Download to read offline



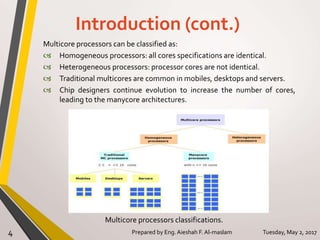









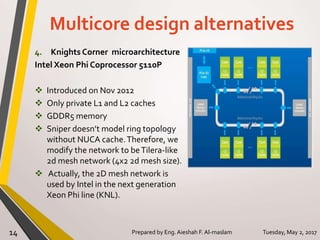
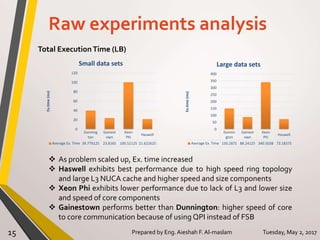

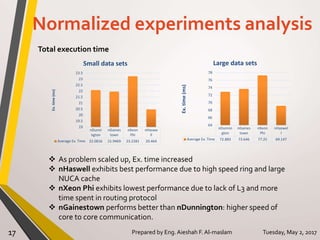


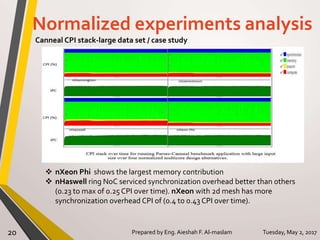

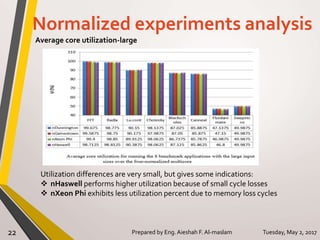
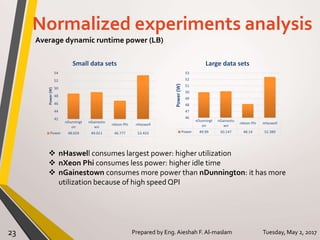
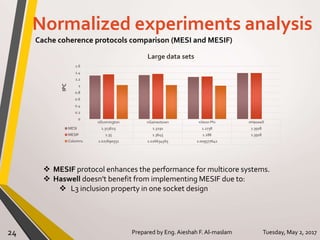





The document presents a thesis on the evaluation of various multicore design alternatives using configuration-dependent analysis, focusing on performance metrics, simulation methodologies, and comparisons of different microarchitectures. It discusses key aspects like execution time, cache coherence protocols, and power consumption, revealing that Haswell architecture outperformed others despite higher power usage. The research highlights the importance of understanding multicore systems in the context of evolving application demands and suggests areas for future investigation.























































![Attack surfaces and attack tress[inform]](https://cdn.slidesharecdn.com/ss_thumbnails/lecture03-260108015941-a4dee53b-thumbnail.jpg?width=640&height=640&fit=bounds)











