques like maximizing occupancy.










































































